Una POC práctica y de bajo costo que puedes montar en un fin de semana, con pasos de despliegue claros centrados en Azure.

imagen generada por IA (chatgpt5.0)
TL;DR
- Identidad: Convierte a Microsoft Entra ID en tu única fuente de verdad para las personas. Conéctalo a cualquier Kubernetes (AKS/EKS/GKE) con Pinniped (Supervisor + Concierge) para que todos los clusters acepten el inicio de sesión con Entra.
- Observabilidad: Instrumenta apps e infraestructura con OpenTelemetry → envía a Azure Monitor / Log Analytics.
- Detección: Usa KQL time-series ML (sin modelos personalizados) para identificar y detectar anomalías en los servicios.
- Acción: Conecta las alertas de Azure Monitor con Logic Apps/Azure Functions para una remediación segura y auditable.
Resultado: un plano de autenticación , una capa de observabilidad , un MTTR más rápido y controles zero-trust pragmáticos, sin tener que montar infraestructura de ML.
A quién va dirigido
Arquitectos de plataforma, SRE y seguridad que operan Kubernetes multicloud (AKS/EKS/GKE) y buscan:
- Un plano de identidad humana centralizado y auditable
- Telemetría estandarizada entre nubes
- Detección de anomalías con foco en costos y automatización segura
¿Qué problemas resuelve?
- Autenticación de usuarios fragmentada entre AKS/EKS/GKE → drift y trabajo manual.
- Telemetría en silos → detección inconsistente y respuesta lenta a incidentes.
- Levantar stacks de ML resulta caro y excesivo para muchas señales.
Objetivo: un patrón repetible que (1) centralice la identidad, (2) estandarice la telemetría, (3) detecte con KQL ML ligero y (4) automatice la remediación con guardarrieles.
Arquitectura de un vistazo
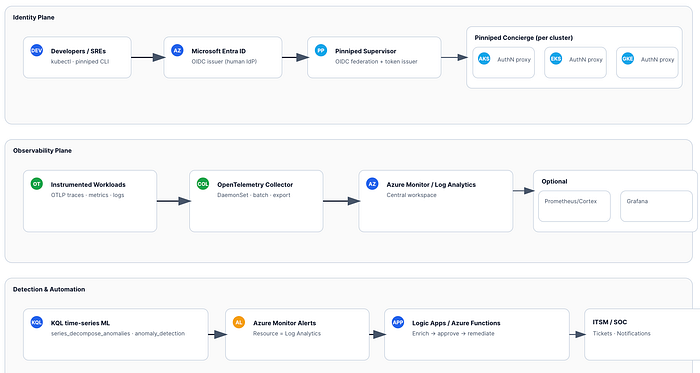
- Entra ID (IdP) → Pinniped Supervisor (emisor/federación OIDC) → Pinniped Concierge (por cluster).
- Los desarrolladores inician sesión con Entra una sola vez y obtienen tokens de Kubernetes de corta duración para AKS/EKS/GKE.
- Telemetría de aplicaciones e infraestructura mediante SDKs/auto-instrumentación de OpenTelemetry → OpenTelemetry Collector (DaemonSet) → Azure Monitor / Log Analytics (workspace central). Opcional: métricas con remote_write a Prometheus/Cortex y dashboards en Grafana.
- KQL
series_decompose_anomalies/anomaly_detectionpara anomalías de identidad y de servicio → alertas de Azure Monitor → Logic App/Azure Function para enriquecimiento y remediación.
Política y automatización (opcional)
- Kyverno/OPA Gatekeeper para políticas de admisión/runtime; alertas de Azure Monitor → Logic App / Azure Function para remediación orquestada (ticketing, Conditional Access, cuarentena).
Prerrequisitos centrados en Azure (alcance de la POC)
- Suscripción y Resource Group para monitoreo y servicios compartidos.
- Log Analytics Workspace (central).
- (Opcional) Application Insights (si prefieres vistas de telemetría de aplicaciones basadas en AI sobre LA).
