Un POC pratico e a basso costo da realizzare in un weekend, con passaggi di deployment chiari e Azure-first

immagine generata dall'AI (chatgpt5.0)
In sintesi
- Identità: fai di Microsoft Entra ID l'unica fonte di verità per gli utenti umani. Collegalo a qualsiasi Kubernetes (AKS/EKS/GKE) tramite Pinniped (Supervisor + Concierge), così tutti i cluster accettano il sign-in di Entra.
- Observability: strumenta app e infrastruttura con OpenTelemetry → invia i dati ad Azure Monitor / Log Analytics.
- Detection: usa KQL time-series ML (senza modelli custom) per individuare e rilevare anomalie nei servizi.
- Azione: collega gli alert di Azure Monitor a Logic Apps/Azure Functions per una remediation sicura e tracciabile.
Risultato: un unico auth plane , un'unica observability fabric , MTTR più rapido e controlli zero-trust pragmatici, senza dover allestire infrastrutture ML.
A chi è rivolto
Architetti di piattaforma, SRE e architetti di sicurezza che gestiscono Kubernetes multi-cloud (AKS/EKS/GKE) e cercano:
- Un piano di identità umana centralizzato e tracciabile
- Telemetria standardizzata tra cloud diversi
- Anomaly detection attenta ai costi e automazione sicura
Quali problemi risolve?
- Autenticazione utente frammentata tra AKS/EKS/GKE → drift e lavoro manuale.
- Telemetria a silos → detection incoerente e risposta agli incidenti lenta.
- Mettere in piedi stack ML è costoso ed eccessivo per molti segnali.
Obiettivo: un pattern ripetibile che (1) centralizza l'identità, (2) standardizza la telemetria, (3) rileva anomalie con KQL ML leggero e (4) automatizza una remediation con guardrail.
Architettura in sintesi
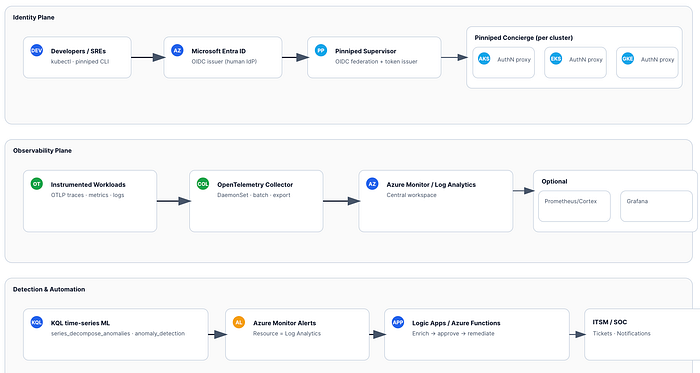
- Entra ID (IdP) → Pinniped Supervisor (OIDC issuer/federation) → Pinniped Concierge (uno per cluster).
- Gli sviluppatori effettuano l'accesso una sola volta con Entra e ottengono token Kubernetes a breve durata per AKS/EKS/GKE.
- Telemetria di app e infrastruttura tramite OpenTelemetry SDK/auto-instr → OpenTelemetry Collector (DaemonSet) → Azure Monitor / Log Analytics (workspace centrale). Opzionale: metriche in remote_write verso Prometheus/Cortex e dashboard in Grafana.
- KQL
series_decompose_anomalies/anomaly_detectionper anomalie di identità e di servizio → Azure Monitor Alerts → Logic App/Azure Function per arricchimento e remediation.
Policy & automazione (opzionale)
- Kyverno/OPA Gatekeeper per policy di admission/runtime; alert di Azure Monitor → Logic App / Azure Function per remediation orchestrate (ticketing, Conditional Access, quarantena).
Prerequisiti Azure-first (perimetro POC)
- Subscription e Resource Group per monitoring e servizi condivisi.
- Log Analytics Workspace (centrale).
- (Opzionale) Application Insights (se preferisci viste di telemetria applicativa basate su AI sopra LA).
