Ein praxisnaher, kostengünstiger POC, den Sie an einem Wochenende umsetzen können – inklusive klarer Azure-first-Deployment-Schritte

Bild generiert mit KI (ChatGPT 5.0)
TL;DR
- Identität: Machen Sie Microsoft Entra ID zur Single Source of Truth für menschliche Nutzer. Binden Sie sie via Pinniped (Supervisor + Concierge) an jedes Kubernetes-Cluster (AKS/EKS/GKE) an, sodass alle Cluster Entra-Anmeldungen akzeptieren.
- Observability: Instrumentieren Sie Apps und Infrastruktur mit OpenTelemetry → senden Sie die Daten an Azure Monitor / Log Analytics.
- Detection: Nutzen Sie KQL Time-Series ML (ohne eigene Modelle), um Service-Anomalien zu erkennen.
- Action: Verbinden Sie Azure Monitor Alerts mit Logic Apps/Azure Functions für sichere und auditierbare Remediation.
Ergebnis: eine Auth-Plane , ein Observability-Fabric , schnellere MTTR und pragmatische Zero-Trust-Controls – ganz ohne eigene ML-Infrastruktur.
Für wen ist dieser Beitrag gedacht
Plattform-, SRE- und Security-Architekten, die Multi-Cloud-Kubernetes (AKS/EKS/GKE) betreiben und Folgendes wollen:
- Eine zentrale, auditierbare Identitätsebene für menschliche Nutzer
- Standardisierte Telemetrie über alle Clouds hinweg
- Kostenbewusste Anomalie-Erkennung und sichere Automatisierung
Welche Probleme löst das?
- Fragmentierte User-Authentifizierung über AKS/EKS/GKE → Drift und manueller Aufwand.
- Telemetrie-Silos → uneinheitliche Detection und langsame Incident Response.
- Eigene ML-Stacks aufzubauen ist teuer und für viele Signale überdimensioniert.
Ziel: Ein wiederholbares Muster, das (1) Identität zentralisiert, (2) Telemetrie standardisiert, (3) mit leichtgewichtigem KQL ML erkennt und (4) abgesicherte Remediation automatisiert.
Architektur auf einen Blick
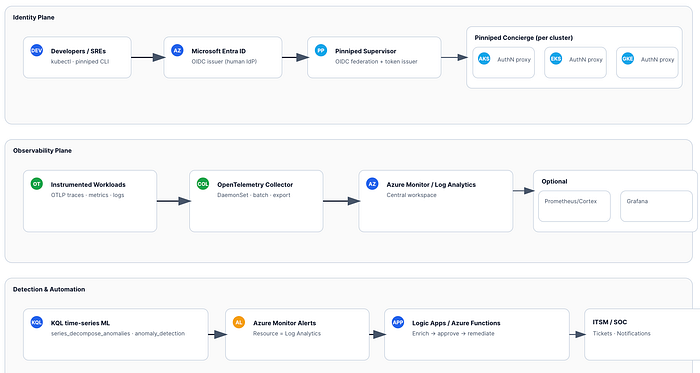
- Entra ID (IdP) → Pinniped Supervisor (OIDC-Issuer/Federation) → Pinniped Concierge (pro Cluster).
- Entwickler melden sich einmal mit Entra an und erhalten kurzlebige Kubernetes-Tokens für AKS/EKS/GKE.
- App- und Infrastruktur-Telemetrie via OpenTelemetry SDKs/Auto-Instrumentation → OpenTelemetry Collector (DaemonSet) → Azure Monitor / Log Analytics (zentraler Workspace). Optional: Metriken via remote_write an Prometheus/Cortex und Dashboards in Grafana.
- KQL
series_decompose_anomalies/anomaly_detectionfür Identitäts- und Service-Anomalien → Azure Monitor Alerts → Logic App/Azure Function für Anreicherung und Remediation.
Policy & Automatisierung (optional)
- Kyverno/OPA Gatekeeper für Admission- und Runtime-Policies; Azure Monitor Alerts → Logic App / Azure Function für orchestrierte Remediation (Ticketing, Conditional Access, Quarantäne).
Azure-first-Voraussetzungen (POC-Scope)
- Subscription & Resource Group für Monitoring und Shared Services.
- Log Analytics Workspace (zentral).
- (Optional) Application Insights – falls Sie AI-basierte App-Telemetrie-Sichten oberhalb von LA bevorzugen.