- Tenant de Microsoft Entra con permisos para crear App Registrations.
- Azure Key Vault para secretos (client secret de la app de Entra; cadenas de conexión opcionales).
- kubectl + acceso a por lo menos un cluster (AKS para el recorrido en Azure; EKS/GKE más adelante).
- Helm para Pinniped y OpenTelemetry Collector.
Tip: mantén nombres y ubicaciones consistentes (por ejemplo,
rg-plat-shared,law-plat-central).
Despliegue rápido en Azure: paso a paso
Esta sección te lleva desde cero hasta señales y alertas, con foco en Azure. Después podrás extenderlo a EKS/GKE.
1) Crea los recursos centrales de monitoreo
Opción A — Azure CLI
# Variables
LOC=westeurope
RG=rg-plat-shared
LAW=law-plat-central
az group create -n $RG -l $LOC
az monitor log-analytics workspace create -g $RG -n $LAW -l $LOC# Obtén la información del workspace para más adelante
LAW_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query id -o tsv)
LAW_CUST_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query customerId -o tsv)
LAW_KEY=$(az monitor log-analytics workspace get-shared-keys -g $RG -n $LAW --query primarySharedKey -o tsv)
Opción B — Bicep (idempotente)
param location string = 'westeurope'
param rgName string = 'rg-plat-shared'
param workspaceName string = 'law-plat-central'
resource law 'Microsoft.OperationalInsights/workspaces@2022-10-01' = {
name: workspaceName
location: location
properties: {
retentionInDays: 30
features: {
searchVersion: 1
}
}
}
La retención impacta de lleno en el costo. Empieza con 30 días y ajusta según tus requisitos de cumplimiento.
2) Exporta los logs de inicio de sesión y auditoría de Entra a Log Analytics
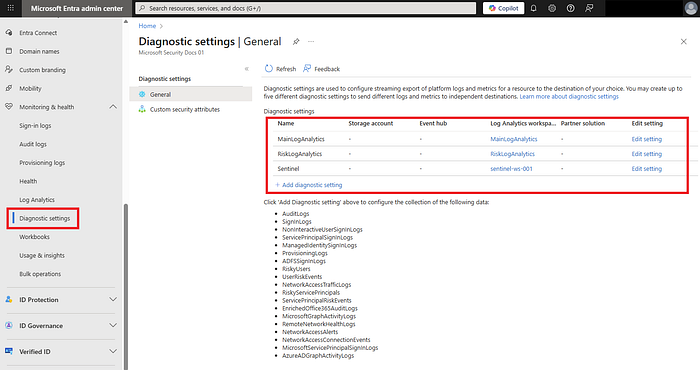
- En el centro de administración de Entra → Monitoring & health → Diagnostics settings → Add → envía SigninLogs y AuditLogs al Log Analytics Workspace que creaste.
- Verifica que la configuración esté habilitada y que los logs estén llegando ejecutando
SigninLogs | take 5después de 10 a 15 minutos.
3) Registra la app de Entra para Pinniped Supervisor
- App Registration: otorga
openid,profile,email,offline_access. - Agrega la Redirect URI para el callback del Supervisor (por ejemplo,
https://pinniped.<your-domain>/callback). - Crea un client secret → guárdalo en Key Vault.
- Anota el Tenant ID y el Client ID.
4) Despliega Pinniped en AKS (Supervisor + Concierge)
Puedes correr el Supervisor en un pequeño cluster de control compartido (recomendado) y desplegar Concierge en cada cluster de workloads (AKS/EKS/GKE).
Instalar Supervisor (Helm)
helm repo add pinniped https://pinniped.dev/helm-charts
helm repo update
kubectl create ns pinniped-supervisor
helm upgrade --install pinniped-supervisor pinniped/supervisor \
-n pinniped-supervisor \
--set service.type=LoadBalancer \
--set config.generateTLS=true
Crear FederationDomain (vincular a Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
identityProviders:
- name: azuread
type: OIDC
oidc:
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: https://pinniped.<your-domain> # URL pública del Supervisor
Guarda el client secret de Entra como un secreto de Kubernetes llamado
pinniped-azure-secretenpinniped-supervisor.
