La serie
Questa è una serie di articoli dedicata alla replica dei dati da un database tradizionale (SQL o NoSQL) verso un data lake (o data lakehouse, a seconda dei punti di vista) indipendente dalla piattaforma, pensato per i workloads a vocazione analitica. Lungo il percorso illustrerò l'architettura teorica, costruirò il framework di riferimento e, per concludere, mostrerò un esempio reale di implementazione a partire da un database Postgres.
L'idea per questa serie è nata mentre aiutavo, uno dopo l'altro, alcuni clienti a portare i dati dai loro database Postgres in tabelle Iceberg, da interrogare poi con i propri strumenti di BI. Dopo diverse sessioni sullo stesso argomento, ho deciso che valeva la pena metterlo nero su bianco, anche perché non sono riuscito a trovare una guida passo-passo davvero ben fatta.
Come bonus, userò esclusivamente software open-source e servizi pronti all'uso dei vendor cloud, così da restare il più possibile cloud-agnostic.
E ora bando alle ciance: si parte!
Lo scenario
State raggiungendo la massa critica: i dati transazionali risiedono in uno o più database tradizionali e il team Data inizia a faticare nel proprio lavoro, perché i dati sono sparsi in più sistemi e non sono trasformati in base alle sue esigenze. In aggiunta, sta valutando di adottare un data warehouse per i workloads analitici, soluzione però non compatibile con i database esistenti.
Lo stesso team segnala anche che la crescita sta accelerando, aggravando ulteriormente il problema: è arrivato il momento di iniziare a trasformare i dati e a memorizzarli in un data warehouse.
Vi guardate intorno e vedete i grandi nomi del settore — Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse, Redshift — ma siete sopraffatti dalle alternative e vorreste fare una scelta che vi mantenga indipendenti dalla piattaforma.
Se la situazione vi suona familiare, ho una buona notizia: continuate a leggere!
E se non vi ci ritrovate, ma volete capire meglio come costruire un data warehouse (o, più precisamente, un data lake) indipendente dalla piattaforma, leggete comunque: ne vale la pena.
L'architettura (astratta)
In questa serie illustrerò un'architettura di riferimento e un'implementazione di esempio per spostare i dati da un database RDBMS tradizionale a un data lake sullo storage BLOB di un cloud provider, in formato Apache Iceberg, in modo che un sistema di data warehouse possa poi sfruttarli per le operazioni quotidiane.
L'architettura di riferimento è molto semplice e si presenta più o meno così:
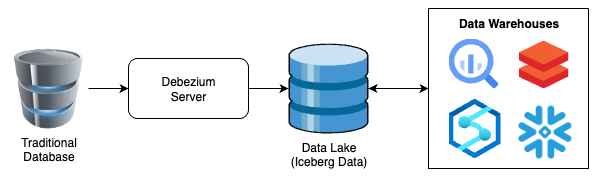
Come prevedibile (e come di solito accade), dietro c'è molto di più, ma questo schema essenziale rende bene l'idea della potenza del processo e dell'indipendenza dalla piattaforma che si può raggiungere.
Sarà inoltre la versione super-semplificata: replicheremo i dati grezzi su una tabella Iceberg senza trasformazioni. È una scelta voluta, per mantenere lineare l'articolo. Nelle parti successive segnalerò come e dove introdurre miglioramenti per aggiungere la T di ETL; per ora, però, atteniamoci al principio Keep It Simple, Stupid.
I pezzi del puzzle
Passerò in rassegna ogni componente del sistema di esempio per definirne il ruolo e chiarire il significato che attribuirò ad alcune delle parole d'ordine più di moda.
Tradizionale
È il sistema di database utilizzato dalle vostre applicazioni. In genere serve a gestire transazioni (acquisti, click sulle pagine, voci di audit, ecc.) o a memorizzare dati applicativi.
Se venite dal mondo dei database relazionali tradizionali, ricadrà probabilmente nella categoria detta Online Transaction Processing (OLTP) — un modo elegante per dire che gestisce molto bene le transazioni. Esempi tipici sono MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Oracle Database e IBM DB2. Ce ne sono innumerevoli altri, ma questi sono i principali ancora oggi diffusi.
Se invece arrivate dal mondo non relazionale, o NoSQL, le opzioni possono variare. Purché sia supportato da Debezium, andrà bene. Al momento in cui scrivo, l'elenco comprende MongoDB, Cassandra, Google Spanner e qualsiasi soluzione che disponga di un layer di compatibilità per essere utilizzata come sorgente dati.
Data Warehouse
È il prodotto che esegue per voi le query e l'elaborazione analitica. Probabilmente ricadrà nella categoria dei database OLAP, Online Analytics Processing — un altro modo elegante per dire che gestisce molto bene workloads e processi analitici. Tra gli esempi: Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse, Amazon Redshift e Microsoft Azure Synapse.
Nota: nel contesto di questo articolo userò il data warehouse solo per la parte di compute, non per lo storage. Ecco perché non sono entrato nel dettaglio.