- Microsoft Entra Tenant mit Berechtigungen zum Anlegen von App Registrations.
- Azure Key Vault für Secrets (Entra-App-Client-Secret; optional Connection Strings).
- kubectl + Zugriff auf mindestens ein Cluster (AKS für den Azure-Walkthrough; EKS/GKE später).
- Helm für Pinniped und OpenTelemetry Collector.
Tipp: Halten Sie Namen und Locations konsistent (z. B.
rg-plat-shared,law-plat-central).
Schnelles Azure-Deployment – Schritt für Schritt
Dieser Abschnitt führt Sie von null bis zu Signalen und Alerts, mit Fokus auf Azure. Anschließend erweitern Sie auf EKS/GKE.
1) Kern-Monitoring-Ressourcen anlegen
Option A – Azure CLI
# Variablen
LOC=westeurope
RG=rg-plat-shared
LAW=law-plat-central
az group create -n $RG -l $LOC
az monitor log-analytics workspace create -g $RG -n $LAW -l $LOC# Workspace-Infos für später ermitteln
LAW_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query id -o tsv)
LAW_CUST_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query customerId -o tsv)
LAW_KEY=$(az monitor log-analytics workspace get-shared-keys -g $RG -n $LAW --query primarySharedKey -o tsv)
Option B – Bicep (idempotent)
param location string = 'westeurope'
param rgName string = 'rg-plat-shared'
param workspaceName string = 'law-plat-central'
resource law 'Microsoft.OperationalInsights/workspaces@2022-10-01' = {
name: workspaceName
location: location
properties: {
retentionInDays: 30
features: {
searchVersion: 1
}
}
}
Die Retention ist der Hauptkostentreiber. Starten Sie mit 30 Tagen und passen Sie das je nach Compliance-Anforderung an.
2) Entra-Sign-in- und Audit-Logs nach Log Analytics exportieren
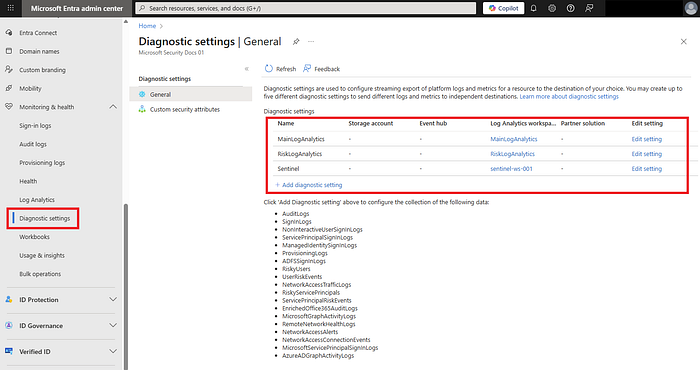
- Im Entra Admin Center → Monitoring & health → Diagnostics settings → Add → senden Sie SigninLogs und AuditLogs an den zuvor angelegten Log Analytics Workspace.
- Stellen Sie sicher, dass die Einstellung aktiviert ist und Logs eintreffen, indem Sie nach 10–15 Minuten
SigninLogs | take 5ausführen.
3) Entra-App für Pinniped Supervisor registrieren
- App Registration: erteilen Sie
openid,profile,email,offline_access. - Fügen Sie eine Redirect URI für den Supervisor-Callback hinzu (z. B.
https://pinniped.<your-domain>/callback). - Erstellen Sie ein Client Secret → speichern Sie es im Key Vault.
- Notieren Sie sich Tenant ID und Client ID.
4) Pinniped auf AKS deployen (Supervisor + Concierge)
Sie können den Supervisor in einem kleinen, gemeinsam genutzten Control-Cluster betreiben (empfohlen) und Concierge in jedem Workload-Cluster (AKS/EKS/GKE) deployen.
Supervisor installieren (Helm)
helm repo add pinniped https://pinniped.dev/helm-charts
helm repo update
kubectl create ns pinniped-supervisor
helm upgrade --install pinniped-supervisor pinniped/supervisor \
-n pinniped-supervisor \
--set service.type=LoadBalancer \
--set config.generateTLS=true
FederationDomain anlegen (Verbindung zu Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
identityProviders:
- name: azuread
type: OIDC
oidc:
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: https://pinniped.<your-domain> # öffentliche Supervisor-URL
Hinterlegen Sie das Entra Client Secret als Kubernetes-Secret namens
pinniped-azure-secretim Namespacepinniped-supervisor.