Instalar Concierge en los clusters de AKS
kubectl create ns pinniped-concierge
helm upgrade --install pinniped-concierge pinniped/concierge \
-n pinniped-concierge \
--set credentialIssuer.enable=true
Validar el login del desarrollador
- Desde la laptop del desarrollador:
pinniped login oidc --issuer https://pinniped.<your-domain> --ca-bundle <CA.pem> - Confirma que se genera un kubeconfig con tokens de corta duración y que
kubectl get podsfunciona contra AKS.
Repite la instalación de Concierge en EKS/GKE para unificar el inicio de sesión entre nubes.
5) Despliega OpenTelemetry Collector en AKS (con exportación a Azure Monitor)
Helm (collector genérico)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
kubectl create ns observability
cat <<'EOF' > values-otel.yaml
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
EOFhelm upgrade --install otel-collector open-telemetry/opentelemetry-collector -n observability -f values-otel.yaml
¿De dónde sale el connection string? En Azure, abre tu recurso de Application Insights → Overview → Connection string . Puedes enviar directamente a Log Analytics mediante Data Collection Endpoints/Rules, pero AI es la vía más sencilla para los traces de aplicaciones.
Etiqueta y muestrea la telemetría
- Agrega atributos de recurso:
service.name,service.namespace,deployment.environment,team,costCenter. - Empieza con tail-based sampling (10–20 %) para los traces; mantén una resolución de 1–5 minutos para las métricas.
A. Anomalía de identidad (picos): excluye ruido, suma "viaje imposible" y dimensiona por usuario
Lo nuevo:
- Excluye cuentas de servicio y break-glass
- Usa una línea base móvil de 7 días con estacionalidad de 24 h
- Suma enriquecimiento geográfico + verificación opcional de viaje imposible
- Genera un payload limpio listo para enrutar alertas
// ---- Parámetros
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
let sensitivity = 95; // 90–99; mayor = menos alertas
let serviceAccounts = dynamic(["svc_", "automaton@", "spn-"]); // prefijos/marcadores a excluir
// ---- Principal
SigninLogs
| where TimeGenerated > ago(lookback)
| where ResultType != 0 // solo fallos
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (serviceAccounts)) // excluye svc/breakglass
| summarize failed=count(),
ips = make_set(IPAddress, 4),
apps = make_set(AppDisplayName, 4)
by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed)
on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend decomp = series_decompose(failedSeries, 24) // modela el patrón diario
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime),
failedSeries to typeof(double),
decomp to typeof(dynamic),
anomalies to typeof(double)
| where anomalies > 0
// ---- Geo opcional + viaje imposible
| join kind=leftouter (
SigninLogs
| where TimeGenerated > ago(lookback)
| summarize arg_max(TimeGenerated, *) by UserId, IPAddress
| project UserPrincipalName, IPAddress, Country = LocationDetails.countryOrRegion, Latitude = todouble(LocationDetails.geoCoordinates.latitude), Longitude = todouble(LocationDetails.geoCoordinates.longitude)
) on $left.UPN == $right.UserPrincipalName
| project TimeGenerated, UPN, failed=failedSeries, IPs=ips, Apps=apps, Country, Latitude, Longitude, anomalyScore=anomalies
| order by anomalyScore desc
Complemento opcional de "viaje imposible" (saltos geográficos por pares > 1.500 km en < 2 h):
let minKm = 1500.0;
let maxHours = 2.0;
let toRad = (d:real) { d * pi() / 180.0 };
let haversine = (lat1:real, lon1:real, lat2:real, lon2:real) {
let dlat = toRad(lat2 - lat1);
let dlon = toRad(lon2 - lon1);
let a = pow(sin(dlat/2),2) + cos(toRad(lat1)) * cos(toRad(lat2)) * pow(sin(dlon/2),2);
6371.0 * 2 * asin(sqrt(a)) // km
};
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType == 0
| project UPN = UserPrincipalName, TimeGenerated, Lat = todouble(LocationDetails.geoCoordinates.latitude), Lon = todouble(LocationDetails.geoCoordinates.longitude)
| where isnotempty(Lat) and isnotempty(Lon)
| serialize
| extend prevTime = prev(TimeGenerated), prevLat = prev(Lat), prevLon = prev(Lon), prevUPN = prev(UPN)
| where UPN == prevUPN
| extend hrs = real(datetime_diff("minute", TimeGenerated, prevTime)) / 60.0
| extend km = haversine(prevLat, prevLon, Lat, Lon)
| where hrs > 0 and km / hrs > (minKm / maxHours)
| project TimeGenerated, UPN, km, hrs, speedKmh = km/hrs
Tip: deja la anomalía de identidad y el viaje imposible como alertas separadas ; enruta esta última a una severidad mayor.
