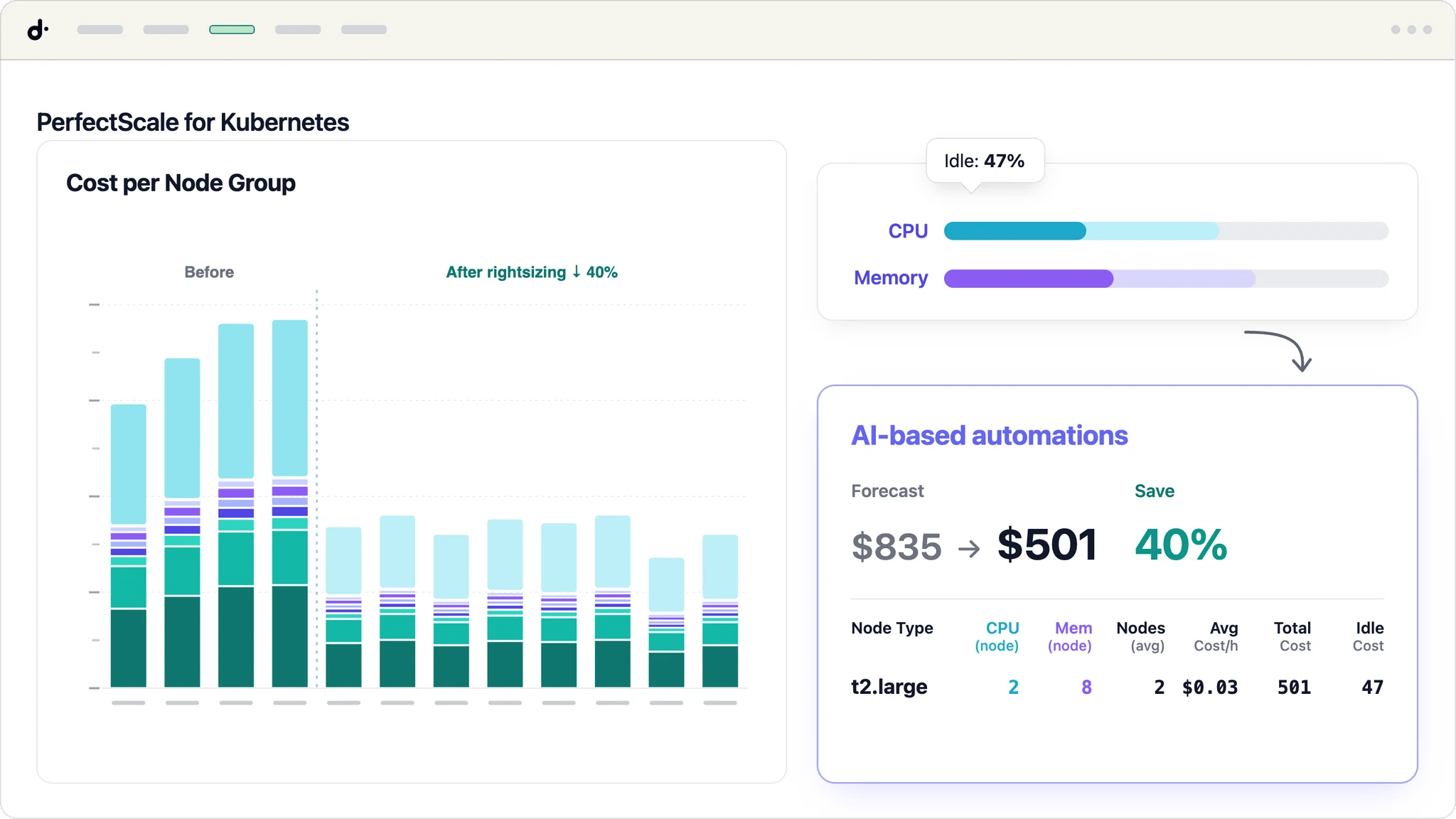
PerfectScale by DoiT has become an important part of how we optimize Kubernetes at scale at OneFootball. It gives our platform team the visibility, automation, resiliency insights, and confidence we need to balance cost efficiency with production readiness, especially as we prepare for major global football moments like the 2026 FIFA World Cup.
Andrea Benfatto, Platform/Cloud Runtime Engineering Manager