Uma POC prática e de baixo custo que dá para rodar em um fim de semana — com passos claros de deploy começando pelo Azure

imagem gerada por IA (chatgpt5.0)
TL;DR
- Identidade: use o Microsoft Entra ID como fonte única da verdade para humanos. Conecte-o a qualquer Kubernetes (AKS/EKS/GKE) com o Pinniped (Supervisor + Concierge) para que todos os clusters aceitem login pelo Entra.
- Observabilidade: instrumente apps e infra com OpenTelemetry → envie para o Azure Monitor / Log Analytics.
- Detecção: use ML de séries temporais do KQL (sem modelos customizados) para identificar e detectar anomalias em serviços.
- Ação: conecte os alertas do Azure Monitor a Logic Apps/Azure Functions para uma remediação segura e auditável.
Resultado: um plano de autenticação , uma malha de observabilidade , MTTR menor e controles pragmáticos de zero-trust — sem precisar montar uma infra de ML.
Para quem é este artigo
Arquitetos de plataforma, SRE e segurança que rodam Kubernetes multicloud (AKS/EKS/GKE) e querem:
- Um plano de identidade humana centralizado e auditável
- Telemetria padronizada entre nuvens
- Detecção de anomalias com custo sob controle e automação segura
Que problemas isso resolve?
- Autenticação fragmentada entre AKS/EKS/GKE → drift e trabalho manual.
- Telemetria em silos → detecção inconsistente e resposta lenta a incidentes.
- Subir uma stack de ML é caro e exagerado para boa parte dos sinais.
Objetivo: um padrão repetível que (1) centralize identidade, (2) padronize telemetria, (3) detecte com ML leve em KQL e (4) automatize a remediação com salvaguardas.
Visão geral da arquitetura
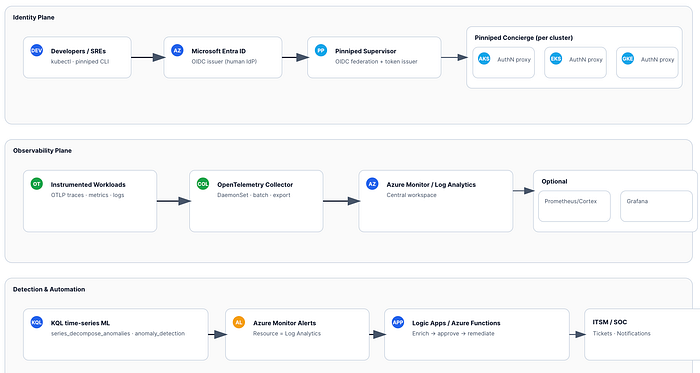
- Entra ID (IdP) → Pinniped Supervisor (emissor/federação OIDC) → Pinniped Concierge (por cluster).
- O desenvolvedor faz login no Entra uma vez e recebe tokens de Kubernetes de curta duração para AKS/EKS/GKE.
- Telemetria de app/infra via SDKs/auto-instrumentação do OpenTelemetry → OpenTelemetry Collector (DaemonSet) → Azure Monitor / Log Analytics (workspace central). Opcional: remote_write de métricas para Prometheus/Cortex e dashboards no Grafana.
- KQL
series_decompose_anomalies/anomaly_detectionpara anomalias de identidade e serviço → alertas do Azure Monitor → Logic App/Azure Function para enriquecimento e remediação.
Política e automação (opcional)
- Kyverno/OPA Gatekeeper para políticas de admissão/runtime; alertas do Azure Monitor → Logic App / Azure Function para remediação orquestrada (abertura de tickets, Conditional Access, quarentena).
Pré-requisitos no Azure (escopo da POC)
- Subscription e Resource Group para monitoramento e serviços compartilhados.
- Log Analytics Workspace (central).
- (Opcional) Application Insights (caso prefira visualizações de telemetria de aplicação baseadas em AI sobre o LA).