B. Anomalías de servicio: alinéalas con tus tablas de datos y suma tasa de error + SLO burn
Si envías la telemetría de aplicaciones mediante Application Insights (algo común con OTel→Azure Monitor), reemplaza Perf por estas tablas más completas:
Pico de latencia p95 (App Insights / OTel)
let window = 7d;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize p95 = percentile(duration, 95) by bin(timestamp, step), cloud_RoleName
| make-series p95Series = avg(p95) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 24)
| mv-expand timestamp to typeof(datetime), p95Series to typeof(real), anomalies to typeof(double)
| where anomalies > 0
| project timestamp, service=cloud_RoleName, p95_ms = toreal(p95Series), anomalyScore = anomalies
| order by anomalyScore desc
Pico en la tasa de error (más accionable que la latencia pura)
let window = 24h;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize total=count(), errors = countif(success == false) by bin(timestamp, step), cloud_RoleName
| extend errRate = todouble(errors)/todouble(total)
| make-series errSeries = avg(errRate) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(errSeries, 95, 24)
| mv-expand timestamp to typeof(datetime), errSeries to typeof(real), anomalies to typeof(double)
| where anomalies > 0 and errSeries > 0.02 // guardarriel: tasa de error >2 %
| project timestamp, service=cloud_RoleName, errorRate = round(errSeries*100.0, 2), anomalyScore = anomalies
| order by anomalyScore desc
SLO burn-rate (ventanas rápida/lenta): ideal para paginar
// Ejemplo: SLO de éxito del 99,9 %
let slo = 0.999;
let fast = 5m;
let slow = 1h;
let targetBurn = 14.4; // pagina cuando se está consumiendo 14,4x el error budget
let agg = (win:timespan) {
requests
| where timestamp > ago(win)
| summarize total=count(), errors=countif(success == false) by cloud_RoleName
| project cloud_RoleName, errRate = todouble(errors)/todouble(total)
};let fastW = agg(fast);
let slowW = agg(slow);fastW
| join kind=inner slowW on cloud_RoleName
| extend burnFast = (1.0 - slo) == 0 ? 0.0 : errRate_left / (1.0 - slo),
burnSlow = (1.0 - slo) == 0 ? 0.0 : errRate_right / (1.0 - slo)
| extend burnRate = burnFast / burnSlow
| where burnRate > targetBurn and errRate_left > (1.0 - slo)
| project service=cloud_RoleName, burnRate=round(burnRate,2), errRateFast=round(errRate_left*100,3), errRateSlow=round(errRate_right*100,3)
Si dependes de la tabla
Perf(Legacy/VM/Container Insights), replica la misma lógica sobreInsightsMetricso sobre tu nombre de métrica personalizado en lugar derequests.
