Die Serie
Diese Artikelserie dreht sich um die Replikation von Daten aus Ihrer klassischen Datenbank (SQL oder NoSQL) in einen plattformunabhängigen Data Lake (oder Data Lakehouse – je nachdem, wen Sie fragen) für Ihre eher analytischen workloads. Ich zeige darin die theoretische Architektur, baue das Framework Schritt für Schritt auf und liefere am Ende ein Praxisbeispiel mit einer Postgres-Datenbank.
Die Idee zu dieser Serie entstand, als ich kurz hintereinander mehrere Kunden dabei begleitet habe, Daten aus ihren Postgres-Datenbanken in Iceberg-Tabellen zu überführen, damit ihr BI-Tooling sie abfragen kann. Nachdem ich mehrfach dieselbe Session zum gleichen Thema gehalten hatte, war klar: Das gehört aufgeschrieben – eine wirklich gute Schritt-für-Schritt-Anleitung dazu habe ich nämlich nicht gefunden.
Als Bonus setze ich hier ausschließlich auf Open-Source-Software und Standarddienste der Cloud-Anbieter. So bleibt das Ganze so plattformunabhängig wie möglich.
Also: Bühne frei, los geht's!
Das Szenario
Sie nähern sich der kritischen Masse: Ihre Transaktionsdaten liegen in einer oder mehreren klassischen Datenbanken, und Ihr Datenteam stößt zunehmend an Grenzen, weil die Daten verteilt sind und nicht für ihre Zwecke aufbereitet vorliegen. Hinzu kommt: Das Team möchte für analytische workloads ein Data Warehouse einsetzen, das mit den bestehenden Datenbanken nicht zusammenspielt.
Das Datenteam macht außerdem deutlich, dass das Wachstum weiter Fahrt aufnehmen wird – das verschärft die Lage zusätzlich. Es ist also höchste Zeit, Ihre Daten zu transformieren und in einem Data Warehouse abzulegen.
Sie schauen sich die großen Namen am Markt an – Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse, Redshift –, sind aber von der Auswahl erschlagen und wollen eine Entscheidung treffen, die Ihnen Plattformunabhängigkeit sichert.
Wenn Ihnen das bekannt vorkommt, dann habe ich gute Nachrichten für Sie: Lesen Sie weiter!
Und falls Sie nicht in dieser Lage sind, aber mehr darüber erfahren möchten, wie sich ein plattformunabhängiges Data Warehouse (oder genauer: ein Data Lake) aufbauen lässt – dann lesen Sie ebenfalls einfach weiter.
Die (abstrakte) Architektur
In dieser Serie zeige ich eine Referenzarchitektur und eine Beispielimplementierung, mit der Daten aus einer klassischen RDBMS-Datenbank in einen Data Lake im BLOB-Storage eines Cloud-Anbieters – im Apache-Iceberg-Format – überführt werden. Ein Data-Warehouse-System kann diese Daten anschließend für den täglichen Betrieb nutzen.
Die Referenzarchitektur ist sehr einfach gehalten und sieht ungefähr so aus:
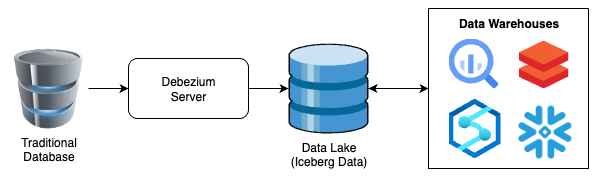
Wie zu erwarten (und meistens auch zutreffend), steckt in der Praxis deutlich mehr dahinter. Trotzdem zeigt dieses sehr einfache Diagramm, wie kraftvoll der Ansatz ist – und welche Plattformunabhängigkeit sich damit erreichen lässt.
Das hier ist außerdem die maximal abgespeckte Variante: Rohdaten werden ohne Transformationen in eine Iceberg-Tabelle repliziert. Das ist Absicht und der Übersichtlichkeit dieses Artikels geschuldet. In späteren Teilen der Serie zeige ich, wo und wie sich das T in ETL ergänzen lässt. Für diesen Artikel gilt: Keep It Simple, Stupid.