- Tenant Microsoft Entra con i permessi per creare App Registrations.
- Azure Key Vault per i segreti (client secret dell'app Entra; eventuali connection string).
- kubectl + accesso ad almeno un cluster (AKS per il walkthrough Azure; EKS/GKE trattati più avanti).
- Helm per Pinniped e per OpenTelemetry Collector.
Suggerimento: tieni nomi e location coerenti (ad esempio
rg-plat-shared,law-plat-central).
Deployment rapido su Azure — passo per passo
Questa sezione ti accompagna da zero fino a segnali e alert, con focus su Azure. In seguito potrai estendere a EKS/GKE.
1) Crea le risorse di monitoring di base
Opzione A — Azure CLI
# Variabili
LOC=westeurope
RG=rg-plat-shared
LAW=law-plat-central
az group create -n $RG -l $LOC
az monitor log-analytics workspace create -g $RG -n $LAW -l $LOC# Recupera le info del workspace per dopo
LAW_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query id -o tsv)
LAW_CUST_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query customerId -o tsv)
LAW_KEY=$(az monitor log-analytics workspace get-shared-keys -g $RG -n $LAW --query primarySharedKey -o tsv)
Opzione B — Bicep (idempotente)
param location string = 'westeurope'
param rgName string = 'rg-plat-shared'
param workspaceName string = 'law-plat-central'
resource law 'Microsoft.OperationalInsights/workspaces@2022-10-01' = {
name: workspaceName
location: location
properties: {
retentionInDays: 30
features: {
searchVersion: 1
}
}
}
La retention è il principale driver di costo. Parti da 30 giorni e adegua in base ai requisiti di compliance.
2) Esporta i log di sign-in/audit di Entra in Log Analytics
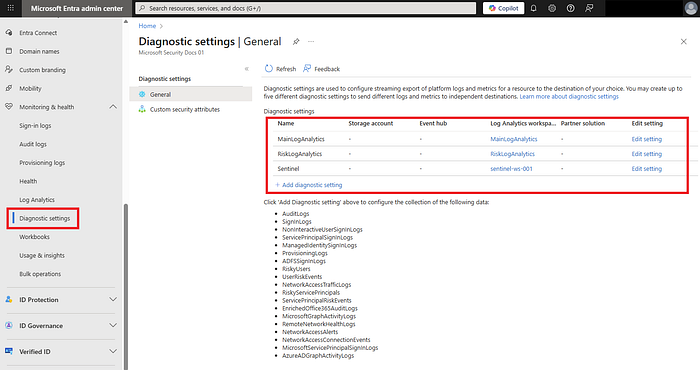
- Nell'admin center di Entra → Monitoring & health → Diagnostics settings → Add → invia SigninLogs e AuditLogs al Log Analytics Workspace appena creato.
- Verifica che l'impostazione sia abilitata e che i log fluiscano eseguendo
SigninLogs | take 5dopo 10–15 minuti.
3) Registra l'app Entra per Pinniped Supervisor
- App Registration: concedi
openid,profile,email,offline_access. - Aggiungi un Redirect URI per la callback del Supervisor (es.
https://pinniped.<your-domain>/callback). - Crea un client secret → conservalo in Key Vault.
- Annota Tenant ID e Client ID.
4) Esegui il deploy di Pinniped su AKS (Supervisor + Concierge)
Puoi eseguire il Supervisor in un piccolo cluster di controllo condiviso (consigliato) e installare Concierge su ogni cluster di workloads (AKS/EKS/GKE).
Installa Supervisor (Helm)
helm repo add pinniped https://pinniped.dev/helm-charts
helm repo update
kubectl create ns pinniped-supervisor
helm upgrade --install pinniped-supervisor pinniped/supervisor \
-n pinniped-supervisor \
--set service.type=LoadBalancer \
--set config.generateTLS=true
Crea il FederationDomain (collegamento a Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
identityProviders:
- name: azuread
type: OIDC
oidc:
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: https://pinniped.<your-domain> # URL pubblico del Supervisor
Conserva il client secret di Entra come secret Kubernetes denominato
pinniped-azure-secretnel namespacepinniped-supervisor.