C. Empaqueta como funciones KQL reutilizables (alertas más limpias)
Guárdalas en tu workspace como funciones para que las reglas de alerta queden ordenadas:
// función detect_failed_signin_anomalies(sensitivity:int, exclude:dynamic)
.create-or-alter function with (folder = "detections") detect_failed_signin_anomalies(sensitivity:int=95, exclude:dynamic=dynamic(["svc_"])) {
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType != 0
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (exclude))
| summarize failed=count() by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed) on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime), failedSeries to typeof(double), anomalies to typeof(double)
| where anomalies > 0
| project TimeGenerated, UPN, failed=failedSeries, anomalyScore=anomalies
}
Y tu consulta de alerta queda así de simple:
detections.detect_failed_signin_anomalies(96, dynamic(["svc_","breakglass@"]))
7) Alertas: que sean accionables, con poco ruido y fáciles de enrutar
Aprovecha estas funciones de Azure Monitor:
- Split-by dimensions: crea una alerta por UPN o por servicio (dimensión =
UPN/cloud_RoleName). Así se evita el spam con varios sujetos y se enruta automáticamente al equipo o usuario correcto. - Frecuencia y lookback: empieza con frecuencia de 15 min y lookback de 60 min; pasa a 5 min cuando esté estable.
- Número de violaciones: exige ≥2 evaluaciones consecutivas antes de disparar para evitar destellos de un solo bin.
- Action Rules: silencia durante ventanas de mantenimiento o periodos ruidosos conocidos (por ejemplo, despliegues grandes).
- Propiedades personalizadas: agrega UPN/servicio, anomaly score y la última IP/geo al payload de la alerta (excelente para Logic Apps).
- Dos niveles: crea Severity 2 (paginar) para SLO burn y Severity 3–4 (notificar) para anomalías simples.
Campos a incluir en el payload de la alerta (custom details):
entity:UPNoservicesignal:failed_signin_anomaly/latency_p95_anomaly/error_rate_spikescore: anomaly scorecontext: las últimas 3 IPs o países, o los endpoints con más fallosrunbook: enlace al documento de remediación
Conexión del Action Group:
- Webhook a Logic App (principal)
- Canal de Teams/Slack del equipo dueño (basado en dimensión)
- Conector ITSM (creación automática de tickets)
Primeros pasos en Logic App (recomendado):
- Deduplica/silencia si ya existe un incidente activo para la misma combinación
entity+signal. - Enriquece (Graph para usuarios; Azure Resource Graph / GitOps para servicios).
- Enruta:
- Bajo impacto → solo notificar y abrir ticket
- Alto impacto → aprobación y luego acción (exigir MFA / bloquear; rollback/escalar a 0; revertir PR)
Pequeños ajustes de calidad de vida con gran impacto
- Gráficas para revisores: agrega un workbook fijado o la línea
render timecharta las consultas que triagueas a mano.
| project timestamp=TimeGenerated, failed=failedSeries
| render timechart
- Guardarrieles contra ruido: en consultas de anomalías, agrega umbrales absolutos mínimos (por ejemplo,
failedSeries >= 5) para que los destellos pequeños no disparen alertas. - Sensibilidad en feriados/fines de semana: si ves falsos positivos estacionales, baja
sensitivitylos fines de semana o excluye días festivos con una pequeña tabla de lookup. - Registro de cuentas de servicio: mantén una lista central y consúmela mediante
externaldata()desde una URL de blob/gh raw para que los analistas puedan actualizarla sin tocar las consultas.
- Abre Azure Monitor → Logs → ejecuta una consulta.
- Haz clic en New alert rule → define Resource = Log Analytics workspace.
- Condition = tu consulta con umbral en resultados > 0.
- Action group = email/SMS/ITSM + webhook de Logic App.
- Severity / Evaluation frequency = empieza conservador (por ejemplo, cada 15 min).
8) Automatización segura con Logic Apps / Functions
- La Logic App recibe la alerta → enriquece el contexto (riesgo del usuario, geo, últimos éxitos, salud del servicio) → decide el camino:
- Solo notificar (las primeras semanas) con ticket en ITSM.
- Acción con guardarrieles (con aprobación) usando Microsoft Graph (por ejemplo, exigir MFA, bloqueo temporal de inicio de sesión) o cambios de RBAC en Kubernetes.
