La série
Voici une série d'articles consacrés à la réplication des données depuis votre base traditionnelle (SQL ou NoSQL) vers un data lake indépendant de toute plateforme (ou data lakehouse, selon les écoles) destiné à vos workloads analytiques. Tout au long de cette série, je présenterai l'architecture théorique, je construirai le framework correspondant, puis je terminerai par un exemple concret d'implémentation depuis une base Postgres.
L'idée de cette série m'est venue en accompagnant successivement plusieurs clients qui voulaient acheminer leurs données depuis leurs bases Postgres vers des tables Iceberg, afin de les interroger via leurs outils de BI. Après plusieurs sessions consacrées au même sujet, j'ai décidé de coucher tout cela par écrit, faute d'avoir trouvé un guide pas-à-pas satisfaisant.
Petit bonus : je vais utiliser exclusivement des logiciels open-source et des services standards des fournisseurs cloud, afin que la solution reste aussi indépendante que possible de la plateforme cloud retenue.
Maintenant, entrons dans le vif du sujet !
Le scénario
Vous atteignez une masse critique : vos données transactionnelles sont réparties dans une ou plusieurs bases traditionnelles, et votre équipe data commence à éprouver des difficultés à faire son travail, les données étant éclatées et non transformées selon ses besoins. Elle envisage par ailleurs d'adopter un data warehouse pour ses workloads analytiques, qui ne fonctionnera pas avec les bases existantes.
Votre équipe data vous indique également que la croissance va s'accélérer, ce qui aggravera encore le problème. Le moment est donc venu de transformer vos données et de les stocker dans un data warehouse.
Vous regardez les grands noms du marché — Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse, Redshift — mais vous êtes complètement submergé par les options et vous voulez faire un choix qui vous garantisse l'indépendance vis-à-vis de la plateforme.
Si cela vous parle, j'ai une bonne nouvelle pour vous : poursuivez votre lecture !
Et si ce n'est pas votre cas mais que vous souhaitez en savoir plus sur la création d'un data warehouse (ou plus exactement d'un data lake) indépendant de la plateforme, poursuivez également votre lecture.
L'architecture (abstraite)
Dans cette série, je présenterai une architecture de référence ainsi qu'un exemple d'implémentation pour acheminer des données depuis une base RDBMS traditionnelle vers un data lake hébergé sur le stockage BLOB d'un fournisseur cloud, au format Apache Iceberg, qu'un data warehouse pourra ensuite exploiter au quotidien.
L'architecture de référence est très simple et ressemble à ceci :
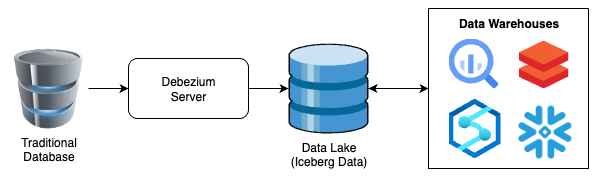
Comme on peut s'en douter (et comme c'est généralement le cas), il y aura beaucoup à ajouter à cela, mais ce schéma très simple illustre la puissance du processus et l'indépendance de plateforme que l'on peut atteindre.
Il s'agit également de la version ultra simplifiée : nous répliquons des données brutes vers une table Iceberg sans transformation. C'est volontaire, par souci de simplicité. Je préciserai dans les parties suivantes comment et où ajouter le T de l'ETL, mais pour cet article, restons fidèles au principe Keep It Simple, Stupid.
Les pièces du puzzle
Je vais passer en revue chaque élément du système d'exemple présenté ici afin d'en définir les briques, et préciser au passage les définitions que j'utilise pour certains termes à la mode.
Traditionnel
Il s'agit du système de base de données utilisé par vos applications. Il sert généralement à gérer des transactions (achats, clics sur une page, entrées d'audit, etc.) ou à stocker des données applicatives.
Si vous venez du monde des bases relationnelles traditionnelles, ce type de base relève probablement de la catégorie OLTP (Online Transaction Processing), ce qui, en clair, signifie qu'elle gère très bien les transactions. Quelques exemples : MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Oracle Database et IBM DB2. Il en existe d'innombrables autres, mais ce sont les principales encore en activité aujourd'hui.
Si vous venez du monde non relationnel (NoSQL), plusieurs options s'offrent à vous. Tant que la base est prise en charge par Debezium, elle conviendra. Au moment où j'écris ces lignes, la liste comprend MongoDB, Cassandra, Google Spanner, ainsi que tout système disposant d'une couche de compatibilité permettant son utilisation comme source de données.
Data Warehouse
C'est le produit qui réalise pour vous le requêtage et le traitement analytique. Il relève généralement de la catégorie OLAP (Online Analytics Processing), ce qui, en clair, signifie qu'il gère très bien les workloads et traitements analytiques. Quelques exemples : Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse, Amazon Redshift et Microsoft Azure Synapse.
Note : dans le cadre de cet article, je n'utilise le data warehouse que pour la partie compute, pas pour le stockage. C'est pour cette raison que je n'entre pas dans les détails à ce sujet.