Concierge in AKS-Cluster(n) installieren
kubectl create ns pinniped-concierge
helm upgrade --install pinniped-concierge pinniped/concierge \
-n pinniped-concierge \
--set credentialIssuer.enable=true
Dev-Login validieren
- Vom Entwickler-Laptop aus:
pinniped login oidc --issuer https://pinniped.<your-domain> --ca-bundle <CA.pem> - Prüfen Sie, dass eine Kubeconfig mit kurzlebigen Tokens erzeugt wird und
kubectl get podsgegen AKS funktioniert.
Wiederholen Sie die Concierge -Installation für EKS/GKE, um Sign-in cloudübergreifend zu vereinheitlichen.
5) OpenTelemetry Collector auf AKS deployen (Export an Azure Monitor)
Helm (generischer Collector)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
kubectl create ns observability
cat <<'EOF' > values-otel.yaml
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
EOFhelm upgrade --install otel-collector open-telemetry/opentelemetry-collector -n observability -f values-otel.yaml
Woher bekomme ich den Connection String? Öffnen Sie in Azure Ihre Application Insights -Ressource → Overview → Connection string . Sie können auch direkt via Data Collection Endpoints/Rules an Log Analytics senden, aber AI ist der einfachste Einstieg für App-Traces.
Telemetrie taggen und samplen
- Ergänzen Sie Resource-Attribute:
service.name,service.namespace,deployment.environment,team,costCenter. - Starten Sie mit Tail-based Sampling (10–20 %) für Traces; behalten Sie für Metriken eine Auflösung von 1–5 Minuten bei.
A. Identitäts-Anomalie (Spikes) – Rauschen ausschließen, "Impossible Travel" ergänzen, nach User dimensionieren
Was ist neu:
- Schließt Service- und Break-Glass-Accounts aus
- Verwendet eine 7-Tage-Rolling-Baseline mit 24-Stunden-Saisonalität
- Ergänzt Geo-Anreicherung und einen optionalen Impossible-Travel-Check
- Liefert eine saubere Payload für das Alert-Routing
// ---- Parameter
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
let sensitivity = 95; // 90–99; höher = weniger Alerts
let serviceAccounts = dynamic(["svc_", "automaton@", "spn-"]); // auszuschließende Präfixe/Marker
// ---- Hauptabfrage
SigninLogs
| where TimeGenerated > ago(lookback)
| where ResultType != 0 // nur Fehler
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (serviceAccounts)) // svc/breakglass ausschließen
| summarize failed=count(),
ips = make_set(IPAddress, 4),
apps = make_set(AppDisplayName, 4)
by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed)
on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend decomp = series_decompose(failedSeries, 24) // Tagesmuster modellieren
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime),
failedSeries to typeof(double),
decomp to typeof(dynamic),
anomalies to typeof(double)
| where anomalies > 0
// ---- Optional Geo + Impossible Travel
| join kind=leftouter (
SigninLogs
| where TimeGenerated > ago(lookback)
| summarize arg_max(TimeGenerated, *) by UserId, IPAddress
| project UserPrincipalName, IPAddress, Country = LocationDetails.countryOrRegion, Latitude = todouble(LocationDetails.geoCoordinates.latitude), Longitude = todouble(LocationDetails.geoCoordinates.longitude)
) on $left.UPN == $right.UserPrincipalName
| project TimeGenerated, UPN, failed=failedSeries, IPs=ips, Apps=apps, Country, Latitude, Longitude, anomalyScore=anomalies
| order by anomalyScore desc
Optionales "Impossible Travel"-Add-on (paarweise Geo-Sprünge > 1.500 km in < 2 h):
let minKm = 1500.0;
let maxHours = 2.0;
let toRad = (d:real) { d * pi() / 180.0 };
let haversine = (lat1:real, lon1:real, lat2:real, lon2:real) {
let dlat = toRad(lat2 - lat1);
let dlon = toRad(lon2 - lon1);
let a = pow(sin(dlat/2),2) + cos(toRad(lat1)) * cos(toRad(lat2)) * pow(sin(dlon/2),2);
6371.0 * 2 * asin(sqrt(a)) // km
};
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType == 0
| project UPN = UserPrincipalName, TimeGenerated, Lat = todouble(LocationDetails.geoCoordinates.latitude), Lon = todouble(LocationDetails.geoCoordinates.longitude)
| where isnotempty(Lat) and isnotempty(Lon)
| serialize
| extend prevTime = prev(TimeGenerated), prevLat = prev(Lat), prevLon = prev(Lon), prevUPN = prev(UPN)
| where UPN == prevUPN
| extend hrs = real(datetime_diff("minute", TimeGenerated, prevTime)) / 60.0
| extend km = haversine(prevLat, prevLon, Lat, Lon)
| where hrs > 0 and km / hrs > (minKm / maxHours)
| project TimeGenerated, UPN, km, hrs, speedKmh = km/hrs
Tipp: Behandeln Sie Identitäts-Anomalie und Impossible Travel als separate Alerts ; routen Sie Letztere mit höherer Severity.