Die Bausteine dieses Puzzles
Ich gehe jeden Baustein des hier gezeigten Beispielsystems einzeln durch, definiere die Begriffe und erläutere zugleich, wie ich einige der modernen Buzzwords verstehe.
Traditional
Das ist das Datenbanksystem, das Ihre Anwendungen nutzen. Es kommt typischerweise für Dinge wie Transaktionen (Käufe, Klicks auf einer Seite, Audit-Einträge usw.) oder zur Speicherung von Anwendungsdaten zum Einsatz.
Wer aus der klassischen Welt der relationalen Datenbanken kommt, wird das wahrscheinlich der Kategorie Online Transaction Processing (OLTP) zuordnen – im Kern eine schickere Umschreibung dafür, dass diese Systeme Transaktionen sehr gut beherrschen. Beispiele dafür sind MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Oracle Database und IBM DB2. Es gibt unzählige weitere, aber das sind die wichtigsten, die heute noch eine Rolle spielen.
Wer aus der nicht-relationalen oder NoSQL-Welt kommt, hat verschiedene Optionen. Solange das System von Debezium unterstützt wird, funktioniert es. Zum Zeitpunkt dieses Artikels umfasst diese Liste MongoDB, Cassandra, Google Spanner sowie alles, was sich über einen Kompatibilitäts-Layer als Datenquelle anbinden lässt.
Data Warehouse
Das ist das Produkt, das die Abfragen und die Analyseverarbeitung für Sie übernimmt. Es fällt in der Regel in die Kategorie OLAP bzw. Online Analytics Processing (OLAP) – im Kern eine schickere Umschreibung dafür, dass es analytische workloads und Verarbeitungsprozesse sehr gut beherrscht. Beispiele sind Google BigQuery, Snowflake, Databricks, DuckDb, ClickHouse, Amazon Redshift und Microsoft Azure Synapse.
Hinweis: Im Kontext dieses Artikels nutze ich das Data Warehouse ausschließlich für die Compute-Seite, nicht für die Speicherung. Daher gehe ich darauf nicht weiter ein.
Data Lake
Das ist der Ort, an dem Sie alle Rohdaten zur Verarbeitung ablegen und an dem Sie die Ergebnisse Ihrer Transformationen schreiben, die später für Ihre Analyseprozesse gelesen werden.
Häufig ist das ein bunter Mix aus Dateiformaten – ich empfehle jedoch DRINGEND, sich auf ein einheitliches Format wie Apache Iceberg festzulegen. Genau dafür wurden Iceberg und vergleichbare Formate geschaffen: um Speicherformate für Data Lakes zu standardisieren.
Ein Data Lake liegt häufig auf einer Speicherklasse namens BLOB (steht für Binary Large OBject) Storage. Vereinfacht gesagt ist das eine nahezu unbegrenzt große Festplatte, die in einer Cloud-Umgebung läuft (oder in manchen On-Premise-Rechenzentren).
Verbreitete Beispiele dafür sind AWS Simple Storage Service (S3), Google Cloud Storage, Azure Blob Storage, Oracle Object Storage oder Digital Ocean Spaces Object Store.
Apache Iceberg
Apache Iceberg ist ein Datenspeicherformat, das sich hervorragend für sich langsam ändernde Daten (sprich: Data-Warehouse-Daten) auf BLOB-Storage eignet. Analytische Datenbanken können nahtlos darauf zugreifen, als lägen die Daten in deren nativem Speicherformat. Iceberg dient als gemeinsames Format für Data Lakes und schafft Plattformunabhängigkeit – oder zumindest so viel davon, wie heute technisch möglich ist.
Eines sollte man dabei erwähnen: Iceberg eignet sich hervorragend für analytische Abfragen, vom Einsatz für transaktionale workloads kann ich aber NUR ABRATEN. Fivetran hat dazu diesen Artikel, der die Grundlagen zeilen- versus spaltenbasierter Datenbanken erklärt – und damit direkt das Warum.