Installa Concierge nei cluster AKS
kubectl create ns pinniped-concierge
helm upgrade --install pinniped-concierge pinniped/concierge \
-n pinniped-concierge \
--set credentialIssuer.enable=true
Verifica il login lato sviluppatore
- Da un laptop di sviluppo:
pinniped login oidc --issuer https://pinniped.<your-domain> --ca-bundle <CA.pem> - Conferma che venga generato un kubeconfig con token a breve durata e che
kubectl get podsfunzioni su AKS.
Ripeti l'installazione di Concierge per EKS/GKE per unificare il sign-in tra cloud diversi.
5) Esegui il deploy di OpenTelemetry Collector su AKS (export verso Azure Monitor)
Helm (collector generico)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
kubectl create ns observability
cat <<'EOF' > values-otel.yaml
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
EOFhelm upgrade --install otel-collector open-telemetry/opentelemetry-collector -n observability -f values-otel.yaml
Dove trovo la connection string? In Azure, apri la risorsa Application Insights → Overview → Connection string . Puoi inviare i dati direttamente a Log Analytics tramite Data Collection Endpoints/Rules, ma AI è la via più semplice per partire con i tracing applicativi.
Tag e sampling della telemetria
- Aggiungi attributi di risorsa:
service.name,service.namespace,deployment.environment,team,costCenter. - Parti con il tail-based sampling (10–20%) per i tracing; mantieni una risoluzione di 1–5 minuti per le metriche.
A. Anomalia di identità (picchi) — escludere il rumore, aggiungere "impossible travel" e dimensionare per utente
Cosa cambia:
- Esclude account di servizio e break-glass
- Usa una baseline rolling di 7 giorni con stagionalità a 24 ore
- Aggiunge arricchimento geografico e un controllo opzionale di impossible travel
- Genera un payload pulito, pronto per il routing degli alert
// ---- Parametri
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
let sensitivity = 95; // 90–99; più alto = meno alert
let serviceAccounts = dynamic(["svc_", "automaton@", "spn-"]); // prefissi/marker da escludere
// ---- Query principale
SigninLogs
| where TimeGenerated > ago(lookback)
| where ResultType != 0 // solo failure
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (serviceAccounts)) // esclude svc/breakglass
| summarize failed=count(),
ips = make_set(IPAddress, 4),
apps = make_set(AppDisplayName, 4)
by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed)
on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend decomp = series_decompose(failedSeries, 24) // modella il pattern giornaliero
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime),
failedSeries to typeof(double),
decomp to typeof(dynamic),
anomalies to typeof(double)
| where anomalies > 0
// ---- Geo opzionale + impossible travel
| join kind=leftouter (
SigninLogs
| where TimeGenerated > ago(lookback)
| summarize arg_max(TimeGenerated, *) by UserId, IPAddress
| project UserPrincipalName, IPAddress, Country = LocationDetails.countryOrRegion, Latitude = todouble(LocationDetails.geoCoordinates.latitude), Longitude = todouble(LocationDetails.geoCoordinates.longitude)
) on $left.UPN == $right.UserPrincipalName
| project TimeGenerated, UPN, failed=failedSeries, IPs=ips, Apps=apps, Country, Latitude, Longitude, anomalyScore=anomalies
| order by anomalyScore desc
Add-on opzionale "impossible travel" (salti geografici a coppie > 1.500 km in < 2 ore):
let minKm = 1500.0;
let maxHours = 2.0;
let toRad = (d:real) { d * pi() / 180.0 };
let haversine = (lat1:real, lon1:real, lat2:real, lon2:real) {
let dlat = toRad(lat2 - lat1);
let dlon = toRad(lon2 - lon1);
let a = pow(sin(dlat/2),2) + cos(toRad(lat1)) * cos(toRad(lat2)) * pow(sin(dlon/2),2);
6371.0 * 2 * asin(sqrt(a)) // km
};
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType == 0
| project UPN = UserPrincipalName, TimeGenerated, Lat = todouble(LocationDetails.geoCoordinates.latitude), Lon = todouble(LocationDetails.geoCoordinates.longitude)
| where isnotempty(Lat) and isnotempty(Lon)
| serialize
| extend prevTime = prev(TimeGenerated), prevLat = prev(Lat), prevLon = prev(Lon), prevUPN = prev(UPN)
| where UPN == prevUPN
| extend hrs = real(datetime_diff("minute", TimeGenerated, prevTime)) / 60.0
| extend km = haversine(prevLat, prevLon, Lat, Lon)
| where hrs > 0 and km / hrs > (minKm / maxHours)
| project TimeGenerated, UPN, km, hrs, speedKmh = km/hrs
Suggerimento: tieni identity anomaly e impossible travel come alert separati ; assegna a quest'ultimo una severity più alta.
