Un POC concret et économique à monter en un week-end — avec un déploiement Azure pas à pas

image générée par IA (chatgpt5.0)
En bref
- Identité : faites de Microsoft Entra ID votre source unique de vérité pour les utilisateurs humains. Reliez-le à n'importe quel Kubernetes (AKS/EKS/GKE) via Pinniped (Supervisor + Concierge) pour que tous les clusters acceptent l'authentification Entra.
- Observabilité : instrumentez applications et infrastructure avec OpenTelemetry → expédiez vers Azure Monitor / Log Analytics.
- Détection : exploitez le ML de séries temporelles KQL (sans modèles sur mesure) pour repérer les anomalies de service.
- Action : reliez les alertes Azure Monitor à Logic Apps/Azure Functions pour une remédiation sûre et auditable.
Résultat : un plan d'authentification unique, une fabrique d'observabilité unifiée, un MTTR raccourci et des contrôles zero-trust pragmatiques — sans déployer la moindre infrastructure ML.
À qui s'adresse cet article
Aux architectes plateforme, SRE et sécurité qui gèrent du Kubernetes multi-cloud (AKS/EKS/GKE) et recherchent :
- Un plan d'identité humaine centralisé et auditable
- Une télémétrie standardisée entre les clouds
- Une détection d'anomalies maîtrisée côté coûts et une automatisation sûre
Quels problèmes cela résout-il ?
- Authentification utilisateur fragmentée entre AKS/EKS/GKE → dérive et tâches répétitives.
- Télémétrie cloisonnée → détection incohérente et réponse aux incidents trop lente.
- Monter une stack ML coûte cher et reste disproportionné pour bon nombre de signaux.
Objectif : un schéma reproductible qui (1) centralise l'identité, (2) standardise la télémétrie, (3) détecte avec un ML KQL léger, et (4) automatise une remédiation encadrée.
L'architecture en un coup d'œil
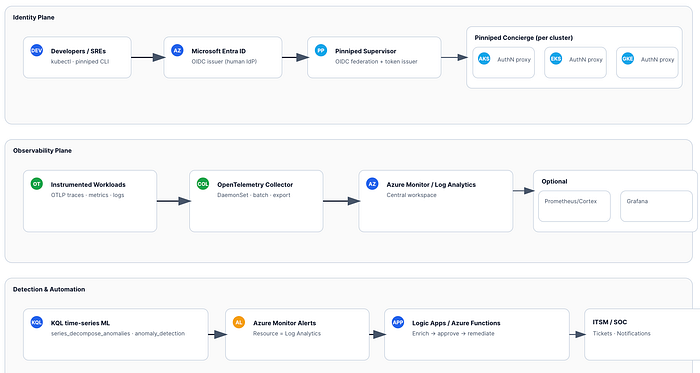
- Entra ID (IdP) → Pinniped Supervisor (émetteur OIDC/fédération) → Pinniped Concierge (par cluster).
- Les développeurs s'authentifient une seule fois avec Entra et obtiennent des tokens Kubernetes éphémères pour AKS/EKS/GKE.
- Télémétrie applicative et d'infrastructure via les SDK/auto-instrumentation OpenTelemetry → OpenTelemetry Collector (DaemonSet) → Azure Monitor / Log Analytics (workspace central). En option : remote_write des métriques vers Prometheus/Cortex et dashboards Grafana.
- KQL
series_decompose_anomalies/anomaly_detectionpour les anomalies d'identité et de service → alertes Azure Monitor → Logic App/Azure Function pour l'enrichissement et la remédiation.
Politique et automatisation (en option)
- Kyverno/OPA Gatekeeper pour les politiques d'admission et de runtime ; alertes Azure Monitor → Logic App / Azure Function pour une remédiation orchestrée (ticketing, accès conditionnel, mise en quarantaine).
Prérequis Azure (périmètre POC)
- Souscription et groupe de ressources pour la supervision et les services partagés.
- Workspace Log Analytics (central).
- (En option) Application Insights (si vous préférez des vues de télémétrie applicative basées sur AI au-dessus de LA).
- Tenant Microsoft Entra avec les droits nécessaires pour créer des App Registrations.
- Azure Key Vault pour les secrets (client secret de l'app Entra ; chaînes de connexion en option).
- kubectl + accès à au moins un cluster (AKS pour le tutoriel Azure ; EKS/GKE traités plus loin).
- Helm pour Pinniped et OpenTelemetry Collector.
