La serie
Esta es una serie de artículos sobre cómo replicar los datos de tu base de datos tradicional (SQL o NoSQL) hacia un data lake independiente de la plataforma (o data lakehouse, según a quién le preguntes) para tus workloads más analíticos. A lo largo de la serie voy a mostrar la arquitectura teórica, armar el framework necesario y, por último, dar un ejemplo real de cómo implementarlo desde una base de datos Postgres.
La idea de esta serie surgió mientras ayudaba a varios clientes, uno tras otro, a llevar los datos de sus bases Postgres a tablas Iceberg para consultarlas desde sus herramientas de BI. Después de repetir el mismo tema en varias sesiones, decidí que valía la pena dejarlo por escrito, ya que no encontré una buena guía paso a paso al respecto.
Como bonus, voy a usar exclusivamente software open-source y servicios estándar de los proveedores de nube, así que va a ser lo más independiente posible de la plataforma cloud.
¡Ahora sí, manos a la obra!
El escenario
Estás llegando a un punto crítico en el que tus datos transaccionales viven en una o varias bases de datos tradicionales, y tu equipo de datos empieza a tener problemas para hacer su trabajo porque la información está repartida en varios lugares y no está transformada para sus necesidades. Además, están considerando usar un data warehouse para sus workloads analíticos, que no va a funcionar bien con las bases de datos actuales.
Tu equipo de datos también te está mostrando que el crecimiento se va a acelerar, lo que agrava aún más el problema; así que ahora es el momento de empezar a transformar tus datos y almacenarlos en un data warehouse.
Entonces miras los grandes nombres del mercado, como Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse y Redshift, pero te abruma la cantidad de opciones y quieres tomar una decisión que te permita mantenerte independiente de la plataforma.
Si esto te suena familiar, tengo buenas noticias: ¡sigue leyendo!
Y si no estás en esta situación, pero te interesa aprender más sobre cómo crear un data warehouse (o, técnicamente, un data lake) independiente de la plataforma, sigue leyendo igual.
La arquitectura (abstracta)
En esta serie voy a mostrar una arquitectura de referencia y un ejemplo de implementación para llevar datos desde una base de datos RDBMS tradicional a un data lake en el almacenamiento BLOB de un proveedor de nube en formato Apache Iceberg, que luego un sistema de data warehouse puede aprovechar para sus operaciones del día a día.
La arquitectura de referencia es muy simple y se ve más o menos así:
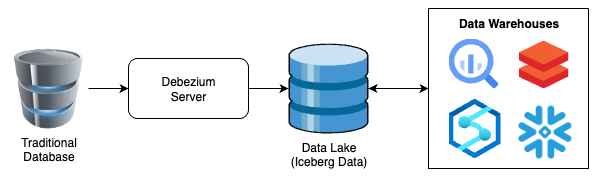
Como puede (y suele) anticiparse, hay mucho más detrás de todo esto, pero este diagrama tan simple muestra la potencia del proceso y también la independencia de plataforma que se logra con él.
Esta también va a ser la versión súper simple, replicando datos en crudo a una tabla Iceberg sin transformaciones. Lo hago así a propósito, para mantener la simpleza del artículo. Voy a dejar notas sobre cómo y dónde implementar mejoras para sumar la T del ETL en partes posteriores de la serie, pero por ahora vamos a Keep It Simple, Stupid.
Las piezas de este rompecabezas
Voy a repasar cada una de las piezas del sistema de ejemplo para definirlas, y también explicar cómo voy a usar algunos de los buzzwords modernos que andan dando vueltas.
Tradicional
Es el sistema de base de datos que utilizan tus aplicaciones. Por lo general se usa para cosas como transacciones (compras, clics en una página, registros de auditoría, etc.) o para guardar datos de la aplicación.
Si vienes del mundo de las bases de datos relacionales tradicionales, esto probablemente caiga dentro de una clase de base de datos llamada Online Transaction Processing (OLTP), que en el fondo es una manera elegante de decir que maneja muy bien las transacciones. Algunos ejemplos son MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Oracle Database e IBM DB2. Hay muchísimas más, pero estas son las principales que siguen vigentes hoy.
Si vienes del mundo no relacional o NoSQL, hay varias opciones distintas. Mientras esté soportada por Debezium, va a funcionar. Al momento de escribir esto, esa lista incluye MongoDB, Cassandra, Google Spanner y cualquier cosa que tenga una capa de compatibilidad para usarse como fuente de datos.
Data Warehouse
Es el producto que se encarga de las consultas y el procesamiento analítico. Probablemente caiga dentro de una clase de base de datos llamada OLAP u Online Analytics Processing (OLAP), que en esencia es una forma elegante de decir que maneja muy bien los workloads y procesos analíticos. Ejemplos: Google BigQuery, Snowflake, Databricks, DuckDb, ClickHouse, Amazon Redshift y Microsoft Azure Synapse.
Nota: en el contexto de este artículo solo uso el data warehouse para la parte de cómputo, no para almacenamiento. Por eso no entré en detalle sobre eso.