- Todos los cambios deben ser auditables y limitados por privilegio mínimo (ver más abajo).
Cómo extenderlo a EKS/GKE
- Reutiliza el Supervisor; instala Concierge en cada cluster.
- Mantén un OpenTelemetry Collector por cluster; expórtalo al mismo workspace de Azure (etiqueta con
cloud.provider). - Reutiliza las mismas consultas KQL entre nubes; pivotea por
cloud_RoleName/k8s.cluster.name.
Riesgos y mitigaciones
- Falsos positivos : empieza en modo notificación; itera la sensibilidad y las ventanas.
- Radio de impacto de la automatización: exige aprobación manual para los pasos de alto impacto; rollout progresivo.
- Exposición del Supervisor: colócalo detrás de un WAF, restringe los rangos de IP y aplica TLS y HSTS.
- Privilegio mínimo: los scopes de Graph se limitan a las acciones que automatizas; el RBAC de Azure para la Function/Logic App sigue el principio de privilegio mínimo.
Costo y licenciamiento
- Costo principal: ingesta y retención de logs. Contrólalo con sampling y retención de 30 a 90 días.
- KQL ML: sin costo separado de infraestructura de ML.
- Entra P2 (opcional): aporta señales de riesgo nativas; tus detecciones en KQL son un control compensatorio si no cuentas con P2.
- Pinniped: liviano; el costo de infraestructura es despreciable comparado con el de los logs.
Snippets listos para copiar (apéndice)
FederationDomain (Supervisor ↔ Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
issuer: https://pinniped.<your-domain>
identityProviders:
- name: azuread
type: OIDC
oidc:
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
OTel Collector mínimo (a Azure Monitor)
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
KQL — anomalía de identidad
SigninLogs
| where TimeGenerated > ago(14d)
| where ResultType != 0
| summarize failed=count() by bin(TimeGenerated, 1h), UserPrincipalName
| make-series failedSeries=avg(failed) on TimeGenerated from ago(7d) to now() step 1h by UserPrincipalName
| extend anomalies = series_decompose_anomalies(failedSeries, 95, 7)
| where array_length(anomalies) > 0
KQL — anomalía de latencia de servicio
Perf
| where TimeGenerated > ago(7d) and CounterName == "request_duration_ms"
| summarize p95 = percentile(CounterValue, 95) by bin(TimeGenerated, 5m), ServiceName
| make-series p95Series=avg(p95) on TimeGenerated from ago(7d) to now() step 5m by ServiceName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 7)
| where array_length(anomalies) > 0
Lo que te llevas listo para usar
- Helm y YAML listos para copiar y pegar para levantar Supervisor/Concierge + OTel Collector
- Dos consultas KQL listas para producción de detección de anomalías
- Pasos claros para conectar alertas de Azure Monitor con Logic Apps
Opcional: política y automatización (por qué, cuándo y cómo)
Por qué sumarlo
- Guardarrieles, no barreras: previene configuraciones riesgosas antes de que se ejecuten (admisión) y detecta drift en runtime (eventos de política a logs).
- Cierra el ciclo: las alertas que solo paginan humanos alargan el MTTR. Una capa fina de automatización te permite enriquecer → decidir → (opcionalmente) actuar de forma segura.
- Control auditable: cada acción automatizada pasa por Azure Monitor + Logic Apps con aprobaciones y registros.
Casos de uso reales
Pico sospechoso de inicios de sesión (identidad)
- Señal: KQL sobre
SigninLogsmarca un outlier para un usuario o app. - Automatización: alerta → la Logic App enriquece con riesgo del usuario y geo → abre un ticket y (con aprobación) llama a Microsoft Graph para exigir step-up MFA o un bloqueo temporal de inicio de sesión.
Drift de pod privilegiado (runtime)
- Señal: Kyverno/Gatekeeper reporta un pod con
privileged: trueoCAP_SYS_ADMIN. - Automatización: alerta → la Logic App publica en Slack/Teams, abre un incidente en JIRA y (con aprobación) escala el deployment a 0 en el namespace afectado.
