週末で試せる低コストなPOC。Azureを起点に、すぐ実行できるデプロイ手順をステップごとに解説します。

画像はAI(chatgpt5.0)で生成
TL;DR
- ID: Microsoft Entra ID を人間ユーザーの単一の信頼できるソースに据えます。Pinniped(Supervisor + Concierge)を介して任意のKubernetes(AKS/EKS/GKE)とブリッジし、すべてのクラスターでEntraサインインを受け付けるようにします。
- オブザーバビリティ: アプリ/インフラを OpenTelemetry で計装し、Azure Monitor / Log Analytics へ送信します。
- 検知: KQLの時系列ML(カスタムモデル不要)でサービス異常を特定・検出します。
- アクション: Azure Monitorアラート を Logic Apps/Azure Functions に連携し、安全かつ監査可能な是正処理を実行します。
得られる成果:単一の 認証基盤 と単一の オブザーバビリティ基盤 、MTTRの短縮 、そして実用的な ゼロトラスト統制 。MLインフラを別途構築する必要はありません。
想定読者
マルチクラウドでKubernetes(AKS/EKS/GKE)を運用するプラットフォーム/SRE/セキュリティアーキテクトの方で、次のようなニーズをお持ちの方を想定しています。
- 一元化され、監査可能な 人間ユーザー向けID基盤
- クラウドをまたいだ 標準化されたテレメトリ
- コストを抑えた 異常検知と 安全な自動化
この構成で解決できる課題
- AKS/EKS/GKEごとに分断されたユーザー認証 → 設定のドリフトと運用負荷の増大
- サイロ化されたテレメトリ → 検知のばらつきとインシデント対応の遅延
- MLスタックの自前構築は高コストで、多くのシグナルにとっては過剰
ゴール:(1)IDを一元化し、(2)テレメトリを標準化し、(3)軽量なKQL MLで検知し、(4)ガードレール付きの自動是正につなげる、再現可能なパターンを確立することです。
アーキテクチャ全体像
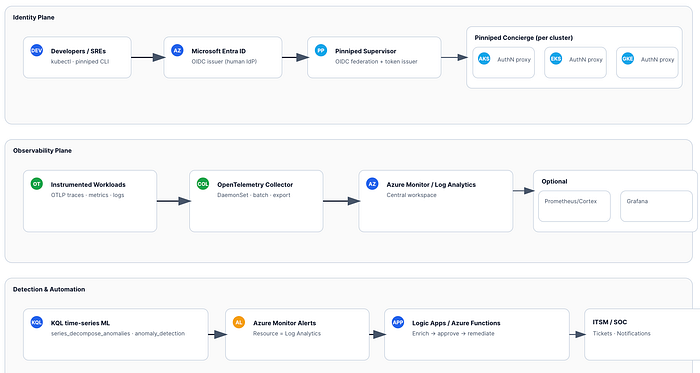
- Entra ID(IdP) → Pinniped Supervisor(OIDCイシュアー/フェデレーション) → Pinniped Concierge(クラスターごと)
- 開発者はEntraに一度サインインするだけで、AKS/EKS/GKE向けの短命なKubernetesトークンを取得できます。
- アプリ/インフラのテレメトリを OpenTelemetry SDK/自動計装 で取得 → OpenTelemetry Collector(DaemonSet) → Azure Monitor / Log Analytics(中央ワークスペース)に集約。オプションでメトリクスを remote_write によりPrometheus/Cortexへ転送し、Grafanaでダッシュボード化することも可能です。
- KQL の
series_decompose_anomalies/anomaly_detectionでID + サービスの異常を検知 → Azure Monitorアラート → Logic App/Azure Function でエンリッチと是正を実行。
ポリシーと自動化 (オプション)
- Kyverno/OPA Gatekeeperでアドミッション/ランタイムポリシーを管理。Azure Monitorアラート → Logic App / Azure Functionで一連の是正処理(チケット起票、条件付きアクセス、隔離)をオーケストレーションします。
Azureを起点とした事前準備(POCスコープ)
- 監視と共有サービス用の サブスクリプションとリソースグループ
- Log Analytics Workspace(中央)
- (オプション)Application Insights(Log AnalyticsにAIベースのアプリテレメトリビューを重ねたい場合)
- App Registration を作成できる権限を持つ Microsoft Entra テナント
- シークレット格納用の Azure Key Vault(Entraアプリのクライアントシークレットや、必要に応じて接続文字列も保管)
- kubectl と、少なくとも1つのクラスターへのアクセス(本ガイドではAKS。EKS/GKEは後述)
- PinnipedとOpenTelemetry Collector用の Helm
ヒント: 命名やリージョンは統一しておきましょう(例:
rg-plat-shared、law-plat-central)。
Azureクイックデプロイ — ステップバイステップ
このセクションでは、Azureを中心にゼロからシグナル取得とアラート発報までを通しで解説します。その後、EKS/GKEへ拡張していきます。
1) コア監視リソースの作成
オプションA — Azure CLI
# 変数
LOC=westeurope
RG=rg-plat-shared
LAW=law-plat-central
az group create -n $RG -l $LOC
az monitor log-analytics workspace create -g $RG -n $LAW -l $LOC# 後で利用するワークスペース情報を取得
LAW_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query id -o tsv)
LAW_CUST_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query customerId -o tsv)
LAW_KEY=$(az monitor log-analytics workspace get-shared-keys -g $RG -n $LAW --query primarySharedKey -o tsv)