B. Anomalie di servizio — allinea alle tue tabelle dati e aggiungi error rate + SLO burn
Se invii la telemetria applicativa tramite Application Insights (configurazione comune con OTel→Azure Monitor), sostituisci Perf con queste tabelle più ricche:
Picco di latenza p95 (App Insights / OTel)
let window = 7d;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize p95 = percentile(duration, 95) by bin(timestamp, step), cloud_RoleName
| make-series p95Series = avg(p95) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 24)
| mv-expand timestamp to typeof(datetime), p95Series to typeof(real), anomalies to typeof(double)
| where anomalies > 0
| project timestamp, service=cloud_RoleName, p95_ms = toreal(p95Series), anomalyScore = anomalies
| order by anomalyScore desc
Picco di error rate (più azionabile della pura latenza)
let window = 24h;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize total=count(), errors = countif(success == false) by bin(timestamp, step), cloud_RoleName
| extend errRate = todouble(errors)/todouble(total)
| make-series errSeries = avg(errRate) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(errSeries, 95, 24)
| mv-expand timestamp to typeof(datetime), errSeries to typeof(real), anomalies to typeof(double)
| where anomalies > 0 and errSeries > 0.02 // guardrail: error rate >2%
| project timestamp, service=cloud_RoleName, errorRate = round(errSeries*100.0, 2), anomalyScore = anomalies
| order by anomalyScore desc
SLO burn-rate (finestre fast/slow) — ottimo per il paging
// Esempio: SLO di successo al 99,9%
let slo = 0.999;
let fast = 5m;
let slow = 1h;
let targetBurn = 14.4; // page quando consumi 14,4x il budget di errore
let agg = (win:timespan) {
requests
| where timestamp > ago(win)
| summarize total=count(), errors=countif(success == false) by cloud_RoleName
| project cloud_RoleName, errRate = todouble(errors)/todouble(total)
};let fastW = agg(fast);
let slowW = agg(slow);fastW
| join kind=inner slowW on cloud_RoleName
| extend burnFast = (1.0 - slo) == 0 ? 0.0 : errRate_left / (1.0 - slo),
burnSlow = (1.0 - slo) == 0 ? 0.0 : errRate_right / (1.0 - slo)
| extend burnRate = burnFast / burnSlow
| where burnRate > targetBurn and errRate_left > (1.0 - slo)
| project service=cloud_RoleName, burnRate=round(burnRate,2), errRateFast=round(errRate_left*100,3), errRateSlow=round(errRate_right*100,3)
Se ti basi davvero sulla tabella
Perf(Legacy/VM/Container Insights), replica la stessa logica suInsightsMetricso sul nome della tua metrica custom invece che surequests.
C. Incapsula tutto in funzioni KQL riutilizzabili (alert più puliti)
Inseriscile nel tuo workspace come funzioni: le regole di alert resteranno ordinate.