Data Lake
Es el lugar donde guardas todos tus datos en crudo para consumirlos y donde escribes los resultados de las transformaciones que luego se leerán para tus procesos analíticos.
Muchas veces termina siendo una mezcolanza de formatos de archivo, pero te recomiendo ENFÁTICAMENTE estandarizar en un único formato como Apache Iceberg. Esa es una de las razones principales por las que se crearon Iceberg y sus pares: ayudar a estandarizar los formatos de almacenamiento de los data lakes.
Un data lake suele vivir sobre una clase de dispositivos de almacenamiento llamados BLOB (siglas de Binary Large OBject). En términos más simples, es un disco duro de tamaño casi infinito que vive en un entorno cloud (o en algunos sistemas de data center on-premise).
Algunos de los ejemplos más comunes son AWS Simple Storage Service (S3), Google Cloud Storage, Azure Blob Storage, Oracle Object Storage o Digital Ocean Spaces Object Store.
Apache Iceberg
Apache Iceberg es un formato de almacenamiento de datos que funciona muy bien para guardar datos que cambian lentamente (es decir, datos al estilo data warehouse) en dispositivos de almacenamiento BLOB, y permite que las bases de datos analíticas los consulten e interactúen con ellos sin fricción, como si estuvieran almacenados nativamente en el formato propio de esa base de datos. Funciona como un formato común para los data lakes y permite alcanzar la independencia de la plataforma de datos, o al menos lo más cerca de eso a lo que se puede llegar hoy.
Vale la pena mencionar que Iceberg es excelente para consultas analíticas, pero desaconsejo ROTUNDAMENTE usarlo para workloads transaccionales. Fivetran tiene este artículo, que cubre los conceptos básicos de bases de datos por filas frente a columnares, y se relaciona directamente con el porqué de esto.
Es bastante más complejo que eso, pero esta es la explicación más simple. Si quieres conocer la lista completa de funcionalidades y más, te recomiendo leer la documentación oficial aquí.
¿Por qué?
Hoy en día hay MUCHAS opciones en el terreno del data warehousing; por nombrar solo algunas: BigQuery, ClickHouse, Snowflake, Databricks, DuckDB, Redshift, Firebolt y Synapse Analytics.
Cada uno de estos data warehouses, por defecto, usa su propio formato propietario para almacenar los datos, lo que significa que quedas atado a ellos, y algunos están atados a la nube en la que son exclusivos. Esto también implica que los datos quedan en silos y no pueden ser leídos por otros data warehouses competidores ni por otras herramientas que no estén ligadas a esa plataforma.
Por eso, te conviene almacenar los datos en un formato común que puedan leer múltiples plataformas o herramientas.
Este escenario es además una historia real, basada en hechos de hace algunos años. Si mañana el proveedor X duplica (o más) sus precios y te da 90 días para que esos nuevos costos se hagan efectivos, entonces uno de los pasos de migración más grandes ya está resuelto: el almacenamiento. Solo tendrías que preocuparte por la parte de cómputo de tu data warehouse, en lugar de todo el ecosistema.
El otro beneficio del que poco se habla al usar un formato común es la reducción de costos del equipo de datos. Es algo que no se menciona lo suficiente, pero si tu equipo de datos cuenta con un único formato con el cual trabajar en un único entorno, eso reduce muchísimo la complejidad y el tiempo hasta la implementación. Todo termina volviendo al costo: en resumen, cuanto más rápido pueda implementar el equipo, menor será el costo total.
¿Cómo?
En la Parte 2 voy a mostrar un ejemplo de cómo implementar esto, pero aquí va una visión general de cómo se ve.
En lugar de almacenar los datos en el formato nativo de tu data warehouse, los vas a almacenar en un formato común (en este caso, Apache Iceberg) dentro de un bucket de almacenamiento común dividido por un esquema de particionamiento lógico. Así tendrás una única fuente de verdad en una única ubicación.
Como única fuente de verdad, las herramientas de data warehouse la consultan directamente, y los cambios se reflejan en nuevas tablas en este mismo formato. Es un ciclo que mantiene las cosas simples y evita muchas de las complejidades que vienen con las soluciones propietarias.
Como hay una única ubicación y un único formato para esta fuente de verdad, gran parte de las complejidades quedan abstraídas en la infraestructura, lo que te permite enfocarte en los datos en lugar de en la plataforma.
Próximamente en la Parte 2
En la Parte 2 de esta serie voy a entrar en detalle sobre cómo implementar la replicación de datos desde una base de datos tradicional hacia una tabla Iceberg como base de un data warehouse.
How We DoiT
En DoiT International nos enfrentamos a problemas como este todo el tiempo, y siempre me preguntan por maneras de ahorrar dinero al implementar proyectos de datos.
Ayudar a implementar proyectos de la manera más efectiva y costo-eficiente es parte de nuestra misión con los clientes. Atender desde casos como estos hasta entregar las mejores soluciones de FinOps para nuestros clientes es a lo que nos dedicamos y, aunque quizá sea un poco parcial al decirlo, lo hacemos al máximo nivel.