オプションB — Bicep(冪等)
param location string = 'westeurope'
param rgName string = 'rg-plat-shared'
param workspaceName string = 'law-plat-central'
resource law 'Microsoft.OperationalInsights/workspaces@2022-10-01' = {
name: workspaceName
location: location
properties: {
retentionInDays: 30
features: {
searchVersion: 1
}
}
}
保持期間はコストに直結します。まずは30日から始め、コンプライアンス要件に合わせて調整してください。
2) Entraのサインイン/監査ログをLog Analyticsへエクスポート
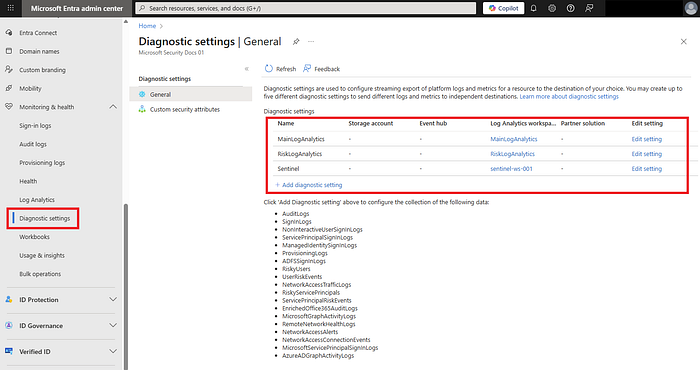
- Entra管理センター → 監視と正常性 → 診断設定 → 追加 から、SigninLogs と AuditLogs を作成済みの Log Analytics Workspace に送信します。
- 設定が 有効 になっていることを確認し、10〜15分後に
SigninLogs | take 5を実行してログが流れていることを確認します。
3) Pinniped Supervisor用のEntraアプリを登録
- App Registration:
openid、profile、email、offline_accessを付与します。 - Supervisorのコールバック用に リダイレクトURI を追加します(例:
https://pinniped.<your-domain>/callback)。 - クライアントシークレット を作成し、Key Vault に保管します。
- テナントID と クライアントID を控えておきます。
4) AKSへのPinnipedデプロイ(Supervisor + Concierge)
Supervisorは小規模な共有コントロールクラスターで稼働させ(推奨)、Concierge を各ワークロードクラスター(AKS/EKS/GKE)にデプロイする構成が可能です。
Supervisorのインストール(Helm)
helm repo add pinniped https://pinniped.dev/helm-charts
helm repo update
kubectl create ns pinniped-supervisor
helm upgrade --install pinniped-supervisor pinniped/supervisor \
-n pinniped-supervisor \
--set service.type=LoadBalancer \
--set config.generateTLS=true
FederationDomainの作成(Entraと連携)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
identityProviders:
- name: azuread
type: OIDC
oidc:
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: https://pinniped.<your-domain> # SupervisorのパブリックURL
Entraの クライアントシークレット は、
pinniped-supervisorネームスペースにpinniped-azure-secretという名前のKubernetes Secretとして保管します。
AKSクラスターへのConciergeインストール
kubectl create ns pinniped-concierge
helm upgrade --install pinniped-concierge pinniped/concierge \
-n pinniped-concierge \
--set credentialIssuer.enable=true
開発者ログインの検証
- 開発者のラップトップから:
pinniped login oidc --issuer https://pinniped.<your-domain> --ca-bundle <CA.pem> - 短命トークンを含むkubeconfigが生成され、AKSに対して
kubectl get podsが動作することを確認します。
EKS/GKEでも同様に Concierge をインストールすれば、クラウドをまたいだサインインを統合できます。
5) AKSへのOpenTelemetry Collectorデプロイ(Azure Monitorへ送信)
Helm(汎用Collector)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
kubectl create ns observability
cat <<'EOF' > values-otel.yaml
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
EOFhelm upgrade --install otel-collector open-telemetry/opentelemetry-collector -n observability -f values-otel.yaml
接続文字列はどこで取得できますか? Azureポータルで対象の Application Insights リソースを開き、概要 → 接続文字列 から取得できます。Data Collection Endpoints/RulesでLog Analyticsへ直接送信することも可能ですが、アプリトレースを送る経路としてはApplication Insightsが最もシンプルです。