Astuce : gardez des noms et emplacements cohérents (ex. :
rg-plat-shared,law-plat-central).
Déploiement Azure express — pas à pas
Cette section vous emmène de zéro jusqu'aux signaux et alertes, avec une approche centrée sur Azure. Vous pourrez ensuite étendre le dispositif à EKS/GKE.
1) Créer les ressources de supervision principales
Option A — Azure CLI
# Variables
LOC=westeurope
RG=rg-plat-shared
LAW=law-plat-central
az group create -n $RG -l $LOC
az monitor log-analytics workspace create -g $RG -n $LAW -l $LOC# Récupérer les infos du workspace pour la suite
LAW_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query id -o tsv)
LAW_CUST_ID=$(az monitor log-analytics workspace show -g $RG -n $LAW --query customerId -o tsv)
LAW_KEY=$(az monitor log-analytics workspace get-shared-keys -g $RG -n $LAW --query primarySharedKey -o tsv)
Option B — Bicep (idempotent)
param location string = 'westeurope'
param rgName string = 'rg-plat-shared'
param workspaceName string = 'law-plat-central'
resource law 'Microsoft.OperationalInsights/workspaces@2022-10-01' = {
name: workspaceName
location: location
properties: {
retentionInDays: 30
features: {
searchVersion: 1
}
}
}
La rétention pilote le coût. Démarrez à 30 jours et ajustez selon vos exigences de conformité.
2) Exporter les logs de connexion et d'audit Entra vers Log Analytics
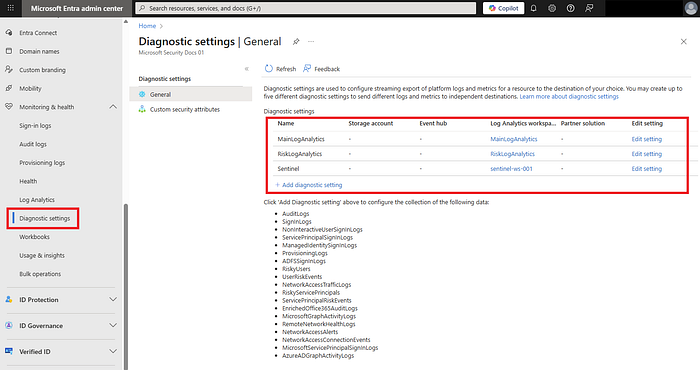
- Dans le centre d'administration Entra → Monitoring & health → Diagnostics settings → Add → envoyez SigninLogs et AuditLogs vers le workspace Log Analytics que vous venez de créer.
- Vérifiez que le paramètre est bien activé et que les logs remontent en exécutant
SigninLogs | take 5au bout de 10 à 15 minutes.
3) Enregistrer l'application Entra pour Pinniped Supervisor
- App Registration : accordez
openid,profile,email,offline_access. - Ajoutez une Redirect URI pour le callback du Supervisor (ex. :
https://pinniped.<votre-domaine>/callback). - Créez un client secret → stockez-le dans Key Vault.
- Notez le Tenant ID et le Client ID.
4) Déployer Pinniped sur AKS (Supervisor + Concierge)
Vous pouvez exécuter le Supervisor dans un petit cluster de contrôle partagé (recommandé) et déployer le Concierge sur chaque cluster de workloads (AKS/EKS/GKE).
Installer Supervisor (Helm)
helm repo add pinniped https://pinniped.dev/helm-charts
helm repo update
kubectl create ns pinniped-supervisor
helm upgrade --install pinniped-supervisor pinniped/supervisor \
-n pinniped-supervisor \
--set service.type=LoadBalancer \
--set config.generateTLS=true
Créer la FederationDomain (lien vers Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
identityProviders:
- name: azuread
type: OIDC
oidc:
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: https://pinniped.<votre-domaine> # URL publique du Supervisor
Stockez le client secret Entra dans un secret Kubernetes nommé
pinniped-azure-secretau sein du namespacepinniped-supervisor.
Installer Concierge sur le ou les clusters AKS
kubectl create ns pinniped-concierge
helm upgrade --install pinniped-concierge pinniped/concierge \
-n pinniped-concierge \
--set credentialIssuer.enable=true
Valider la connexion développeur
- Depuis un poste développeur :
pinniped login oidc --issuer https://pinniped.<votre-domaine> --ca-bundle <CA.pem> - Vérifiez qu'un kubeconfig avec des tokens éphémères est bien généré et que
kubectl get podsfonctionne sur AKS.