Data Lake
È il luogo in cui memorizzate tutti i dati grezzi destinati al consumo, oltre che lo spazio in cui scrivete i risultati delle trasformazioni che verranno poi letti dai vostri processi analitici.
Spesso si finisce per avere un mix disomogeneo di formati di file, ma vi consiglio VIVAMENTE di standardizzare su un unico formato come Apache Iceberg. È uno dei motivi principali per cui Iceberg e i suoi simili sono nati: aiutare a standardizzare i formati di archiviazione dei data lake.
Un data lake risiede di solito su una categoria di dispositivi di archiviazione chiamati storage BLOB (acronimo di B inary L arge OB ject). In termini più semplici, è un disco dalle dimensioni quasi infinite che vive in un ambiente cloud (o in alcuni data center on-premise).
Tra gli esempi più diffusi: AWS Simple Storage Service (S3), Google Cloud Storage, Azure Blob Storage, Oracle Object Storage o Digital Ocean Spaces Object Store.
Apache Iceberg
Apache Iceberg è un formato di archiviazione che funziona molto bene per memorizzare dati a lenta variazione (cioè dati tipici di un data warehouse) su dispositivi di storage BLOB, permettendo ai database analitici di interrogarli e interagirvi in modo trasparente, come se fossero salvati nel formato nativo di quel database. Funge da formato comune per i data lake, consentendo di raggiungere l'indipendenza dalla piattaforma dati — o quanto meno di avvicinarvisi il più possibile, allo stato attuale.
Va sottolineato che Iceberg è eccellente per le query analitiche, ma ne sconsiglio VIVAMENTE l'uso per workloads transazionali. Fivetran ha pubblicato un articolo che illustra le basi del confronto tra database a righe e database a colonne, direttamente collegato al perché di questa raccomandazione.
La questione è ben più articolata, ma questa è la spiegazione più sintetica. Se volete conoscere l'elenco completo delle funzionalità e altro ancora, vi consiglio di leggere la documentazione ufficiale qui.
Il perché
Oggi le scelte sul fronte del data warehousing sono MOLTE; per citarne solo alcune: BigQuery, ClickHouse, Snowflake, Databricks, DuckDB, Redshift, Firebolt e Synapse Analytics.
Ognuno di questi data warehouse, per impostazione predefinita, utilizza un proprio formato proprietario per memorizzare i dati: questo significa che vi legate a essi, e in alcuni casi anche al cloud su cui sono esclusivi. Significa anche che i dati restano isolati e non possono essere letti da data warehouse concorrenti o da altri strumenti non vincolati a quella piattaforma.
Conviene quindi memorizzare i dati in un formato comune, leggibile da più piattaforme o strumenti.
Anche questo scenario è una storia vera, ispirata a fatti realmente accaduti qualche anno fa. Se domani il vendor X raddoppia (o più) i prezzi e vi dà 90 giorni prima che i nuovi costi diventino pienamente effettivi, uno dei passaggi più impegnativi della migrazione è già stato risolto: lo storage. Dovrete preoccuparvi soltanto della parte compute del data warehouse, e non dell'intero ecosistema.
L'altro vantaggio poco citato dell'uso di un formato comune è la riduzione dei costi del team Data. Se ne parla troppo poco, ma se i team Data lavorano con un unico formato dati in un unico ambiente, la complessità si riduce drasticamente, così come i tempi di implementazione. Tutto, alla fine, si traduce in costi: più velocemente il team riesce a implementare, più basso è il costo complessivo del team.
Il come
Mostrerò un esempio concreto di implementazione nella Parte 2, ma ecco una panoramica di massima.
Anziché memorizzare i dati nel formato nativo del data warehouse, li salverete in un formato comune (in questo caso Apache Iceberg) all'interno di un bucket di storage condiviso, organizzato secondo uno schema di partizionamento logico. Avrete così un'unica fonte di verità in un'unica posizione.
Questa unica fonte di verità viene interrogata direttamente dagli strumenti di data warehouse e le modifiche si riflettono in nuove tabelle nello stesso formato. È un ciclo che mantiene tutto semplice e previene molte delle complessità tipiche delle soluzioni proprietarie.
Avendo un'unica posizione e un unico formato per la fonte di verità, gran parte delle complessità viene semplicemente delegata all'infrastruttura, lasciandovi liberi di concentrarvi sui dati anziché sulla piattaforma.
Nella Parte 2
Nella Parte 2 di questa serie entrerò nel vivo dell'implementazione: come replicare i dati da un database tradizionale a una tabella Iceberg, ponendo le basi del data warehouse.
How We DoiT
In DoiT International affrontiamo problemi come questi ogni giorno e mi viene costantemente chiesto come risparmiare durante l'implementazione di progetti dati.
Aiutare i clienti a realizzare i propri progetti nel modo più efficace ed efficiente in termini di costi fa parte della nostra missione. Dalla gestione di casi come questo all'erogazione delle migliori soluzioni FinOps per i nostri clienti: è ciò che facciamo e — sarò forse un po' di parte — lo facciamo DAVVERO bene.