テレメトリのタグ付けとサンプリング
- リソース属性を付与:
service.name、service.namespace、deployment.environment、team、costCenter。 - トレースは tail-based sampling(10〜20%)から始め、メトリクスは1〜5分の解像度を維持します。
A. ID異常(スパイク) — ノイズを除外し、Impossible Travelを追加してユーザー単位で分析
ポイント:
- サービスアカウント/ブレークグラスアカウントを除外
- 7日間のローリングベースライン と 24時間の周期性 を活用
- ジオ情報のエンリッチ と、オプションの Impossible Travel チェックを追加
- アラートルーティングしやすい整理されたペイロードを出力
// ---- パラメータ
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
let sensitivity = 95; // 90–99; 値が大きいほどアラートは減る
let serviceAccounts = dynamic(["svc_", "automaton@", "spn-"]); // 除外するプレフィックス/マーカー
// ---- メイン
SigninLogs
| where TimeGenerated > ago(lookback)
| where ResultType != 0 // 失敗のみ
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (serviceAccounts)) // svc/breakglassを除外
| summarize failed=count(),
ips = make_set(IPAddress, 4),
apps = make_set(AppDisplayName, 4)
by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed)
on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend decomp = series_decompose(failedSeries, 24) // 日次パターンをモデル化
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime),
failedSeries to typeof(double),
decomp to typeof(dynamic),
anomalies to typeof(double)
| where anomalies > 0
// ---- オプション:ジオ情報 + impossible travel
| join kind=leftouter (
SigninLogs
| where TimeGenerated > ago(lookback)
| summarize arg_max(TimeGenerated, *) by UserId, IPAddress
| project UserPrincipalName, IPAddress, Country = LocationDetails.countryOrRegion, Latitude = todouble(LocationDetails.geoCoordinates.latitude), Longitude = todouble(LocationDetails.geoCoordinates.longitude)
) on $left.UPN == $right.UserPrincipalName
| project TimeGenerated, UPN, failed=failedSeries, IPs=ips, Apps=apps, Country, Latitude, Longitude, anomalyScore=anomalies
| order by anomalyScore desc
オプションのImpossible Travelアドオン(2時間未満で1,500km超のペアワイズ移動を検出):
let minKm = 1500.0;
let maxHours = 2.0;
let toRad = (d:real) { d * pi() / 180.0 };
let haversine = (lat1:real, lon1:real, lat2:real, lon2:real) {
let dlat = toRad(lat2 - lat1);
let dlon = toRad(lon2 - lon1);
let a = pow(sin(dlat/2),2) + cos(toRad(lat1)) * cos(toRad(lat2)) * pow(sin(dlon/2),2);
6371.0 * 2 * asin(sqrt(a)) // km
};
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType == 0
| project UPN = UserPrincipalName, TimeGenerated, Lat = todouble(LocationDetails.geoCoordinates.latitude), Lon = todouble(LocationDetails.geoCoordinates.longitude)
| where isnotempty(Lat) and isnotempty(Lon)
| serialize
| extend prevTime = prev(TimeGenerated), prevLat = prev(Lat), prevLon = prev(Lon), prevUPN = prev(UPN)