B. Service-Anomalien – an Ihre Datentabellen angepasst, plus Error Rate und SLO-Burn
Wenn Sie App-Telemetrie über Application Insights senden (üblich bei OTel→Azure Monitor), ersetzen Sie Perf durch diese reichhaltigeren Tabellen:
p95-Latenz-Spike (App Insights / OTel)
let window = 7d;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize p95 = percentile(duration, 95) by bin(timestamp, step), cloud_RoleName
| make-series p95Series = avg(p95) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 24)
| mv-expand timestamp to typeof(datetime), p95Series to typeof(real), anomalies to typeof(double)
| where anomalies > 0
| project timestamp, service=cloud_RoleName, p95_ms = toreal(p95Series), anomalyScore = anomalies
| order by anomalyScore desc
Error-Rate-Spike (handlungsrelevanter als reine Latenz)
let window = 24h;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize total=count(), errors = countif(success == false) by bin(timestamp, step), cloud_RoleName
| extend errRate = todouble(errors)/todouble(total)
| make-series errSeries = avg(errRate) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(errSeries, 95, 24)
| mv-expand timestamp to typeof(datetime), errSeries to typeof(real), anomalies to typeof(double)
| where anomalies > 0 and errSeries > 0.02 // Guardrail: >2 % Error Rate
| project timestamp, service=cloud_RoleName, errorRate = round(errSeries*100.0, 2), anomalyScore = anomalies
| order by anomalyScore desc
SLO-Burn-Rate (Fast/Slow Windows) – ideal für Paging
// Beispiel: 99,9 % Success-SLO
let slo = 0.999;
let fast = 5m;
let slow = 1h;
let targetBurn = 14.4; // pagen, wenn Sie das Error Budget mit 14,4-facher Rate verbrennen
let agg = (win:timespan) {
requests
| where timestamp > ago(win)
| summarize total=count(), errors=countif(success == false) by cloud_RoleName
| project cloud_RoleName, errRate = todouble(errors)/todouble(total)
};let fastW = agg(fast);
let slowW = agg(slow);fastW
| join kind=inner slowW on cloud_RoleName
| extend burnFast = (1.0 - slo) == 0 ? 0.0 : errRate_left / (1.0 - slo),
burnSlow = (1.0 - slo) == 0 ? 0.0 : errRate_right / (1.0 - slo)
| extend burnRate = burnFast / burnSlow
| where burnRate > targetBurn and errRate_left > (1.0 - slo)
| project service=cloud_RoleName, burnRate=round(burnRate,2), errRateFast=round(errRate_left*100,3), errRateSlow=round(errRate_right*100,3)
Wenn Sie tatsächlich auf die
Perf-Tabelle setzen (Legacy/VM/Container Insights), spiegeln Sie dieselbe Logik aufInsightsMetricsoder Ihrer eigenen Custom-Metric stattrequests.
C. Als wiederverwendbare KQL-Funktionen verpacken (sauberere Alerts)
Hinterlegen Sie diese als Funktionen in Ihrem Workspace, damit die Alert Rules schlank bleiben:
// function detect_failed_signin_anomalies(sensitivity:int, exclude:dynamic)
.create-or-alter function with (folder = "detections") detect_failed_signin_anomalies(sensitivity:int=95, exclude:dynamic=dynamic(["svc_"])) {
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType != 0
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (exclude))
| summarize failed=count() by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed) on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime), failedSeries to typeof(double), anomalies to typeof(double)
| where anomalies > 0
| project TimeGenerated, UPN, failed=failedSeries, anomalyScore=anomalies
}
Ihre Alert Query wird dann ganz schlank:
detections.detect_failed_signin_anomalies(96, dynamic(["svc_","breakglass@"]))
7) Alerting – handlungsrelevant, rauscharm und einfach zu routen
Nutzen Sie diese Azure-Monitor-Features:
- Split-by Dimensions: erstellen Sie einen Alert pro UPN oder pro Service (Dimension =
UPN/cloud_RoleName). Das verhindert Sammelalarme und ermöglicht automatisches Routing an das richtige Team bzw. den richtigen User. - Frequency und Lookback: starten Sie mit 15 Min. Frequency und 60 Min. Lookback; gehen Sie auf 5 Min., sobald es stabil läuft.