Data Lake
C'est l'emplacement où vous stockez l'ensemble de vos données brutes pour consommation, et où vous écrivez les résultats des transformations qui seront lus par vos processus analytiques.
Cela prend souvent la forme d'un patchwork de formats de fichiers, mais je recommande VIVEMENT de standardiser sur un format unique tel qu'Apache Iceberg. C'est l'une des principales raisons pour lesquelles Iceberg et ses semblables ont été créés : standardiser les formats de stockage des data lakes.
Un data lake repose souvent sur une catégorie de périphériques de stockage appelés BLOB (pour Binary Large OBject). En termes plus simples, c'est un disque dur de capacité quasi infinie hébergé dans un environnement cloud (ou sur certains systèmes de data centers on-premise).
Parmi les exemples les plus courants : AWS Simple Storage Service (S3), Google Cloud Storage, Azure Blob Storage, Oracle Object Storage ou encore Digital Ocean Spaces Object Store.
Apache Iceberg
Apache Iceberg est un format de stockage de données particulièrement adapté aux données à évolution lente (typiquement, les données de data warehouse) sur du stockage BLOB. Il permet aux bases analytiques de l'interroger et de l'exploiter de façon transparente, comme s'il s'agissait nativement de leur propre format de stockage. Il fait office de format commun pour les data lakes afin d'atteindre l'indépendance de plateforme, ou du moins ce qui s'en rapproche le plus à l'heure actuelle.
Précisons qu'Iceberg est excellent pour les requêtes analytiques, mais je déconseille FORTEMENT de l'utiliser pour des workloads transactionnels. Fivetran propose un article qui couvre les bases des bases de données en lignes par rapport aux bases en colonnes, ce qui est directement lié à la raison de cette mise en garde.
C'est en réalité bien plus complexe que cela, mais il s'agit de l'explication la plus simple. Si vous souhaitez connaître la liste complète des fonctionnalités, je vous recommande la documentation officielle ici.
Pourquoi ?
De nos jours, les options en matière de data warehousing sont NOMBREUSES, en voici quelques-unes : BigQuery, ClickHouse, Snowflake, Databricks, DuckDB, Redshift, Firebolt et Synapse Analytics.
Chacun de ces data warehouses utilise par défaut son propre format propriétaire pour stocker les données. Cela signifie que vous êtes verrouillé chez l'éditeur, et certains sont en plus cantonnés au cloud auquel ils sont rattachés. Cela signifie aussi que vos données sont cloisonnées et inaccessibles aux data warehouses concurrents ou aux outils non liés à cette plateforme.
Vous avez donc tout intérêt à stocker vos données dans un format commun, lisible par plusieurs plateformes ou outils.
Ce scénario est par ailleurs une histoire vraie, vécue il y a quelques années. Si demain l'éditeur X double ses tarifs et vous laisse 90 jours avant que ces hausses ne soient pleinement effectives, vous aurez déjà franchi l'une des étapes de migration les plus lourdes : le stockage. Il ne vous restera plus qu'à vous préoccuper du compute de votre data warehouse, et non de l'écosystème entier.
L'autre avantage rarement évoqué d'un format commun, c'est la réduction des coûts liés à l'équipe data. On en parle trop peu, mais si vos équipes data n'ont qu'un seul format de données à manipuler dans un seul environnement, la complexité diminue fortement, tout comme les délais de mise en œuvre. Tout revient au coût : plus l'équipe livre vite, plus le coût global de l'équipe baisse.
Comment ?
Je présenterai un exemple d'implémentation dans la Partie 2, mais voici un aperçu du fonctionnement.
Au lieu de stocker les données dans le format natif de votre data warehouse, vous les stockez dans un format commun (ici, Apache Iceberg), au sein d'un bucket commun structuré selon un schéma de partitionnement logique. Vous disposez ainsi d'une source de vérité unique en un seul endroit.
En tant que source de vérité unique, elle est interrogée directement par les outils de data warehouse, et les modifications se reflètent dans de nouvelles tables au même format. Un cycle qui maintient la simplicité et évite bon nombre des complexités inhérentes aux solutions propriétaires.
Puisqu'il n'existe qu'un seul emplacement et un seul format pour cette source de vérité, une grande partie de la complexité est tout simplement absorbée au niveau de l'infrastructure, ce qui vous permet de vous concentrer sur les données plutôt que sur la plateforme.
À venir dans la Partie 2
Dans la Partie 2 de cette série, j'expliquerai en détail comment mettre en œuvre la réplication des données d'une base traditionnelle vers une table Iceberg, qui servira de socle à un data warehouse.
How We DoiT
Chez DoiT International, nous traitons ce type de problématiques en permanence, et on me demande sans cesse comment réaliser des économies tout en menant à bien des projets data.
Accompagner nos clients dans la mise en œuvre de leurs projets, de la manière la plus efficace et la plus rentable possible, fait partie de notre mission. De cas comme celui-ci aux meilleures solutions FinOps, c'est notre métier — et même si je suis sans doute un peu partial en disant cela, nous le faisons TRÈS bien.