| where UPN == prevUPN
| extend hrs = real(datetime_diff("minute", TimeGenerated, prevTime)) / 60.0
| extend km = haversine(prevLat, prevLon, Lat, Lon)
| where hrs > 0 and km / hrs > (minKm / maxHours)
| project TimeGenerated, UPN, km, hrs, speedKmh = km/hrs
ヒント:ID異常 と Impossible Travel は 別々のアラート として運用し、後者はより高い重大度にルーティングするのがおすすめです。
B. サービス異常 — データテーブルに合わせ、エラー率とSLOバーンを追加
アプリテレメトリを Application Insights(OTel→Azure Monitorの構成では一般的)経由で送る場合は、Perf を以下のより情報量の多いテーブルに置き換えます。
p95レイテンシのスパイク(App Insights / OTel)
let window = 7d;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize p95 = percentile(duration, 95) by bin(timestamp, step), cloud_RoleName
| make-series p95Series = avg(p95) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 24)
| mv-expand timestamp to typeof(datetime), p95Series to typeof(real), anomalies to typeof(double)
| where anomalies > 0
| project timestamp, service=cloud_RoleName, p95_ms = toreal(p95Series), anomalyScore = anomalies
| order by anomalyScore desc
エラー率のスパイク(レイテンシ単独より実用的)
let window = 24h;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize total=count(), errors = countif(success == false) by bin(timestamp, step), cloud_RoleName
| extend errRate = todouble(errors)/todouble(total)
| make-series errSeries = avg(errRate) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(errSeries, 95, 24)
| mv-expand timestamp to typeof(datetime), errSeries to typeof(real), anomalies to typeof(double)
| where anomalies > 0 and errSeries > 0.02 // ガードレール:エラー率 >2%
| project timestamp, service=cloud_RoleName, errorRate = round(errSeries*100.0, 2), anomalyScore = anomalies
| order by anomalyScore desc
SLOバーンレート(短期/長期ウィンドウ) — ページング向きの指標
// 例:99.9%成功率SLO
let slo = 0.999;
let fast = 5m;
let slow = 1h;
let targetBurn = 14.4; // エラーバジェットを14.4倍消費した時点でページ
let agg = (win:timespan) {
requests
| where timestamp > ago(win)
| summarize total=count(), errors=countif(success == false) by cloud_RoleName
| project cloud_RoleName, errRate = todouble(errors)/todouble(total)
};let fastW = agg(fast);
let slowW = agg(slow);fastW
| join kind=inner slowW on cloud_RoleName
| extend burnFast = (1.0 - slo) == 0 ? 0.0 : errRate_left / (1.0 - slo),
burnSlow = (1.0 - slo) == 0 ? 0.0 : errRate_right / (1.0 - slo)
| extend burnRate = burnFast / burnSlow
| where burnRate > targetBurn and errRate_left > (1.0 - slo)
| project service=cloud_RoleName, burnRate=round(burnRate,2), errRateFast=round(errRate_left*100,3), errRateSlow=round(errRate_right*100,3)
本当に
Perfテーブルに依存している場合(Legacy/VM/Container Insights)は、requestsの代わりにInsightsMetricsやカスタムメトリック名で同じロジックを再現してください。