// function detect_failed_signin_anomalies(sensitivity:int, exclude:dynamic)
.create-or-alter function with (folder = "detections") detect_failed_signin_anomalies(sensitivity:int=95, exclude:dynamic=dynamic(["svc_"])) {
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType != 0
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (exclude))
| summarize failed=count() by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed) on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime), failedSeries to typeof(double), anomalies to typeof(double)
| where anomalies > 0
| project TimeGenerated, UPN, failed=failedSeries, anomalyScore=anomalies
}
La query dell'alert diventa quindi semplicemente:
detections.detect_failed_signin_anomalies(96, dynamic(["svc_","breakglass@"]))
7) Alerting — azionabile, a basso rumore e facile da instradare
Sfrutta queste funzionalità di Azure Monitor:
- Split-by dimensions: crea un alert per UPN o per servizio (dimension =
UPN/cloud_RoleName). Eviti spam multi-soggetto e instradi automaticamente al team o all'utente giusto. - Frequenza e lookback: parti con frequenza di 15 min e lookback di 60 min; passa a 5 min quando il sistema è stabile.
- Numero di violazioni: richiedi almeno 2 valutazioni consecutive prima dello scatto, per evitare picchi isolati.
- Action Rules: sopprimi gli alert durante finestre di manutenzione o periodi notoriamente rumorosi (es. deploy importanti).
- Custom properties: aggiungi UPN/servizio, score di anomalia, ultimo IP/geo al payload dell'alert (utile per le Logic Apps).
- Due livelli: usa Severity 2 (page) per lo SLO burn e Severity 3–4 (notifica) per anomalie semplici.
Campi del payload dell'alert da includere (custom details):
entity:UPNoservicesignal:failed_signin_anomaly/latency_p95_anomaly/error_rate_spikescore: score di anomaliacontext: ultimi 3 IP/Paesi o gli endpoint con più errorirunbook: link al documento di remediation
Configurazione dell'Action Group:
- Webhook verso una Logic App (primario)
- Canale Teams/Slack del team owner (basato su dimensione)
- Connettore ITSM (creazione automatica del ticket)
Primi passi della Logic App (consigliati):
- De-dup/soppressione se esiste già un incident attivo per lo stesso
entity+signal. - Arricchimento (Graph per l'utente; Azure Resource Graph / GitOps per il servizio).
- Routing:
- Impatto basso → solo notifica + ticket
- Impatto alto → approvazione e poi azione (richiedi MFA / blocca; rollback/scale-to-0; revert della PR)
Piccoli accorgimenti che fanno la differenza
- Grafici per chi fa triage: aggiungi una workbook in pin o la riga
render timechartalle query che esamini manualmente
| project timestamp=TimeGenerated, failed=failedSeries
| render timechart
- Guardrail anti-rumore: nelle query di anomaly aggiungi soglie assolute minime (es.
failedSeries >= 5), così piccoli picchi non generano alert. - Sensibilità a festività e weekend: se noti falsi positivi stagionali, abbassa la
sensitivitynei weekend o escludi le festività con una piccola tabella di lookup. - Registro degli account di servizio: tieni un elenco centrale e caricalo via
externaldata()da blob o URL raw GitHub: gli analisti potranno aggiornarlo senza modificare le query.
- Apri Azure Monitor → Logs → esegui una query.
- Clicca New alert rule → imposta Resource = workspace di Log Analytics.
- Condition = la tua query con threshold sui risultati > 0.
- Action group = email/SMS/ITSM + webhook Logic App.
- Severity/Evaluation frequency = parti conservativo (es. ogni 15 min).
8) Automazione sicura con Logic Apps / Functions
- La Logic App riceve l'alert → arricchisce il contesto (rischio utente, geo, ultimi successi, salute del servizio) → decide il percorso:
- Solo notifica (nelle prime settimane) con apertura ticket in ITSM.
- Azione con guardrail (con approvazione) tramite Microsoft Graph (es. richiedere MFA, blocco temporaneo del sign-in) o modifiche di RBAC Kubernetes.