- Tenant do Microsoft Entra com permissão para criar App Registrations.
- Azure Key Vault para segredos (client secret do app no Entra; opcionalmente, connection strings).
- kubectl + acesso a pelo menos um cluster (AKS para o passo a passo no Azure; EKS/GKE vêm depois).
- Helm para Pinniped e OpenTelemetry Collector.
Dica: mantenha nomes e locations consistentes (ex.:
rg-plat-shared,law-plat-central).
Deploy rápido no Azure — passo a passo
Esta seção te leva do zero a sinais e alertas, com foco no Azure. Depois, é só estender para EKS/GKE.
1) Criar os recursos centrais de monitoramento
Opção A — Azure CLI
# Variáveis
LOC=westeurope
RG=rg-plat-shared
LAW=law-plat-central
az group create -n $RG -l $LOC
az monitor log-analytics workspace create -g $RG -n $LAW -l $LOC# Capture as informações do workspace para uso posterior
LAW_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query id -o tsv)
LAW_CUST_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query customerId -o tsv)
LAW_KEY=$(az monitor log-analytics workspace get-shared-keys -g $RG -n $LAW --query primarySharedKey -o tsv)
Opção B — Bicep (idempotente)
param location string = 'westeurope'
param rgName string = 'rg-plat-shared'
param workspaceName string = 'law-plat-central'
resource law 'Microsoft.OperationalInsights/workspaces@2022-10-01' = {
name: workspaceName
location: location
properties: {
retentionInDays: 30
features: {
searchVersion: 1
}
}
}
A retenção é o que mais pesa no custo. Comece com 30 dias e ajuste conforme a conformidade.
2) Exportar logs de sign-in/auditoria do Entra para o Log Analytics
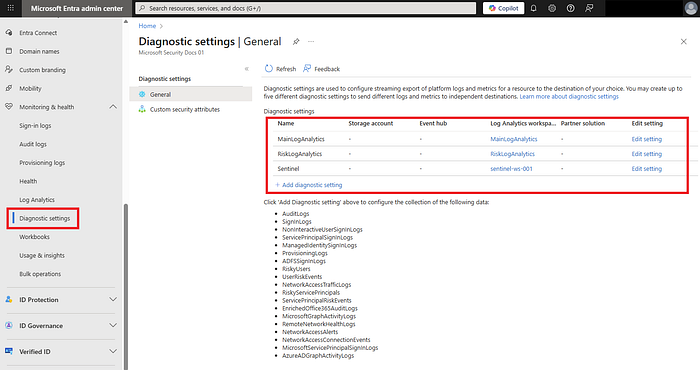
- No Entra admin center → Monitoring & health → Diagnostics settings → Add → envie SigninLogs e AuditLogs para o Log Analytics Workspace que você criou.
- Confirme que a configuração está habilitada e que os logs estão chegando rodando
SigninLogs | take 5depois de 10 a 15 minutos.
3) Registrar o app do Entra para o Pinniped Supervisor
- App Registration: conceda
openid,profile,email,offline_access. - Adicione a Redirect URI para o callback do Supervisor (ex.:
https://pinniped.<seu-dominio>/callback). - Crie um client secret → guarde no Key Vault.
- Anote o Tenant ID e o Client ID.
4) Subir o Pinniped no AKS (Supervisor + Concierge)
Você pode rodar o Supervisor em um cluster de controle pequeno e compartilhado (recomendado) e instalar o Concierge em cada cluster de workload (AKS/EKS/GKE).
Instalar o Supervisor (Helm)
helm repo add pinniped https://pinniped.dev/helm-charts
helm repo update
kubectl create ns pinniped-supervisor
helm upgrade --install pinniped-supervisor pinniped/supervisor \
-n pinniped-supervisor \
--set service.type=LoadBalancer \
--set config.generateTLS=true
Criar o FederationDomain (link com o Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
identityProviders:
- name: azuread
type: OIDC
oidc:
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: https://pinniped.<seu-dominio> # URL pública do Supervisor
Guarde o client secret do Entra como um secret do Kubernetes chamado
pinniped-azure-secretno namespacepinniped-supervisor.