Renouvelez l'installation du Concierge sur EKS/GKE pour unifier l'authentification entre tous les clouds.
5) Déployer OpenTelemetry Collector sur AKS (export vers Azure Monitor)
Helm (collector générique)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm repo update
kubectl create ns observability
cat <<'EOF' > values-otel.yaml
config:
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
EOFhelm upgrade --install otel-collector open-telemetry/opentelemetry-collector -n observability -f values-otel.yaml
Où trouver la connection string ? Dans Azure, ouvrez votre ressource Application Insights → Overview → Connection string . Vous pouvez aussi envoyer directement vers Log Analytics via les Data Collection Endpoints/Rules, mais AI reste la voie la plus simple pour les traces applicatives.
Étiqueter et échantillonner la télémétrie
- Ajoutez les attributs de ressource :
service.name,service.namespace,deployment.environment,team,costCenter. - Démarrez avec un échantillonnage tail-based (10 à 20 %) pour les traces ; conservez une résolution de 1 à 5 minutes pour les métriques.
A. Anomalie d'identité (pics) — exclure le bruit, ajouter le voyage impossible et dimensionner par utilisateur
Nouveautés :
- Exclut les comptes de service et break-glass
- S'appuie sur une baseline glissante de 7 jours avec une saisonnalité de 24 h
- Ajoute un enrichissement géographique et un contrôle optionnel de voyage impossible
- Émet un payload propre, prêt pour le routage d'alerte
// ---- Paramètres
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
let sensitivity = 95; // 90–99 ; plus élevé = moins d'alertes
let serviceAccounts = dynamic(["svc_", "automaton@", "spn-"]); // préfixes/marqueurs à exclure
// ---- Principal
SigninLogs
| where TimeGenerated > ago(lookback)
| where ResultType != 0 // échecs uniquement
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (serviceAccounts)) // exclut svc/breakglass
| summarize failed=count(),
ips = make_set(IPAddress, 4),
apps = make_set(AppDisplayName, 4)
by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed)
on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend decomp = series_decompose(failedSeries, 24) // modélise le motif journalier
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime),
failedSeries to typeof(double),
decomp to typeof(dynamic),
anomalies to typeof(double)
| where anomalies > 0
// ---- Géo + voyage impossible (en option)
| join kind=leftouter (
SigninLogs
| where TimeGenerated > ago(lookback)
| summarize arg_max(TimeGenerated, *) by UserId, IPAddress
| project UserPrincipalName, IPAddress, Country = LocationDetails.countryOrRegion, Latitude = todouble(LocationDetails.geoCoordinates.latitude), Longitude = todouble(LocationDetails.geoCoordinates.longitude)
) on $left.UPN == $right.UserPrincipalName
| project TimeGenerated, UPN, failed=failedSeries, IPs=ips, Apps=apps, Country, Latitude, Longitude, anomalyScore=anomalies
| order by anomalyScore desc
Module complémentaire voyage impossible (sauts géographiques par paire > 1 500 km en < 2 h) :
let minKm = 1500.0;
let maxHours = 2.0;
let toRad = (d:real) { d * pi() / 180.0 };
let haversine = (lat1:real, lon1:real, lat2:real, lon2:real) {
let dlat = toRad(lat2 - lat1);
let dlon = toRad(lon2 - lon1);
let a = pow(sin(dlat/2),2) + cos(toRad(lat1)) * cos(toRad(lat2)) * pow(sin(dlon/2),2);
6371.0 * 2 * asin(sqrt(a)) // km
};
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType == 0
| project UPN = UserPrincipalName, TimeGenerated, Lat = todouble(LocationDetails.geoCoordinates.latitude), Lon = todouble(LocationDetails.geoCoordinates.longitude)
| where isnotempty(Lat) and isnotempty(Lon)
| serialize
| extend prevTime = prev(TimeGenerated), prevLat = prev(Lat), prevLon = prev(Lon), prevUPN = prev(UPN)
| where UPN == prevUPN
| extend hrs = real(datetime_diff("minute", TimeGenerated, prevTime)) / 60.0
| extend km = haversine(prevLat, prevLon, Lat, Lon)
| where hrs > 0 and km / hrs > (minKm / maxHours)
| project TimeGenerated, UPN, km, hrs, speedKmh = km/hrs
Astuce : conservez l' anomalie d'identité et le voyage impossible en tant qu' alertes distinctes ; routez ce dernier vers une sévérité plus élevée.