- Tutte le modifiche devono essere tracciabili e con perimetro al minimo privilegio (vedi sotto).
Estensione a EKS/GKE
- Riutilizza il Supervisor; installa Concierge in ogni cluster.
- Mantieni un OpenTelemetry Collector per cluster; esporta verso lo stesso workspace Azure (con tag
cloud.provider). - Riutilizza le stesse query KQL su tutti i cloud; fai pivot su
cloud_RoleName/k8s.cluster.name.
Rischi e mitigazioni
- Falsi positivi : parti in modalità notifica; itera su sensitivity e finestre temporali.
- Blast radius dell'automazione: richiedi approvazione manuale per i passi ad alto impatto; rollout progressivo.
- Esposizione del Supervisor: mettilo dietro un WAF, restringi gli intervalli IP e applica TLS e HSTS.
- Minimo privilegio: gli scope Graph sono limitati alle azioni che automatizzi; l'RBAC Azure di Function/Logic App segue il principio del minimo privilegio.
Costi e licensing
- Costo principale: ingestion e retention dei log. Tieni sotto controllo con sampling e retention da 30 a 90 giorni.
- KQL ML: nessun costo aggiuntivo per infrastrutture ML dedicate.
- Entra P2 (opzionale): fornisce segnali di rischio nativi; se non hai P2, le tue detection KQL sono un controllo compensativo.
- Pinniped: leggero; il costo infrastrutturale è trascurabile rispetto a quello dei log.
Snippet pronti da copiare (appendice)
FederationDomain (Supervisor ↔ Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
issuer: https://pinniped.<your-domain>
identityProviders:
- name: azuread
type: OIDC
oidc:
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
OTel Collector minimale (verso Azure Monitor)
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
KQL — anomalia di identità
SigninLogs
| where TimeGenerated > ago(14d)
| where ResultType != 0
| summarize failed=count() by bin(TimeGenerated, 1h), UserPrincipalName
| make-series failedSeries=avg(failed) on TimeGenerated from ago(7d) to now() step 1h by UserPrincipalName
| extend anomalies = series_decompose_anomalies(failedSeries, 95, 7)
| where array_length(anomalies) > 0
KQL — anomalia di latenza dei servizi
Perf
| where TimeGenerated > ago(7d) and CounterName == "request_duration_ms"
| summarize p95 = percentile(CounterValue, 95) by bin(TimeGenerated, 5m), ServiceName
| make-series p95Series=avg(p95) on TimeGenerated from ago(7d) to now() step 5m by ServiceName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 7)
| where array_length(anomalies) > 0
Cosa ottieni out of the box
- Helm e YAML pronti da copiare per avviare Supervisor/Concierge + OTel Collector
- Due query di anomaly KQL production-ready
- Passaggi chiari per configurare alert di Azure Monitor e Logic App
Opzionale: policy e automazione (perché, quando, come)
Perché aggiungere questo livello
- Guardrail, non gate: previeni configurazioni rischiose prima che vengano applicate (admission) e intercetta il drift a runtime (eventi di policy nei log).
- Chiudi il cerchio con l'engineering: alert che si limitano a notificare gli umani allungano l'MTTR. Un sottile layer di automazione consente di arricchire → decidere → (eventualmente) agire in sicurezza.
- Controllo tracciabile: ogni azione automatizzata passa da Azure Monitor + Logic Apps con approvazioni e log.
Casi d'uso reali
Picco di sign-in sospetti (identità)
- Segnale: una query KQL su
SigninLogsrileva un outlier per un utente/app. - Automazione: alert → la Logic App arricchisce con rischio utente/geo → apre un ticket e (con approvazione) chiama Microsoft Graph per richiedere step-up MFA o un blocco temporaneo del sign-in.
Drift di pod privilegiati (runtime)
- Segnale: Kyverno/Gatekeeper segnala un pod con
privileged: trueoCAP_SYS_ADMIN. - Automazione: alert → la Logic App pubblica su Slack/Teams, apre un incident JIRA e (con approvazione) scala a 0 il deployment nel namespace coinvolto.