Imagen sin firmar / registry incorrecto (cadena de suministro)
- Señal: la política de admisión rechaza imágenes que no provienen de
my-acr.azurecr.ioo que no tienen una cosignature. - Automatización: crea una excepción de corta duración (24 h) solo si un aprobador da el visto bueno; registra la excepción en LA.
Namespace sin owner/labels (higiene operativa)
- Señal: la admisión rechaza la creación del namespace por falta de
owner/costCenter. - Automatización: la Logic App contacta al solicitante con un comando
kubectl labelprellenado.
Secretos en variables de entorno (mala configuración)
- Señal: la política audita un manifiesto que referencia secretos en texto plano.
- Automatización: convierte a
Secret+ montaje de volumen mediante un PR bot (flujo GitOps) y abre un ticket de seguridad.
Qué desplegar (lo mínimo)
- Admisión (prevenir/mutar): Kyverno u OPA Gatekeeper.
- Auditoría en runtime → logs: emite los resultados de las políticas a Log Analytics.
- Decisión: reglas de alerta de Azure Monitor (a partir de KQL o eventos de política).
- Orquestación: Logic Apps (o Azure Functions) con aprobación humana donde el impacto sea alto.
Políticas iniciales (Kyverno)
Denegar contenedores privilegiados:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged
spec:
validationFailureAction: enforce
rules:
- name: no-priv
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: "false"
Exigir labels de owner y centro de costo:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-owner-labels
spec:
validationFailureAction: enforce
rules:
- name: require-labels
match: { resources: { kinds: ["Namespace","Deployment","StatefulSet"] } }
validate:
message: "owner and costCenter labels are required."
pattern:
metadata:
labels:
owner: "?*"
costCenter: "?*"
Restringir las imágenes a tu ACR:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-registries
spec:
validationFailureAction: enforce
rules:
- name: only-acr
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Images must come from my-acr.azurecr.io"
pattern:
spec:
containers:
- image: "my-acr.azurecr.io/*"
Mejor en modo audit primero: configura
validationFailureAction: auditdurante una semana, ajusta y luego pasa aenforce.
Flujo de anomalía de identidad
- Consulta KQL sobre
SigninLogs(la del post) → regla de alerta (cada 15 min). - Action Group: webhook de Logic App + Teams/JIRA.
- Pasos de la Logic App:
- Obtiene los detalles del usuario y su historial de inicios de sesión (Graph).
- Verifica el último MFA exitoso reciente.
- Bifurca:
- Bajo impacto: notifica y crea ticket.
- Alto impacto: aprobación (Service Owner) → actualización de
conditionalAccessen Graph o bloqueo temporal. - Registra el resultado en Log Analytics.
Flujo de runtime/política
- Kyverno → envía los eventos de política a una tabla de Log Analytics (mediante OTel o diagnostics de AKS).
- Alerta KQL ante nuevos fallos de enforcement de
disallow-privileged. - Logic App:
- Obtiene los metadatos del Deployment/Pod.
- Notifica al service owner con el snippet de remediación.
- Aprobación opcional →
az aks command invokeo un PR de GitOps para revertir o parchar.
Cuándo dejarlo para después
- Cluster único, equipo pequeño o cuando todavía no hay cultura de automatización on-call.
- Si te faltan privilegios en Entra/Graph para aplicar conditional access, empieza con observabilidad + tickets y suma el enforcement más adelante.
¿Necesitas ayuda? Estamos para acompañarte.
Si estás evaluando esto para una prueba de concepto o planeando despliegues, DoiT puede ayudarte. Nuestro equipo de más de 100 expertos se especializa en soluciones cloud a la medida y está listo para acompañarte en el proceso y optimizar tu infraestructura para el cumplimiento y las demandas a futuro.
Conversemos sobre lo que tiene más sentido para tu empresa en esta etapa de aplicación de políticas, para que tu infraestructura cloud sea robusta, conforme y esté optimizada para el éxito. Contáctanos hoy.