- Number of Violations: verlangen Sie ≥ 2 aufeinanderfolgende Auswertungen vor dem Auslösen, um Einzelausreißer zu vermeiden.
- Action Rules: unterdrücken Sie Alerts während Wartungsfenstern oder bekanntermaßen lauten Phasen (z. B. großen Deployments).
- Custom Properties: ergänzen Sie UPN/Service, Anomaly Score, letzte IP/Geo in der Alert-Payload (ideal für Logic Apps).
- Zwei Stufen: Severity 2 (Page) für SLO-Burn und Severity 3–4 (Notify) für einfache Anomalien.
In die Alert-Payload aufzunehmende Felder (Custom Details):
entity:UPNoderservicesignal:failed_signin_anomaly/latency_p95_anomaly/error_rate_spikescore: Anomaly Scorecontext: letzte 3 IPs/Länder oder Top-fehlerhafte Endpointsrunbook: Link zur Remediation-Doku
Action-Group-Verkabelung:
- Webhook an Logic App (primär)
- Teams-/Slack-Channel des verantwortlichen Teams (dimensionsbasiert)
- ITSM-Connector (automatische Ticket-Erstellung)
Erste Schritte in der Logic App (empfohlen):
- De-Dup/Suppress, falls bereits ein aktives Incident für dieselbe Kombination aus
entity+signalexistiert. - Anreichern (Graph für User; Azure Resource Graph / GitOps für Service).
- Routen:
- Geringe Auswirkung → nur Notify + Ticket
- Hohe Auswirkung → Approval, dann Aktion (MFA erzwingen / blockieren; Rollback/Scale-to-0; PR zurücksetzen)
Kleine, aber wirkungsvolle Quality-of-Life-Tweaks
- Charts für Reviewer: ergänzen Sie ein gepinntes Workbook oder die Zeile
render timechartin Queries, die Sie manuell triagieren.
| project timestamp=TimeGenerated, failed=failedSeries
| render timechart
- Noise-Guardrails: ergänzen Sie in Anomaly-Queries minimale absolute Schwellenwerte (z. B.
failedSeries >= 5), damit kleine Ausreißer keine Alerts auslösen. - Feiertags- und Wochenend-Sensitivität: bei saisonalen False Positives senken Sie
sensitivityam Wochenende oder schließen Sie Feiertage über eine kleine Lookup-Tabelle aus. - Service-Account-Registry: pflegen Sie eine zentrale Liste und laden Sie sie via
externaldata()aus einer Blob-/GH-Raw-URL, sodass Analysten sie ohne Query-Änderung aktualisieren können.
- Öffnen Sie Azure Monitor → Logs → führen Sie eine Query aus.
- Klicken Sie auf New alert rule → setzen Sie Resource = Log Analytics Workspace.
- Condition = Ihre Query mit Threshold auf Results > 0.
- Action Group = E-Mail/SMS/ITSM + Logic App Webhook.
- Severity/Evaluation Frequency = konservativ starten (z. B. alle 15 Min.).
8) Sichere Automatisierung mit Logic Apps / Functions
- Die Logic App empfängt den Alert → reichert den Kontext an (User Risk, Geo, letzte erfolgreiche Logins, Service Health) → entscheidet den Pfad:
- Nur Notify (in den ersten Wochen) mit Ticket im ITSM.
- Abgesicherte Aktion (mit Approval) via Microsoft Graph (z. B. MFA erzwingen, temporärer Sign-in-Block) oder Kubernetes-RBAC-Änderungen.
- Alle Änderungen müssen auditierbar sein und nach dem Prinzip der geringsten Privilegien erfolgen (siehe unten).
Erweiterung auf EKS/GKE
- Verwenden Sie den Supervisor wieder; installieren Sie Concierge in jedem Cluster.