Immagine non firmata / registry errato (supply chain)
- Segnale: la policy di admission rifiuta immagini non provenienti da
my-acr.azurecr.ioo prive di cosignature. - Automazione: crea una deroga a breve termine (24h) solo previa approvazione; logga la deroga in LA.
Namespace senza owner/label (igiene operativa)
- Segnale: l'admission rifiuta la creazione del namespace per mancanza di
owner/costCenter. - Automazione: la Logic App contatta il richiedente con un comando
kubectl labelprecompilato.
Secret nelle env var (misconfig)
- Segnale: la policy rileva un manifest che referenzia secret in chiaro.
- Automazione: conversione a
Secret+ volume mount tramite PR bot (flusso GitOps) e apertura di un ticket di sicurezza.
Cosa serve installare (minimo)
- Admission (prevent/mutate): Kyverno oppure OPA Gatekeeper.
- Audit a runtime → log: emetti i risultati delle policy verso Log Analytics.
- Decisioning: regole di alert di Azure Monitor (da KQL o eventi di policy).
- Orchestrazione: Logic Apps (o Azure Functions) con approvazione umana dove l'impatto è elevato.
Policy iniziali (Kyverno)
Vieta i container privilegiati:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged
spec:
validationFailureAction: enforce
rules:
- name: no-priv
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: "false"
Richiedi le label di owner/cost center:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-owner-labels
spec:
validationFailureAction: enforce
rules:
- name: require-labels
match: { resources: { kinds: ["Namespace","Deployment","StatefulSet"] } }
validate:
message: "owner and costCenter labels are required."
pattern:
metadata:
labels:
owner: "?*"
costCenter: "?*"
Limita le immagini al tuo ACR:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-registries
spec:
validationFailureAction: enforce
rules:
- name: only-acr
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Images must come from my-acr.azurecr.io"
pattern:
spec:
containers:
- image: "my-acr.azurecr.io/*"
Meglio iniziare in modalità audit : imposta
validationFailureAction: auditper una settimana, fai tuning, poi passa aenforce
Flusso anomalia di identità
- Query KQL su
SigninLogs(vedi il post) → regola di alert (ogni 15 min). - Action Group: webhook Logic App + Teams/JIRA.
- Step della Logic App:
- Recupera dettagli utente e cronologia di sign-in (Graph).
- Verifica l'ultima MFA andata a buon fine.
- Branch:
- Impatto basso: notifica + ticket.
- Impatto alto: approvazione (Service Owner) → aggiornamento Graph
conditionalAccesso blocco temporaneo. - Registra l'esito in Log Analytics.
Flusso runtime/policy
- Kyverno → invia gli eventi di policy a una tabella di Log Analytics (via OTel o diagnostics di AKS).
- Alert KQL sulle nuove failure di enforcement per
disallow-privileged. - Logic App:
- Recupera i metadata di Deployment/Pod.
- Notifica al service owner lo snippet di remediation.
- Approvazione opzionale →
az aks command invokeoppure PR GitOps per revert/patch.
Quando soprassedere (per ora)
- Cluster singolo, team ridotto o ancora senza una cultura di on-call automation.
- Se non hai i privilegi Entra/Graph per applicare il conditional access, parti da observability + ticket e aggiungi l'enforcement in seguito.
Hai bisogno di supporto? Siamo qui per aiutarti.
Se sta valutando questo approccio per un proof of concept o sta pianificando i deployment, DoiT può affiancarla. Il nostro team di oltre 100 esperti è specializzato in soluzioni cloud su misura, pronto a guidarla nel processo e a ottimizzare la sua infrastruttura per compliance ed esigenze future.
Confrontiamoci su ciò che ha più senso per la sua azienda in questa fase di policy enforcement, per garantire un'infrastruttura cloud robusta, conforme e pronta al successo. Ci contatti oggi stesso.