本連載について
本連載では、従来型データベース(SQLまたはNoSQL)のデータを、分析ワークロード向けにプラットフォーム非依存のデータレイク(人によってはデータレイクハウスとも呼ぶもの)へ複製する方法を解説します。理論上のアーキテクチャの提示から始め、フレームワークを組み立て、最後にPostgresデータベースを使った実装例まで取り上げます。
本連載のきっかけは、複数のお客様のPostgresデータベースからIcebergテーブルへデータを移し、BIツールでクエリできるようにする支援を立て続けに行ったことです。同じテーマで何度もセッションを重ねるうちに、わかりやすい手順書が見当たらないと気づき、これは書き残しておくべきだと考えました。
さらに、本連載では完全にオープンソースのソフトウェアと、各クラウドベンダーが標準で提供するサービスのみを使用します。これにより、可能な限りクラウドプラットフォームに依存しない構成を目指します。
それでは、さっそく本題に入りましょう。
想定シナリオ
トランザクションデータが1つまたは複数の従来型データベースに分散し、クリティカルマスに達しつつある状況です。データチームはデータが複数箇所に分散し、用途に合わせた変換も行われていないため、業務に支障をきたし始めています。さらに、既存のデータベースでは対応できない分析ワークロード向けに、データウェアハウスの導入も検討しています。
加えてデータチームからは、今後の事業成長によりこの問題がいっそう深刻化する見通しが示されており、データを変換してデータウェアハウスへ格納し始めるべきタイミングが来ています。
そこでGoogle BigQuery、Snowflake、Databricks、DuckDB、ClickHouse、Redshiftといった有名どころを検討しているものの、選択肢の多さに圧倒され、できればプラットフォームに依存しない判断を下したい——そうお考えではないでしょうか。
もし思い当たるなら、朗報です。このまま読み進めてください。
当てはまらない方でも、プラットフォーム非依存のデータウェアハウス(厳密にはデータレイク)の構築方法に興味があれば、ぜひ続けてお読みください。
アーキテクチャの全体像
本連載では、従来型のRDBMSデータベースから、クラウドプロバイダーのBLOBストレージ上にApache Iceberg形式で構築したデータレイクへデータを移し、データウェアハウスシステムが日常運用で活用できるようにするためのリファレンスアーキテクチャと実装サンプルを紹介します。
リファレンスアーキテクチャは非常にシンプルで、おおよそ次のとおりです。
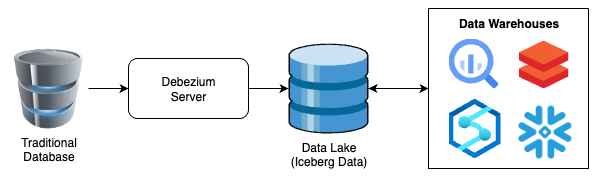
予想される(そして実際にそうなる)とおり、現実にはこれよりずっと多くの要素が絡みますが、このシンプルな図はこのプロセスの強力さと、それによって得られるプラットフォーム非依存性をよく表しています。
また本記事では、生データを変換せずIcebergテーブルへ複製する、極めてシンプルな構成を扱います。記事をわかりやすく保つための意図的な選択です。ETLの「T」(Transform)を組み込むための実装方法やポイントについては、後続パートで触れていきます。本記事ではまず、KISSの原則(Keep It Simple, Stupid)に従いましょう。
パズルのピース
ここでは、本記事で紹介するサンプルシステムを構成する各要素を取り上げて定義を整理するとともに、よく耳にするモダンなバズワードについて、本記事での意味づけもあわせて示します。
Traditional(従来型データベース)
アプリケーションが利用するデータベースシステムを指します。一般的にはトランザクション処理(購入、ページのクリック、監査ログなど)やアプリケーションデータの保存に用いられます。
従来型のリレーショナルデータベースに馴染みがある方なら、これはおおむねOLTP(Online Transaction Processing)と呼ばれるカテゴリのデータベースに該当します。要は、トランザクション処理を非常に得意とするデータベースという意味です。代表例はMySQL、Microsoft SQL Server、PostgreSQL、MariaDB、Oracle Database、IBM DB2など。他にも数え切れないほど存在しますが、現在も主流なのはこのあたりです。
非リレーショナル(NoSQL)系の世界から来た方には、いくつかの選択肢があります。Debeziumがサポートしているものであれば動作します。本稿執筆時点では、MongoDB、Cassandra、Google Spanner、そしてこれらをデータソースとして利用できる互換レイヤーを備えた製品が対象です。
Data Warehouse(データウェアハウス)
クエリ実行や分析処理を担う製品です。これはおおむねOLAP(Online Analytics Processing)と呼ばれるクラスのデータベースに該当します。要は、分析ワークロードや分析処理を非常に得意とするデータベースという意味です。代表例はGoogle BigQuery、Snowflake、Databricks、DuckDb、ClickHouse、Amazon Redshift、Microsoft Azure Synapseなど。
注:本記事の文脈では、データウェアハウスはコンピュート用途のみで利用し、ストレージ用途では使いません。そのため、ストレージ面の詳細には踏み込んでいません。
Data Lake(データレイク)