Instalar o Concierge no(s) cluster(s) AKS
kubectl create ns pinniped-concierge
helm upgrade --install pinniped-concierge pinniped/concierge \
-n pinniped-concierge \
--set credentialIssuer.enable=true
Validar o login do desenvolvedor
- Da máquina de um dev:
pinniped login oidc --issuer https://pinniped.<seu-dominio> --ca-bundle <CA.pem> - Confirme que um kubeconfig com tokens de curta duração foi gerado e que
kubectl get podsfunciona contra o AKS.
Repita a instalação do Concierge no EKS/GKE para unificar o login entre nuvens.
5) Subir o OpenTelemetry Collector no AKS (exportando para o Azure Monitor)
Helm (collector genérico)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
kubectl create ns observability
cat <<'EOF' > values-otel.yaml
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
EOFhelm upgrade --install otel-collector open-telemetry/opentelemetry-collector -n observability -f values-otel.yaml
Onde acho a connection string? No Azure, abra o recurso de Application Insights → Overview → Connection string . Dá para enviar direto ao Log Analytics via Data Collection Endpoints/Rules, mas o AI é o caminho mais simples para traces de aplicação.
Tags e amostragem de telemetria
- Adicione resource attributes:
service.name,service.namespace,deployment.environment,team,costCenter. - Comece com tail-based sampling (10–20%) para traces; mantenha resolução de 1 a 5 min para métricas
A. Anomalia de identidade (picos) — corte o ruído, adicione "impossible travel" e dimensione por usuário
O que mudou:
- Exclui contas de serviço/break-glass
- Usa uma baseline móvel de 7 dias com sazonalidade de 24h
- Adiciona enriquecimento geográfico + verificação opcional de impossible travel
- Gera um payload limpo, pronto para o roteamento de alertas
// ---- Parâmetros
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
let sensitivity = 95; // 90–99; maior = menos alertas
let serviceAccounts = dynamic(["svc_", "automaton@", "spn-"]); // prefixos/marcadores a excluir
// ---- Principal
SigninLogs
| where TimeGenerated > ago(lookback)
| where ResultType != 0 // somente falhas
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (serviceAccounts)) // exclui svc/breakglass
| summarize failed=count(),
ips = make_set(IPAddress, 4),
apps = make_set(AppDisplayName, 4)
by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed)
on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend decomp = series_decompose(failedSeries, 24) // modela o padrão diário
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime),
failedSeries to typeof(double),
decomp to typeof(dynamic),
anomalies to typeof(double)
| where anomalies > 0
// ---- Geo opcional + impossible travel
| join kind=leftouter (
SigninLogs
| where TimeGenerated > ago(lookback)
| summarize arg_max(TimeGenerated, *) by UserId, IPAddress
| project UserPrincipalName, IPAddress, Country = LocationDetails.countryOrRegion, Latitude = todouble(LocationDetails.geoCoordinates.latitude), Longitude = todouble(LocationDetails.geoCoordinates.longitude)
) on $left.UPN == $right.UserPrincipalName
| project TimeGenerated, UPN, failed=failedSeries, IPs=ips, Apps=apps, Country, Latitude, Longitude, anomalyScore=anomalies
| order by anomalyScore desc
Complemento opcional de "impossible travel" (saltos geográficos > 1.500 km em < 2 h):
let minKm = 1500.0;
let maxHours = 2.0;
let toRad = (d:real) { d * pi() / 180.0 };
let haversine = (lat1:real, lon1:real, lat2:real, lon2:real) {
let dlat = toRad(lat2 - lat1);
let dlon = toRad(lon2 - lon1);
let a = pow(sin(dlat/2),2) + cos(toRad(lat1)) * cos(toRad(lat2)) * pow(sin(dlon/2),2);
6371.0 * 2 * asin(sqrt(a)) // km
};
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType == 0
| project UPN = UserPrincipalName, TimeGenerated, Lat = todouble(LocationDetails.geoCoordinates.latitude), Lon = todouble(LocationDetails.geoCoordinates.longitude)
| where isnotempty(Lat) and isnotempty(Lon)
| serialize
| extend prevTime = prev(TimeGenerated), prevLat = prev(Lat), prevLon = prev(Lon), prevUPN = prev(UPN)
| where UPN == prevUPN
| extend hrs = real(datetime_diff("minute", TimeGenerated, prevTime)) / 60.0
| extend km = haversine(prevLat, prevLon, Lat, Lon)
| where hrs > 0 and km / hrs > (minKm / maxHours)
| project TimeGenerated, UPN, km, hrs, speedKmh = km/hrs
Dica: mantenha anomalia de identidade e impossible travel como alertas separados ; encaminhe o segundo para uma severidade maior.