C. 再利用可能なKQL関数としてラップする(アラートをすっきり)
これらをワークスペースに関数として登録しておくと、アラートルールがすっきり保てます。
// 関数 detect_failed_signin_anomalies(sensitivity:int, exclude:dynamic)
.create-or-alter function with (folder = "detections") detect_failed_signin_anomalies(sensitivity:int=95, exclude:dynamic=dynamic(["svc_"])) {
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType != 0
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (exclude))
| summarize failed=count() by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed) on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime), failedSeries to typeof(double), anomalies to typeof(double)
| where anomalies > 0
| project TimeGenerated, UPN, failed=failedSeries, anomalyScore=anomalies
}
これでアラートクエリは以下のようにシンプルになります。
detections.detect_failed_signin_anomalies(96, dynamic(["svc_","breakglass@"]))
7) アラート設計 — 実用的・低ノイズ・ルーティングしやすく
活用したいAzure Monitor機能:
- ディメンション分割:UPN単位 または サービス単位 でアラートを発生させます(ディメンション =
UPN/cloud_RoleName)。これにより複数主体をひとまとめにしたスパムを防ぎ、適切なチーム/ユーザーへ自動振り分けできます。 - 頻度とルックバック:まずは 15分 間隔・60分 ルックバックで開始し、安定してきたら 5分 へ短縮します。
- 違反回数:単一ビンでの一時的なブリップを避けるため、発火条件として 連続2回以上 の評価を要求します。
- アクションルール:メンテナンスウィンドウや既知のノイズ期間(大規模デプロイなど)中は抑制します。
- カスタムプロパティ:UPN/サービス、異常スコア、直近のIP/ジオ情報をアラートペイロードに含めます(Logic Appsで活用しやすくなります)。
- 2階層構成:SLOバーン用に Severity 2(ページ)、単純な異常用に Severity 3〜4(通知)を用意します。
アラートペイロードに含めたいフィールド(カスタム詳細):
entity:UPNまたはservicesignal:failed_signin_anomaly/latency_p95_anomaly/error_rate_spikescore:異常スコアcontext:直近3つのIP/国、または失敗が多いエンドポイントrunbook:是正手順ドキュメントへのリンク
アクショングループの構成:
- Logic App へのWebhook(プライマリ)
- 担当チーム向けのTeams/Slackチャンネル(ディメンションベース)
- ITSMコネクタ(チケット自動起票)
Logic Appの初期ステップ(推奨):
- 同じ
entity+signalでアクティブなインシデントが既に存在する場合は 重複排除/抑制。 - エンリッチ(ユーザーはGraph、サービスはAzure Resource Graph / GitOpsから情報取得)。
- ルーティング:
- 影響度低 → 通知 + チケット起票のみ
- 影響度高 → 承認 後にアクション(MFA要求/ブロック、ロールバック/ゼロスケール、PRの差し戻し)
小さくても効く運用上の工夫
- レビュアー向けのチャート:手動でトリアージするクエリには、ピン留めしたワークブックや
render timechartを加えておきます。
| project timestamp=TimeGenerated, failed=failedSeries
| render timechart
- ノイズのガードレール:異常検知クエリに最小の絶対閾値(例:
failedSeries >= 5)を加え、軽微なブリップで発報しないようにします。 - 休日/週末の感度:季節性の誤検知が見られる場合は、週末は
sensitivityを下げる、もしくは小さなルックアップテーブルで祝日を除外します。 - サービスアカウントレジストリ:中央に一覧を保持し、
externaldata()でblobやGitHubのraw URLから取得することで、クエリを書き換えずにアナリストが更新できる運用にします。
- Azure Monitor → ログ を開き、クエリを実行します。
- 新しいアラートルール をクリック → リソース = Log Analyticsワークスペースに設定します。
- 条件 = 結果 > 0 を 閾値 としたクエリを指定します。
- アクショングループ = メール/SMS/ITSM + Logic App Webhook。
- 重大度 / 評価頻度 は控えめに開始(例:15分ごと)。
8) Logic Apps / Functionsによる安全な自動化
- Logic App がアラートを受信 → コンテキストをエンリッチ(ユーザーリスク、ジオ情報、直近の成功状況、サービス状態)→ 経路を判断:
- 通知のみ(初期数週間)+ ITSMでチケット起票。
- ガードレール付きアクション(承認あり)を Microsoft Graph(MFA要求、一時的なサインインブロックなど)やKubernetes RBACの変更で実行。
- すべての変更は 監査可能 であり、最小権限 の原則に沿う必要があります(後述)。
EKS/GKEへの拡張
- Supervisor を再利用し、各クラスターには Concierge をインストールします。
- OpenTelemetry Collector はクラスターごとに配置し、同一の Azureワークスペースへエクスポートします(
cloud.providerでタグ付け)。 - 同じKQLクエリをクラウド横断で再利用し、
cloud_RoleName/k8s.cluster.nameでピボットします。
リスクと緩和策
- 誤検知 : まずは 通知モード で運用を始め、感度とウィンドウを調整しながら磨き込みます。
- 自動化の影響範囲: 影響の大きい操作には 手動承認 を必須とし、段階的にロールアウトします。
- Supervisorの公開面: WAF の背後に置き、IPレンジ を制限し、TLSとHSTS を強制します。
- 最小権限: Graphのスコープは自動化対象のアクションに限定。Function/Logic AppのAzure RBACも 最小権限の原則 に従います。
コストとライセンス
- 主なコスト: ログの取り込みと保持。サンプリング と 30〜90日の保持期間 でコントロールします。
- KQL ML: 別途のMLインフラコストは発生しません。
- Entra P2(オプション): ネイティブのリスクシグナルが利用できます。P2を持たない場合は、KQL検知が補完的な統制として機能します。
- Pinniped: 軽量で、ログ費用に比べればインフラコストは無視できる範囲です。
コピペで使えるスニペット(付録)
FederationDomain(Supervisor ↔ Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
issuer: https://pinniped.<your-domain>
identityProviders:
- name: azuread
type: OIDC
oidc:
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
最小構成のOTel Collector(Azure Monitor向け)
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
KQL — ID異常
SigninLogs
| where TimeGenerated > ago(14d)
| where ResultType != 0
| summarize failed=count() by bin(TimeGenerated, 1h), UserPrincipalName
| make-series failedSeries=avg(failed) on TimeGenerated from ago(7d) to now() step 1h by UserPrincipalName
| extend anomalies = series_decompose_anomalies(failedSeries, 95, 7)
| where array_length(anomalies) > 0
KQL — サービスレイテンシ異常
Perf
| where TimeGenerated > ago(7d) and CounterName == "request_duration_ms"
| summarize p95 = percentile(CounterValue, 95) by bin(TimeGenerated, 5m), ServiceName
| make-series p95Series=avg(p95) on TimeGenerated from ago(7d) to now() step 5m by ServiceName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 7)
| where array_length(anomalies) > 0
すぐに手に入るもの
- Supervisor/Concierge + OTel Collectorを立ち上げるためのコピペ可能な Helm と YAML
- 本番投入できる KQL 異常検知クエリ2本
- 明確な Azure Monitorアラート と Logic App の連携手順
オプション:ポリシーと自動化(なぜ・いつ・どうやって)
追加する理由
- ゲートではなくガードレール: 危険な設定は実行前に防ぎ(アドミッション)、ランタイムでのドリフトはポリシーイベントとしてログに記録します。
- 運用ループを閉じる: 人間に飛ばすだけのアラートはMTTRを長引かせます。薄い自動化レイヤーを設けることで、安全に エンリッチ → 判断 →(必要に応じて)アクション までを回せます。
- 監査可能な統制: 自動化されたあらゆるアクションは、Azure Monitor + Logic Appsを介して承認とログを伴います。
具体的なユースケース
不審なサインインスパイク(ID)
- シグナル:
SigninLogsに対するKQLが、ユーザー/アプリの外れ値を検出。 - 自動化: アラート → Logic Appがユーザーリスク/ジオ情報でエンリッチ → チケットを起票し、さらに(承認を経て)Microsoft Graphを呼び出してステップアップMFAや一時的なサインインブロックを要求。
特権Podのドリフト(ランタイム)
- シグナル: Kyverno/Gatekeeperが