利用対象となる生データをすべて保管する場所であり、変換結果を書き込み、その後の分析処理で読み込むための場所でもあります。
多くの場合、ファイル形式が混在した寄せ集めの状態になっていますが、Apache Icebergのような単一形式に標準化することを強くお勧めします。データレイクのストレージ形式を標準化するために生まれたのが、Icebergやその同類のフォーマットなのです。
データレイクは多くの場合、BLOB(Binary Large OBject)ストレージと呼ばれるクラスのストレージデバイス上に構築されます。簡単に言えば、クラウド環境(または一部のオンプレミスデータセンター)上に存在する、ほぼ無限の容量を持つハードドライブです。
代表例はAWS Simple Storage Service(S3)、Google Cloud Storage、Azure Blob Storage、Oracle Object Storage、Digital Ocean Spaces Object Storeなどです。
Apache Iceberg
Apache Icebergは、変化の遅いデータ(つまりデータウェアハウス向けのデータ)をBLOBストレージ上に保存するのに非常に適したデータ格納形式で、分析データベースがあたかもネイティブのストレージ形式で保存されているかのようにシームレスにクエリ・操作できるようにします。データレイクに共通フォーマットをもたらすことで、データプラットフォーム非依存性(少なくとも現時点で実現可能な限り近い状態)を達成します。
なお、Icebergは分析クエリには非常に優れている一方、トランザクション系ワークロードへの利用は強くお勧めしません。Fivetranが公開しているこちらの記事では、行指向データベースと列指向データベースの基本が解説されており、その理由に直接つながる内容となっています。
実際にはもっと複雑な話ですが、これが最もシンプルな説明です。完全な機能リストやさらに詳しい情報については、公式ドキュメントをご覧になることをお勧めします。
なぜ必要なのか?
現代では、データウェアハウスの選択肢は実に豊富です。少し挙げるだけでも、BigQuery、ClickHouse、Snowflake、Databricks、DuckDB、Redshift、Firebolt、Synapse Analyticsなどがあります。
これらのデータウェアハウスは、デフォルトではそれぞれ独自のプロプライエタリ形式でデータを保存します。つまり、その製品にロックインされ、特定のクラウド専用の製品であれば、そのクラウドにもロックインされてしまうのです。さらに、保存されたデータはサイロ化し、競合する他のデータウェアハウスや、そのプラットフォームに紐づかないツールから読み込むことができなくなります。
だからこそ、複数のプラットフォームやツールから読み込める共通フォーマットでデータを保存することが、結果的に大きな利点となります。
このシナリオは、数年前に実際に起きた出来事に基づいた実話でもあります。仮に明日、ベンダーXが価格を2倍以上に引き上げ、90日後に新価格が完全適用されると通告してきたとしても、移行において最も大変なステップの一つであるストレージ部分はすでに片付いていることになります。心配すべきはデータウェアハウスのコンピュート部分だけで済み、エコシステム全体を移行する必要はありません。
共通フォーマットを使うもう一つの、あまり語られないメリットは、データチームのコスト削減です。十分に話題に上らない点ですが、データチームが単一の環境で単一のデータ形式を扱えるようになれば、複雑さは大幅に減り、実装までの時間も短縮されます。最終的にはこれもコストに跳ね返ってくる話で、要するに、チームが早く実装できればできるほど、チーム全体のコストは下がるのです。
具体的な仕組み
実装例は第2回で紹介しますが、ここではその概要を簡単に説明します。
データウェアハウスのネイティブ形式でデータを保存する代わりに、共通フォーマット(本記事ではApache Iceberg)で、論理的なパーティション構成に分割された共通のストレージバケット上にデータを保存します。こうすることで、唯一の信頼できる情報源(Single Source of Truth)を一箇所に持てます。
この単一の情報源はデータウェアハウスツールから直接クエリされ、変更内容は同じフォーマットの新しいテーブルに反映されます。シンプルさを保ち、プロプライエタリなソリューションに起因する多くの複雑さを回避できる、循環するサイクルです。
情報源の保存場所もフォーマットも一つに統一されているため、複雑さの多くがインフラ側へと抽象化され、プラットフォームではなくデータそのものに集中できるようになります。
第2回の予告
本連載の第2回では、データウェアハウスの基盤として、従来型データベースからIcebergテーブルへデータを複製する具体的な実装方法に踏み込んでいきます。
DoiTのアプローチ
DoiT Internationalでは、こうした課題に日々取り組んでおり、データプロジェクトの実装にあたってコストを抑える方法について、私自身もよくご相談を受けます。
プロジェクトを最も効果的かつコスト効率の高い方法で実装できるよう支援することは、お客様に対する私たちのミッションの一部です。今回のようなケースへの対応から、お客様にとって最適なFinOpsソリューションの提供まで、あらゆることを手がけています。少々身びいきかもしれませんが、私たちはこれを「とても」上手にこなしている自負があります。