In Wahrheit ist es deutlich komplexer, aber das ist die einfachste Erklärung. Wer die vollständige Feature-Liste und mehr kennen möchte, dem empfehle ich die offizielle Dokumentation hier.
Das Warum?
Heutzutage gibt es VIELE Optionen im Data-Warehousing-Bereich – um nur einige zu nennen: BigQuery, ClickHouse, Snowflake, Databricks, DuckDB, Redshift, Firebolt und Synapse Analytics.
Standardmäßig nutzt jedes dieser Data Warehouses ein eigenes proprietäres Format zur Datenspeicherung. Das heißt: Sie sind an den Anbieter gebunden – und einige sind zusätzlich an die jeweilige Cloud gebunden, in der sie exklusiv laufen. Außerdem landen die Daten in Silos und lassen sich nicht von konkurrierenden Data Warehouses oder anderen, nicht plattformgebundenen Tools lesen.
Es liegt also in Ihrem Interesse, Daten in einem gemeinsamen Format abzulegen, das von mehreren Plattformen oder Tools gelesen werden kann.
Dieses Szenario ist übrigens kein theoretisches Konstrukt, sondern beruht auf einer wahren Geschichte aus den letzten Jahren. Wenn Anbieter X morgen die Preise um den Faktor 2 oder mehr anhebt und Ihnen 90 Tage gibt, bis die neuen Kosten voll greifen, dann ist einer der größten Migrationsschritte für Sie bereits erledigt: die Speicherung. Sie müssten sich nur noch um den Compute-Aspekt Ihres Data Warehouses kümmern – nicht um das gesamte Ökosystem.
Der andere, oft unausgesprochene Vorteil eines gemeinsamen Formats: niedrigere Kosten für das Datenteam. Das kommt zu selten zur Sprache, aber wenn Ihre Datenteams in einer einzigen Umgebung mit einem einzigen Datenformat arbeiten, sinkt die Komplexität enorm – und damit die Time-to-Implementation. Am Ende läuft alles auf Kosten hinaus: Je schneller das Team umsetzen kann, desto niedriger die Gesamtkosten des Teams.
Das Wie?
Ein Beispiel zur Umsetzung folgt in Teil 2 – hier zunächst ein grober Überblick.
Statt Daten im nativen Format Ihres Data Warehouses zu speichern, legen Sie sie in einem gemeinsamen Format (in diesem Fall Apache Iceberg) in einem gemeinsamen Storage-Bucket ab, der einem logischen Partitionierungsschema folgt. So entsteht eine Single Source of Truth an einem einzigen Ort.
Als Single Source of Truth wird sie direkt von den Data-Warehouse-Tools abgefragt, und Änderungen werden in neuen Tabellen im selben Format abgebildet. Das ergibt einen Kreislauf, der vieles einfach hält und viele Schwierigkeiten vermeidet, die proprietäre Lösungen mit sich bringen.
Da es nur einen Ort und ein Format für diese Source of Truth gibt, lassen sich viele dieser Schwierigkeiten in die Infrastruktur abstrahieren – und Sie können sich auf die Daten konzentrieren statt auf die Plattform.
Vorschau auf Teil 2
In Teil 2 dieser Serie zeige ich, wie sich die Replikation von Daten aus einer klassischen Datenbank in eine Iceberg-Tabelle als Grundlage für ein Data Warehouse konkret umsetzen lässt.
How We DoiT
Bei DoiT International beschäftigen wir uns ständig mit Fragestellungen wie dieser, und ich werde immer wieder gefragt, wie sich bei Datenprojekten Kosten sparen lassen.
Projekte möglichst effektiv und kosteneffizient umzusetzen, ist Teil unserer Mission für unsere Kunden. Wir kümmern uns um alles – von Fällen wie diesem bis hin zu den besten FinOps-Lösungen für unsere Kunden. Vielleicht bin ich an dieser Stelle etwas voreingenommen, aber wir machen das SEHR gut.