- Behalten Sie pro Cluster einen OpenTelemetry Collector; exportieren Sie an denselben Azure Workspace (mit Tag
cloud.provider). - Verwenden Sie dieselben KQL-Queries cloudübergreifend; pivotieren Sie nach
cloud_RoleName/k8s.cluster.name.
Risiken und Gegenmaßnahmen
- False Positives: Starten Sie im Notify Mode; iterieren Sie Sensitivity und Windows.
- Automation Blast Radius: Verlangen Sie manuelle Approvals für Schritte mit hoher Auswirkung; setzen Sie auf einen progressiven Rollout.
- Supervisor-Exposure: Platzieren Sie ihn hinter einer WAF, schränken Sie IP-Ranges ein und erzwingen Sie TLS und HSTS.
- Least Privilege: Graph-Scopes sind auf die automatisierten Aktionen beschränkt; Azure RBAC für Function/Logic App folgt dem Prinzip der geringsten Privilegien.
Kosten und Lizenzierung
- Hauptkosten: Log-Ingestion und Retention. Steuern Sie diese via Sampling und 30–90 Tage Retention.
- KQL ML: Keine separaten Kosten für ML-Infrastruktur.
- Entra P2 (optional): Liefert native Risk-Signale; Ihre KQL-Detections sind eine kompensierende Kontrolle, falls Sie kein P2 haben.
- Pinniped: Leichtgewichtig; die Infrastrukturkosten sind im Vergleich zu Logs vernachlässigbar.
Copy-ready Snippets (Anhang)
FederationDomain (Supervisor ↔ Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
issuer: https://pinniped.<your-domain>
identityProviders:
- name: azuread
type: OIDC
oidc:
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
Minimaler OTel Collector (an Azure Monitor)
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
KQL – Identitäts-Anomalie
SigninLogs
| where TimeGenerated > ago(14d)
| where ResultType != 0
| summarize failed=count() by bin(TimeGenerated, 1h), UserPrincipalName
| make-series failedSeries=avg(failed) on TimeGenerated from ago(7d) to now() step 1h by UserPrincipalName
| extend anomalies = series_decompose_anomalies(failedSeries, 95, 7)
| where array_length(anomalies) > 0
KQL – Service-Latenz-Anomalie
Perf
| where TimeGenerated > ago(7d) and CounterName == "request_duration_ms"
| summarize p95 = percentile(CounterValue, 95) by bin(TimeGenerated, 5m), ServiceName
| make-series p95Series=avg(p95) on TimeGenerated from ago(7d) to now() step 5m by ServiceName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 7)
| where array_length(anomalies) > 0
Was Sie out of the box bekommen
- Copy-paste-fertige Helm- und YAML-Snippets, um Supervisor/Concierge + OTel Collector aufzusetzen
- Zwei produktionsreife KQL-Anomaly-Queries
- Klare Schritte zur Verkabelung von Azure Monitor Alerts und Logic Apps
Optional: Policy & Automatisierung (warum, wann, wie)
Warum sich das lohnt
- Guardrails statt Gates: Verhindern Sie riskante Konfigurationen, bevor sie laufen (Admission), und erkennen Sie Runtime-Drift (Policy-Events ins Logging).
- Eng mit dem Engineering verzahnt: Alerts, die nur Menschen pagen, verlängern die MTTR. Eine schlanke Automatisierungsschicht ermöglicht Ihnen Anreichern → Entscheiden → (optional) Handeln – sicher und kontrolliert.
- Auditierbare Kontrolle: Jede automatisierte Aktion läuft über Azure Monitor + Logic Apps mit Approvals und Logs.
Praxisbeispiele
Verdächtiger Sign-in-Spike (Identität)
- Signal: KQL auf
SigninLogsmarkiert einen Ausreißer für einen User oder eine App. - Automatisierung: Alert → Logic App reichert mit User Risk und Geo an → öffnet ein Ticket und ruft (mit Approval) Microsoft Graph auf, um Step-up-MFA oder einen temporären Sign-in-Block zu erzwingen.
Privileged Pod Drift (Runtime)
- Signal: Kyverno/Gatekeeper meldet einen Pod mit
privileged: trueoderCAP_SYS_ADMIN. - Automatisierung: Alert → Logic App postet in Slack/Teams, legt ein JIRA-Incident an und skaliert (mit Approval) das Deployment im betroffenen Namespace auf 0.