B. Anomalias de serviço — alinhe às suas tabelas de dados e adicione taxa de erro + SLO burn
Se você envia telemetria de aplicação via Application Insights (comum em OTel→Azure Monitor), troque Perf por estas tabelas mais ricas:
Pico de latência p95 (App Insights / OTel)
let window = 7d;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize p95 = percentile(duration, 95) by bin(timestamp, step), cloud_RoleName
| make-series p95Series = avg(p95) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 24)
| mv-expand timestamp to typeof(datetime), p95Series to typeof(real), anomalies to typeof(double)
| where anomalies > 0
| project timestamp, service=cloud_RoleName, p95_ms = toreal(p95Series), anomalyScore = anomalies
| order by anomalyScore desc
Pico na taxa de erro (mais acionável que latência pura)
let window = 24h;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize total=count(), errors = countif(success == false) by bin(timestamp, step), cloud_RoleName
| extend errRate = todouble(errors)/todouble(total)
| make-series errSeries = avg(errRate) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(errSeries, 95, 24)
| mv-expand timestamp to typeof(datetime), errSeries to typeof(real), anomalies to typeof(double)
| where anomalies > 0 and errSeries > 0.02 // guardrail: >2% de taxa de erro
| project timestamp, service=cloud_RoleName, errorRate = round(errSeries*100.0, 2), anomalyScore = anomalies
| order by anomalyScore desc
SLO burn-rate (janelas rápida/lenta) — ótimo para paging
// Exemplo: SLO de 99,9% de sucesso
let slo = 0.999;
let fast = 5m;
let slow = 1h;
let targetBurn = 14.4; // dispara o page quando o consumo do error budget chega a 14,4x
let agg = (win:timespan) {
requests
| where timestamp > ago(win)
| summarize total=count(), errors=countif(success == false) by cloud_RoleName
| project cloud_RoleName, errRate = todouble(errors)/todouble(total)
};let fastW = agg(fast);
let slowW = agg(slow);fastW
| join kind=inner slowW on cloud_RoleName
| extend burnFast = (1.0 - slo) == 0 ? 0.0 : errRate_left / (1.0 - slo),
burnSlow = (1.0 - slo) == 0 ? 0.0 : errRate_right / (1.0 - slo)
| extend burnRate = burnFast / burnSlow
| where burnRate > targetBurn and errRate_left > (1.0 - slo)
| project service=cloud_RoleName, burnRate=round(burnRate,2), errRateFast=round(errRate_left*100,3), errRateSlow=round(errRate_right*100,3)
Se você realmente depende da tabela
Perf(Legacy/VM/Container Insights), aplique a mesma lógica emInsightsMetricsou no nome da sua métrica customizada em vez derequests.