B. Anomalies de service — alignez-vous sur vos tables et ajoutez taux d'erreur + burn de SLO
Si vous envoyez la télémétrie applicative via Application Insights (cas fréquent avec OTel→Azure Monitor), remplacez Perf par ces tables plus riches :
Pic de latence p95 (App Insights / OTel)
let window = 7d;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize p95 = percentile(duration, 95) by bin(timestamp, step), cloud_RoleName
| make-series p95Series = avg(p95) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 24)
| mv-expand timestamp to typeof(datetime), p95Series to typeof(real), anomalies to typeof(double)
| where anomalies > 0
| project timestamp, service=cloud_RoleName, p95_ms = toreal(p95Series), anomalyScore = anomalies
| order by anomalyScore desc
Pic du taux d'erreur (plus actionnable que la latence seule)
let window = 24h;
let step = 5m;
requests
| where timestamp > ago(window)
| summarize total=count(), errors = countif(success == false) by bin(timestamp, step), cloud_RoleName
| extend errRate = todouble(errors)/todouble(total)
| make-series errSeries = avg(errRate) on timestamp from ago(window) to now() step step by cloud_RoleName
| extend anomalies = series_decompose_anomalies(errSeries, 95, 24)
| mv-expand timestamp to typeof(datetime), errSeries to typeof(real), anomalies to typeof(double)
| where anomalies > 0 and errSeries > 0.02 // garde-fou : taux d'erreur > 2 %
| project timestamp, service=cloud_RoleName, errorRate = round(errSeries*100.0, 2), anomalyScore = anomalies
| order by anomalyScore desc
Burn-rate de SLO (fenêtres rapide/lente) — idéal pour l'astreinte
// Exemple : SLO de succès 99,9 %
let slo = 0.999;
let fast = 5m;
let slow = 1h;
let targetBurn = 14.4; // page lorsque vous brûlez 14,4x votre budget d'erreur
let agg = (win:timespan) {
requests
| where timestamp > ago(win)
| summarize total=count(), errors=countif(success == false) by cloud_RoleName
| project cloud_RoleName, errRate = todouble(errors)/todouble(total)
};let fastW = agg(fast);
let slowW = agg(slow);fastW
| join kind=inner slowW on cloud_RoleName
| extend burnFast = (1.0 - slo) == 0 ? 0.0 : errRate_left / (1.0 - slo),
burnSlow = (1.0 - slo) == 0 ? 0.0 : errRate_right / (1.0 - slo)
| extend burnRate = burnFast / burnSlow
| where burnRate > targetBurn and errRate_left > (1.0 - slo)
| project service=cloud_RoleName, burnRate=round(burnRate,2), errRateFast=round(errRate_left*100,3), errRateSlow=round(errRate_right*100,3)
Si vous dépendez réellement de la table
Perf(Legacy/VM/Container Insights), reproduisez la même logique surInsightsMetricsou sur le nom de votre métrique personnalisée plutôt que surrequests.
C. Encapsuler en fonctions KQL réutilisables (pour des alertes plus propres)
Stockez-les dans votre workspace en tant que fonctions afin de garder vos règles d'alerte épurées :
// fonction detect_failed_signin_anomalies(sensitivity:int, exclude:dynamic)
.create-or-alter function with (folder = "detections") detect_failed_signin_anomalies(sensitivity:int=95, exclude:dynamic=dynamic(["svc_"])) {
let lookback = 14d;
let baseline = 7d;
let binSize = 1h;
SigninLogs
| where TimeGenerated > ago(lookback) and ResultType != 0
| extend UPN = tostring(UserPrincipalName)
| where not(UPN has_any (exclude))
| summarize failed=count() by UPN, bin(TimeGenerated, binSize)
| make-series failedSeries = avg(failed) on TimeGenerated from ago(baseline) to now() step binSize by UPN
| extend anomalies = series_decompose_anomalies(failedSeries, sensitivity, 24)
| mv-expand TimeGenerated to typeof(datetime), failedSeries to typeof(double), anomalies to typeof(double)
| where anomalies > 0
| project TimeGenerated, UPN, failed=failedSeries, anomalyScore=anomalies
}
Votre requête d'alerte se résume alors à :
detections.detect_failed_signin_anomalies(96, dynamic(["svc_","breakglass@"]))
7) Alerting — actionnable, peu bruyant et facile à router
Tirez parti de ces fonctionnalités d'Azure Monitor :
- Split-by dimensions : créez une alerte par UPN ou par service (dimension =
UPN/cloud_RoleName). Vous évitez ainsi le spam multi-sujets et automatisez le routage vers la bonne équipe ou le bon utilisateur. - Fréquence et lookback : démarrez à 15 min de fréquence et 60 min de lookback ; passez à 5 min une fois la situation stabilisée.