Unsigniertes Image / falsche Registry (Supply Chain)
- Signal: Admission-Policy lehnt Images ab, die nicht aus
my-acr.azurecr.iostammen oder keine Cosignature haben. - Automatisierung: Erstellen Sie eine kurzlebige Ausnahme (24 h) nur, wenn ein Approver zustimmt; loggen Sie die Ausnahme in LA.
Namespace ohne Owner/Labels (Ops Hygiene)
- Signal: Admission lehnt die Namespace-Erstellung ab, weil
owner/costCenterfehlen. - Automatisierung: Logic App pingt den Requester mit einem vorausgefüllten
kubectl label-Befehl an.
Secrets in Env-Variablen (Misconfig)
- Signal: Policy auditiert ein Manifest, das Secrets im Klartext referenziert.
- Automatisierung: Per PR-Bot (GitOps-Flow) auf
Secret+ Volume Mount umstellen und ein Security-Ticket öffnen.
Was zu deployen ist (minimal)
- Admission (Prevent/Mutate): Kyverno oder OPA Gatekeeper.
- Runtime-Audit → Logs: Policy-Ergebnisse an Log Analytics senden.
- Decisioning: Azure Monitor Alert Rules (aus KQL- oder Policy-Events).
- Orchestrierung: Logic Apps (oder Azure Functions) mit Human Approval, wo die Auswirkung hoch ist.
Starter-Policies (Kyverno)
Privilegierte Container verbieten:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged
spec:
validationFailureAction: enforce
rules:
- name: no-priv
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: "false"
Owner- und Cost-Center-Labels verlangen:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-owner-labels
spec:
validationFailureAction: enforce
rules:
- name: require-labels
match: { resources: { kinds: ["Namespace","Deployment","StatefulSet"] } }
validate:
message: "owner and costCenter labels are required."
pattern:
metadata:
labels:
owner: "?*"
costCenter: "?*"
Images auf Ihre ACR beschränken:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-registries
spec:
validationFailureAction: enforce
rules:
- name: only-acr
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Images must come from my-acr.azurecr.io"
pattern:
spec:
containers:
- image: "my-acr.azurecr.io/*"
Bevorzugen Sie zunächst den Audit Mode : setzen Sie
validationFailureAction: auditfür eine Woche, justieren Sie nach und schalten Sie dann aufenforceum.
Identitäts-Anomalie-Flow
- KQL-Query auf
SigninLogs(aus dem Beitrag) → Alert Rule (alle 15 Min.). - Action Group: Logic App Webhook + Teams/JIRA.
- Logic-App-Schritte:
- User-Details und Sign-in-History abrufen (Graph).
- Letzte erfolgreiche MFA prüfen.
- Branch:
- Geringe Auswirkung: Notify + Ticket.
- Hohe Auswirkung: Approval (Service Owner) → Graph-
conditionalAccess-Update oder temporärer Block. - Ergebnis zurück nach Log Analytics schreiben.
Runtime-/Policy-Flow
- Kyverno → Policy-Events an Log-Analytics-Tabelle senden (via OTel oder AKS-Diagnostics).
- KQL-Alert auf neue Enforcement-Verstöße bei
disallow-privileged. - Logic App:
- Deployment- und Pod-Metadaten ziehen.
- Service Owner über das Remediation-Snippet informieren.
- Optionale Approval →
az aks command invokeoder GitOps-PR zum Zurücksetzen/Patchen.
Wann Sie das (vorerst) überspringen sollten
- Einzelnes Cluster, kleines Team oder noch keine On-Call-Automatisierungskultur.
- Falls Ihnen Entra-/Graph-Privilegien fehlen, um Conditional Access durchzusetzen – starten Sie mit Observability + Tickets und ergänzen Sie Enforcement später.
Sie brauchen Unterstützung? Wir helfen Ihnen gerne weiter.
Wenn Sie das für einen Proof of Concept evaluieren oder Deployments planen, unterstützt Sie DoiT. Unser Team aus über 100 Experten ist auf maßgeschneiderte Cloud-Lösungen spezialisiert und begleitet Sie durch den gesamten Prozess – damit Ihre Infrastruktur compliant ist und für künftige Anforderungen gerüstet bleibt.
Lassen Sie uns gemeinsam besprechen, was in dieser Phase der Policy Enforcement für Ihr Unternehmen am sinnvollsten ist – damit Ihre Cloud-Infrastruktur robust, compliant und auf Erfolg ausgerichtet bleibt. Sprechen Sie uns an.