C. Empacote como funções KQL reutilizáveis (alertas mais limpos)
Coloque essas funções no seu workspace para que as regras de alerta fiquem enxutas:
// função detect_failed_signin_anomalies(sensitivity:int, exclude:dynamic)
.create-or-alter function with (folder = "detections") detect_failed_signin_anomalies(sensitivity:int=95, exclude:dynamic=dynamic(["svc_"])) {
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType != 0
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (exclude))
| summarize failed=count() by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed) on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime), failedSeries to typeof(double), anomalies to typeof(double)
| where anomalies > 0
| project TimeGenerated, UPN, failed=failedSeries, anomalyScore=anomalies
}
Aí sua query de alerta vira simplesmente:
detections.detect_failed_signin_anomalies(96, dynamic(["svc_","breakglass@"]))
7) Alertas — torne-os acionáveis, com pouco ruído e fáceis de rotear
Use estes recursos do Azure Monitor:
- Split-by dimensions: crie um alerta por UPN ou por serviço (dimensão =
UPN/cloud_RoleName). Isso evita spam de múltiplos assuntos e permite roteamento automático para o time/usuário certo. - Frequência e lookback: comece com frequência de 15 min e lookback de 60 min; passe para 5 min quando estabilizar.
- Número de violações: exija ≥2 avaliações consecutivas antes de disparar para evitar picos pontuais.
- Action Rules: silencie alertas em janelas de manutenção / períodos sabidamente ruidosos (ex.: deploys grandes).
- Propriedades customizadas: inclua UPN/serviço, score da anomalia e último IP/geo no payload do alerta (ótimo para Logic Apps).
- Dois níveis: crie Severity 2 (page) para SLO burn e Severity 3–4 (notificação) para anomalias simples.
Campos para incluir no payload do alerta (custom details):
entity:UPNouservicesignal:failed_signin_anomaly/latency_p95_anomaly/error_rate_spikescore: score da anomaliacontext: últimos 3 IPs/países ou principais endpoints com falharunbook: link para o documento de remediação
Wiring do Action Group:
- Webhook para Logic App (principal)
- Canal no Teams/Slack do time responsável (baseado em dimensão)
- Conector ITSM (criação automática de tickets)
Primeiros passos no Logic App (recomendado):
- Deduplique/silencie se já houver um incidente ativo para o mesmo
entity+signal. - Enriqueça (Graph para usuário; Azure Resource Graph / GitOps para serviço).
- Roteie:
- Baixo impacto → só notificar + abrir ticket
- Alto impacto → aprovação e depois ação (exigir MFA / bloquear; rollback/scale-to-0; reverter PR)
Pequenos ajustes de qualidade de vida que fazem diferença
- Gráficos para quem revisa: adicione um workbook fixado ou a linha
render timechartnas queries que você triagia manualmente
| project timestamp=TimeGenerated, failed=failedSeries
| render timechart
- Guardrails contra ruído: nas queries de anomalia, adicione thresholds absolutos mínimos (ex.:
failedSeries >= 5) para que pequenos picos não disparem alerta. - Sensibilidade em feriados/fim de semana: se aparecerem falsos positivos sazonais, reduza a
sensitivitynos finais de semana ou exclua feriados via uma pequena tabela de lookup. - Registro de contas de serviço: mantenha uma lista central e puxe-a com
externaldata()a partir de uma URL raw do blob/gh, para que os analistas atualizem sem precisar editar queries.
- Abra Azure Monitor → Logs → execute uma query.
- Clique em New alert rule → defina Resource = workspace do Log Analytics.
- Condition = sua query com threshold de resultados > 0.
- Action group = e-mail/SMS/ITSM + webhook do Logic App.
- Severity/Evaluation frequency = comece conservador (ex.: a cada 15 min).
8) Automação segura com Logic Apps / Functions
- O Logic App recebe o alerta → enriquece o contexto (risco do usuário, geo, últimos sucessos, saúde do serviço) → decide o caminho:
- Apenas notificar (nas primeiras semanas) com ticket no ITSM.
