A série
Esta é uma série de artigos sobre como replicar dados do seu banco tradicional (SQL ou NoSQL) para um data lake agnóstico de plataforma (ou data lakehouse, dependendo de a quem você pergunta), pensando nos seus workloads mais voltados a analytics. Ao longo dela, vou mostrar a arquitetura teórica, montar o framework e, por fim, dar um exemplo prático de implementação a partir de um banco Postgres.
A ideia desta série surgiu enquanto eu ajudava alguns clientes, em sequência, a levar dados dos seus bancos Postgres para tabelas Iceberg, para serem consultadas pelas ferramentas de BI deles. Depois de várias sessões sobre o mesmo tema, decidi que precisava registrar tudo isso, já que não encontrei um bom passo a passo sobre o assunto.
Como bônus, vou usar exclusivamente software open-source e serviços prontos dos provedores de nuvem, então tudo será o mais agnóstico possível em relação à plataforma de nuvem.
Agora, mãos à obra!
O cenário
Você está chegando àquele ponto crítico em que seus dados transacionais ficam em um ou mais bancos tradicionais, e seu time de dados começa a ter dificuldade para trabalhar com essas informações espalhadas em vários lugares e sem a transformação necessária. Além disso, eles estão considerando usar um data warehouse para os workloads analíticos, e isso não vai funcionar com os bancos atuais.
Seu time de dados também já mostrou que o crescimento vai acelerar, agravando ainda mais a situação. Ou seja, é hora de começar a transformar seus dados e armazená-los em um data warehouse.
Aí você olha para os grandes nomes do mercado, como Google BigQuery, Snowflake, Databricks, DuckDB, ClickHouse e Redshift, mas se sente totalmente perdido com tantas opções e quer tomar uma decisão que mantenha você agnóstico de plataforma.
Se isso soa familiar, então tenho uma boa notícia para você: continue lendo!
E se você não está nessa situação, mas quer entender melhor como criar um data warehouse agnóstico de plataforma (ou data lake, tecnicamente), continue lendo também.
A arquitetura (abstrata)
Nesta série, vou apresentar uma arquitetura de referência e uma implementação de exemplo para levar dados de um banco RDBMS tradicional até um data lake no armazenamento BLOB de um provedor de nuvem, em formato Apache Iceberg, que um sistema de data warehouse poderá usar nas operações do dia a dia.
A arquitetura de referência é bem simples e fica mais ou menos assim:
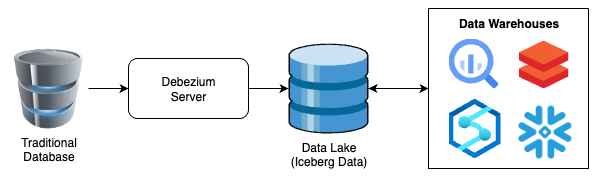
Como dá para imaginar (e geralmente é o que acontece), há muito mais coisa por trás disso, mas esse diagrama bem simples mostra o poder do processo e também o nível de agnosticismo de plataforma que dá para alcançar.
Esta também será a versão mais simples possível, replicando dados brutos para uma tabela Iceberg sem transformações. É uma escolha proposital, para manter o artigo enxuto. Vou deixar anotações sobre como e onde implementar melhorias adicionais para incluir o T do ETL nas próximas partes da série, mas, para este artigo, vamos seguir o princípio Keep It Simple, Stupid.
As peças deste quebra-cabeça
Vou passar por cada peça do sistema de exemplo que estou mostrando aqui para definir os componentes e também esclarecer como vou usar alguns dos termos da moda que circulam por aí.
Tradicional
Esse é o sistema de banco de dados que suas aplicações usam. Em geral, ele atende coisas como transações (compras, cliques em uma página, registros de auditoria etc.) ou o armazenamento de dados de aplicação.
Se você vem do mundo dos bancos relacionais tradicionais, isso provavelmente se enquadra na classe Online Transaction Processing (OLTP), que, no fundo, é uma forma elegante de dizer que esse tipo de banco lida muito bem com transações. Alguns exemplos: MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Oracle Database e IBM DB2. Existem inúmeros outros, mas esses são os principais que continuam relevantes hoje.
Se você vem do mundo não relacional, ou NoSQL, há algumas opções diferentes. Desde que seja suportado pelo Debezium, vai funcionar. No momento em que escrevo, essa lista inclui MongoDB, Cassandra, Google Spanner e qualquer banco que tenha uma camada de compatibilidade que permita usá-lo como fonte de dados.
Data warehouse
Esse é o produto que executa as consultas e o processamento analítico para você. Provavelmente se enquadra na classe OLAP, ou Online Analytics Processing (OLAP), que, no fundo, é uma forma elegante de dizer que esse tipo de banco lida muito bem com workloads e processos analíticos. Alguns exemplos: Google BigQuery, Snowflake, Databricks, DuckDb, ClickHouse, Amazon Redshift e Microsoft Azure Synapse.
Observação: no contexto deste artigo, estou usando o data warehouse apenas para o lado de computação, não de armazenamento. Por isso não entrei em detalhes sobre essa parte.