privileged: trueまたはCAP_SYS_ADMINを持つPodを報告。 - 自動化: アラート → Logic AppがSlack/Teamsへ投稿し、JIRAインシデントを追加。承認を経て、該当ネームスペースのDeploymentをゼロスケールへ縮退。
未署名イメージ/誤ったレジストリ(サプライチェーン)
- シグナル: アドミッションポリシーが
my-acr.azurecr.io由来でない、または共署名のないイメージを拒否。 - 自動化: 承認者の同意がある場合のみ、24時間限定の例外を作成し、その例外をLog Analyticsに記録。
オーナー/ラベル欠落のネームスペース(運用衛生)
- シグナル: アドミッションが、
owner/costCenterを欠いたネームスペース作成を拒否。 - 自動化: Logic Appが事前入力済みの
kubectl labelコマンドをリクエスト元へ通知。
環境変数に埋め込まれたシークレット(設定ミス)
- シグナル: ポリシーが、シークレットを平文参照しているマニフェストを監査。
- 自動化: PRボット(GitOpsフロー)経由で
Secret+ ボリュームマウントへ変換し、セキュリティチケットを起票。
デプロイすべき最小構成
- アドミッション(防止/変更): Kyverno または OPA Gatekeeper。
- ランタイム監査 → ログ: ポリシー結果を Log Analytics に出力。
- 意思決定: Azure Monitor アラートルール(KQLまたはポリシーイベントから)。
- オーケストレーション: 影響度の大きい箇所では人間による承認を伴う Logic Apps(またはAzure Functions)。
スターターポリシー(Kyverno)
特権コンテナの拒否:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged
spec:
validationFailureAction: enforce
rules:
- name: no-priv
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: "false"
オーナー/コストセンターラベルの必須化:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-owner-labels
spec:
validationFailureAction: enforce
rules:
- name: require-labels
match: { resources: { kinds: ["Namespace","Deployment","StatefulSet"] } }
validate:
message: "owner and costCenter labels are required."
pattern:
metadata:
labels:
owner: "?*"
costCenter: "?*"
イメージを自社ACRに限定:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-registries
spec:
validationFailureAction: enforce
rules:
- name: only-acr
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Images must come from my-acr.azurecr.io"
pattern:
spec:
containers:
- image: "my-acr.azurecr.io/*"
まずは 監査 モードがおすすめです:
validationFailureAction: auditで1週間運用してチューニングし、その後enforceへ切り替えましょう。
ID異常フロー
SigninLogsに対するKQLクエリ(本記事のもの)→ アラートルール(15分ごと)。- アクショングループ:Logic App Webhook + Teams/JIRA。
- Logic App の処理:
- ユーザー詳細とサインイン履歴を取得(Graph)。
- 直近のMFA成功状況を確認。
- 分岐:
- 影響度低:通知 + チケット。
- 影響度高:承認(サービスオーナー)→ Graphの
conditionalAccess更新または一時ブロック。 - 結果をLog Analyticsへ記録。
ランタイム/ポリシーフロー
- Kyverno → ポリシーイベントをLog Analyticsテーブルへ送信(OTelまたはAKS診断経由)。
disallow-privilegedの新たな 強制 失敗に対するKQLアラート。- Logic App:
- Deployment/Podメタデータを取得。
- サービスオーナーへ是正スニペットを通知。
- オプションで 承認 →
az aks command invokeまたは差し戻し/パッチ用のGitOps PR。
(ひとまず)スキップしてよいケース
- クラスターが1つ、チームが小規模、もしくはオンコール自動化の文化がまだ根付いていない場合。
- 条件付きアクセスを強制するためのEntra/Graph権限がない場合は、まず オブザーバビリティ + チケット から始め、強制は段階的に追加していきましょう。
サポートが必要ですか?お気軽にご相談ください。
概念実証の評価中、あるいはデプロイ計画を進めている方は、ぜひ DoiT にご相談ください。100名超のエキスパートチームが、お客様の状況に合わせたクラウドソリューションをご提案し、導入プロセスを伴走しながら、コンプライアンスや今後の要件に耐えうるインフラへと最適化します。
ポリシー強制のフェーズで貴社にとって最適な選択肢を一緒に検討し、堅牢かつコンプライアンスに準拠した、成果につながるクラウドインフラを実現しましょう。今すぐお問い合わせください。