- Ação com guardrails (com aprovação) usando o Microsoft Graph (ex.: exigir MFA, bloqueio temporário de sign-in) ou alterações de RBAC no Kubernetes.
- Toda mudança precisa ser auditável e operar sob o princípio do menor privilégio (veja abaixo).
Estendendo para EKS/GKE
- Reaproveite o Supervisor; instale o Concierge em cada cluster.
- Mantenha o OpenTelemetry Collector em cada cluster; exporte para o mesmo workspace do Azure (com tag
cloud.provider). - Reuse as mesmas queries KQL entre nuvens; faça pivot por
cloud_RoleName/k8s.cluster.name.
Riscos e mitigações
- Falsos positivos : comece em modo de notificação; ajuste sensibilidade e janelas em iterações.
- Raio de impacto da automação: exija aprovação manual em passos de alto impacto; faça rollout progressivo.
- Exposição do Supervisor: coloque atrás de WAF, restrinja faixas de IP e force TLS e HSTS.
- Menor privilégio: os scopes do Graph ficam limitados às ações que você automatiza; o Azure RBAC do Function/Logic App segue o princípio do menor privilégio.
Custo e licenciamento
- Custo principal: ingestão e retenção de logs. Controle via amostragem e retenção de 30 a 90 dias.
- ML do KQL: sem custo extra de infra de ML.
- Entra P2 (opcional): entrega sinais nativos de risco; suas detecções em KQL funcionam como controle compensatório se você não tiver o P2.
- Pinniped: leve; o custo de infra é desprezível perto do de logs.
Snippets prontos para copiar (apêndice)
FederationDomain (Supervisor ↔ Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
issuer: https://pinniped.<seu-dominio>
identityProviders:
- name: azuread
type: OIDC
oidc:
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
OTel Collector mínimo (para o Azure Monitor)
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
KQL — anomalia de identidade
SigninLogs
| where TimeGenerated > ago(14d)
| where ResultType != 0
| summarize failed=count() by bin(TimeGenerated, 1h), UserPrincipalName
| make-series failedSeries=avg(failed) on TimeGenerated from ago(7d) to now() step 1h by UserPrincipalName
| extend anomalies = series_decompose_anomalies(failedSeries, 95, 7)
| where array_length(anomalies) > 0
KQL — anomalia de latência de serviço
Perf
| where TimeGenerated > ago(7d) and CounterName == "request_duration_ms"
| summarize p95 = percentile(CounterValue, 95) by bin(TimeGenerated, 5m), ServiceName
| make-series p95Series=avg(p95) on TimeGenerated from ago(7d) to now() step 5m by ServiceName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 7)
| where array_length(anomalies) > 0
O que você ganha pronto para usar
- Helm e YAML prontos para colar e subir Supervisor/Concierge + OTel Collector
- Duas queries de anomalia em KQL prontas para produção
- Passos claros para conectar alertas do Azure Monitor e Logic App
Opcional: política e automação (por que, quando, como)
Por que adicionar isso
- Guardrails, não barreiras: impeça configurações arriscadas antes que rodem (admissão) e capture drift em runtime (eventos de política nos logs).
- Feche o ciclo: alertas que só chamam humanos aumentam o MTTR. Uma camada fina de automação permite enriquecer → decidir → (opcionalmente) agir com segurança.
- Controle auditável: toda ação automatizada passa por Azure Monitor + Logic Apps com aprovações e logs.
Casos de uso reais
Pico suspeito de sign-in (identidade)
- Sinal: KQL em
SigninLogssinaliza um outlier para um usuário/app. - Automação: alerta → o Logic App enriquece com risco/geo do usuário → abre um ticket e (com aprovação) chama o Microsoft Graph para exigir MFA step-up ou bloqueio temporário de sign-in.
Drift de pod privilegiado (runtime)
- Sinal: Kyverno/Gatekeeper reporta um pod com
privileged: trueouCAP_SYS_ADMIN. - Automação: alerta → o Logic App posta no Slack/Teams, abre incidente no JIRA e (com aprovação) escala o deployment para 0 no namespace afetado.