Data lake
É o local onde você guarda todos os seus dados brutos para consumo e onde grava os resultados das transformações que serão lidas pelos seus processos analíticos.
Muitas vezes, isso vira uma colcha de retalhos de formatos de arquivo, mas eu recomendo FORTEMENTE padronizar em um único formato, como o Apache Iceberg. Esse é um dos principais motivos pelos quais o Iceberg e seus pares foram criados: ajudar a padronizar os formatos de armazenamento em data lakes.
Um data lake costuma viver em uma classe de dispositivos de armazenamento chamada BLOB (sigla para Binary Large OBject). Em termos mais simples, é como um disco rígido de tamanho quase infinito que vive em um ambiente de nuvem (ou em alguns sistemas de data center on-premise).
Alguns dos exemplos mais comuns são AWS Simple Storage Service (S3), Google Cloud Storage, Azure Blob Storage, Oracle Object Storage e Digital Ocean Spaces Object Store.
Apache Iceberg
O Apache Iceberg é um formato de armazenamento de dados que funciona muito bem para guardar dados de mudança lenta (leia-se: dados no estilo data warehouse) em dispositivos BLOB, permitindo que bancos analíticos consultem e interajam com eles de forma transparente, como se estivessem armazenados nativamente no formato daquele banco. Ele funciona como um formato comum para data lakes alcançarem o agnosticismo de plataforma de dados, ou pelo menos o mais perto disso que dá para chegar hoje.
Vale mencionar que o Iceberg é ótimo para consultas analíticas, mas eu desaconselho FORTEMENTE usá-lo para workloads transacionais. A Fivetran tem este artigo, que cobre o básico de bancos orientados a linhas versus colunas, e isso se relaciona diretamente com o porquê dessa recomendação.
A história é bem mais complexa do que isso, mas essa é a explicação mais simples. Se quiser conhecer a lista completa de funcionalidades e mais detalhes, recomendo ler a documentação oficial aqui.
Por quê?
Hoje em dia, existem MUITAS opções na frente de data warehousing. Só para citar algumas: BigQuery, ClickHouse, Snowflake, Databricks, DuckDB, Redshift, Firebolt e Synapse Analytics.
Cada um desses data warehouses, por padrão, usa seu próprio formato proprietário para armazenar os dados. Isso significa que você fica preso a eles, e alguns ainda ficam presos à nuvem da qual são exclusivos. Significa também que esses dados ficam em silos e não podem ser lidos por outros data warehouses concorrentes ou por ferramentas que não sejam atreladas àquela plataforma.
Ou seja, é vantajoso armazenar seus dados em um formato comum, que possa ser lido por várias plataformas ou ferramentas.
Esse cenário também é uma história real, baseada em fatos de alguns anos atrás. Se amanhã o fornecedor X dobrar o preço e te der 90 dias até que esses custos sejam totalmente aplicados, um dos maiores passos da migração já estará feito para você: o armazenamento. Você só precisaria se preocupar com a parte de computação do seu data warehouse, em vez de todo o ecossistema.
Outro benefício pouco comentado de usar um formato comum é a redução dos custos do time de dados. Pouca gente fala disso, mas se os seus times de dados têm um único formato para trabalhar em um único ambiente, isso reduz bastante a complexidade e o tempo até a implementação. No fim das contas, tudo se resume a custo, então, resumindo: quanto mais rápido o time conseguir implementar, menor o custo total do time.
Como?
Vou mostrar um exemplo de como implementar isso na Parte 2, mas aqui vai uma visão geral de como a coisa funciona.
Em vez de armazenar os dados no formato nativo do seu data warehouse, você vai armazená-los em um formato comum (neste caso, Apache Iceberg), em um bucket de armazenamento comum, dividido em um esquema de particionamento lógico. Assim, você terá uma única fonte da verdade em um único local.
Como única fonte da verdade, ela é consultada diretamente pelas ferramentas de data warehouse, e as alterações são refletidas em novas tabelas no mesmo formato. É um ciclo que mantém tudo simples e evita muitas das complicações que vêm de soluções proprietárias.
Como existe um único local e um único formato para essa fonte da verdade, boa parte da complexidade fica abstraída na infraestrutura, permitindo que você foque nos dados em vez de na plataforma.
O que vem na Parte 2
Na Parte 2 desta série, vou mergulhar em como implementar a replicação de dados de um banco tradicional para uma tabela Iceberg, servindo de base para um data warehouse.
Como a gente faz na DoiT
Aqui na DoiT International, lidamos com problemas como esse o tempo todo, e sempre me perguntam sobre formas de economizar dinheiro ao implementar projetos de dados.
Ajudar a implementar projetos da forma mais eficaz e econômica possível faz parte da nossa missão junto aos clientes. Cuidar de tudo, desde casos como esse até oferecer as melhores soluções de FinOps para nossos clientes, é o que fazemos. Posso ser um pouco suspeito ao dizer isso, mas fazemos MUITO bem feito.