Imagem não assinada / registry errado (supply chain)
- Sinal: a política de admissão nega imagens que não vêm de
my-acr.azurecr.ioou que não têm cosignature. - Automação: cria uma exceção de curta duração (24h) só se um aprovador autorizar; registra a exceção no LA.
Namespace sem owner/labels (higiene operacional)
- Sinal: a admissão nega a criação do namespace por falta de
owner/costCenter. - Automação: o Logic App envia ao solicitante um comando
kubectl labelpré-preenchido.
Segredos em variáveis de ambiente (configuração incorreta)
- Sinal: a política audita um manifesto que referencia segredos em texto puro.
- Automação: converte para
Secret+ volume mount via PR bot (fluxo GitOps) e abre um ticket de segurança.
O que implantar (mínimo)
- Admissão (prevenir/mutar): Kyverno ou OPA Gatekeeper.
- Auditoria em runtime → logs: envie os resultados das políticas para o Log Analytics.
- Decisão: regras de alerta no Azure Monitor (a partir de KQL ou eventos de política).
- Orquestração: Logic Apps (ou Azure Functions) com aprovação humana onde o impacto for alto.
Políticas iniciais (Kyverno)
Negar containers privilegiados:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged
spec:
validationFailureAction: enforce
rules:
- name: no-priv
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: "false"
Exigir labels de owner/cost center:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-owner-labels
spec:
validationFailureAction: enforce
rules:
- name: require-labels
match: { resources: { kinds: ["Namespace","Deployment","StatefulSet"] } }
validate:
message: "owner and costCenter labels are required."
pattern:
metadata:
labels:
owner: "?*"
costCenter: "?*"
Restringir imagens ao seu ACR:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-registries
spec:
validationFailureAction: enforce
rules:
- name: only-acr
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Images must come from my-acr.azurecr.io"
pattern:
spec:
containers:
- image: "my-acr.azurecr.io/*"
Comece pelo modo audit : defina
validationFailureAction: auditpor uma semana, ajuste e depois mude paraenforce
Fluxo de anomalia de identidade
- Query KQL em
SigninLogs(a do post) → Alert rule (a cada 15 min). - Action Group: webhook para Logic App + Teams/JIRA.
- Passos do Logic App:
- Buscar detalhes do usuário + histórico de sign-in (Graph).
- Verificar o MFA recente bem-sucedido.
- Branch:
- Baixo impacto: notificar + ticket.
- Alto impacto: aprovação (Service Owner) → atualização do
conditionalAccessvia Graph ou bloqueio temporário. - Registrar o resultado de volta no Log Analytics.
Fluxo de runtime/política
- Kyverno → envia eventos de política para uma tabela do Log Analytics (via OTel ou diagnostics do AKS).
- Alerta KQL para novas falhas de enforcement em
disallow-privileged. - Logic App:
- Puxar metadados do Deployment/Pod.
- Notificar o service owner com o snippet de remediação.
- Aprovação opcional →
az aks command invokeou PR via GitOps para reverter/corrigir.
Quando deixar para depois
- Cluster único, time pequeno ou ainda sem cultura de automação on-call.
- Se você não tem privilégios no Entra/Graph para aplicar conditional access — comece com observabilidade + tickets e adicione enforcement depois.
Precisa de uma ajuda? Conte com a gente.
Se você está avaliando isso para uma prova de conceito ou planejando implantações, a DoiT pode ajudar. Nosso time tem mais de 100 especialistas em soluções de nuvem sob medida, prontos para te guiar pelo processo e otimizar sua infraestrutura para conformidade e demandas futuras.
Vamos conversar sobre o que faz mais sentido para sua empresa nessa fase de aplicação de políticas, garantindo que sua infraestrutura de nuvem fique robusta, em conformidade e otimizada para o sucesso. Fale com a gente hoje mesmo.