- Nombre de violations : exigez ≥ 2 évaluations consécutives avant déclenchement, pour éviter les pics ponctuels.
- Action Rules : suppression pendant les fenêtres de maintenance ou les périodes connues comme bruyantes (gros déploiements, par exemple).
- Custom properties : ajoutez UPN/service, score d'anomalie, dernière IP/géo au payload de l'alerte (idéal pour Logic Apps).
- Deux niveaux : Sévérité 2 (page) pour le burn de SLO et Sévérité 3-4 (notify) pour les anomalies simples.
Champs à inclure dans le payload de l'alerte (custom details) :
entity:UPNouservicesignal:failed_signin_anomaly/latency_p95_anomaly/error_rate_spikescore: score d'anomaliecontext: 3 dernières IPs/pays ou top des endpoints en échecrunbook: lien vers le document de remédiation
Câblage de l'Action Group :
- Webhook vers Logic App (principal)
- Canal Teams/Slack pour l'équipe propriétaire (basé sur la dimension)
- Connecteur ITSM (création automatique de tickets)
Premières étapes Logic App (recommandées) :
- Dédupliquer/supprimer si un incident actif existe déjà pour le même
entity+signal. - Enrichir (Graph pour l'utilisateur ; Azure Resource Graph / GitOps pour le service).
- Router :
- Faible impact → notification + ticket uniquement
- Fort impact → Approbation puis action (exiger MFA / bloquer ; rollback/scale-to-0 ; revert PR)
Petits ajustements de confort à fort impact
- Graphiques pour les relecteurs : ajoutez un workbook épinglé ou la ligne
render timechartaux requêtes que vous triez à la main.
| project timestamp=TimeGenerated, failed=failedSeries
| render timechart
- Garde-fous anti-bruit : dans les requêtes d'anomalie, ajoutez des seuils absolus minimaux (ex. :
failedSeries >= 5) pour que les pics infimes ne déclenchent rien. - Sensibilité jours fériés/week-ends : si vous observez des faux positifs saisonniers, abaissez la
sensitivityle week-end ou excluez les jours fériés via une petite table de lookup. - Registre de comptes de service : tenez à jour une liste centralisée et chargez-la via
externaldata()depuis un blob ou une URL gh raw, pour que les analystes puissent l'éditer sans toucher aux requêtes.
- Ouvrez Azure Monitor → Logs → exécutez une requête.
- Cliquez sur New alert rule → définissez Resource = workspace Log Analytics.
- Condition = votre requête avec un seuil sur résultats > 0.
- Action group = email/SMS/ITSM + webhook Logic App.
- Sévérité / fréquence d'évaluation = démarrez prudemment (toutes les 15 min, par exemple).
8) Automatisation sûre avec Logic Apps / Functions
- La Logic App reçoit l'alerte → enrichit le contexte (risque utilisateur, géo, derniers succès, santé du service) → choisit la suite à donner :
- Notification seule (premières semaines) avec ticket dans l'ITSM.
- Action encadrée (avec approbation) via Microsoft Graph (exiger MFA, blocage de connexion temporaire, par exemple) ou modifications RBAC Kubernetes.
- Tous les changements doivent être auditables et limités au moindre privilège (voir ci-dessous).
Extension à EKS/GKE
- Réutilisez le Supervisor ; installez Concierge dans chaque cluster.
- Conservez un OpenTelemetry Collector par cluster ; exportez vers le même workspace Azure (avec un tag
cloud.provider). - Réutilisez les mêmes requêtes KQL d'un cloud à l'autre ; pivotez sur
cloud_RoleName/k8s.cluster.name.
Risques et mesures d'atténuation
- Faux positifs : démarrez en mode notification ; ajustez la sensibilité et les fenêtres au fil de l'eau.
- Rayon d'action de l'automatisation : exigez une approbation manuelle pour les étapes à fort impact ; déploiement progressif.
- Exposition du Supervisor : placez-le derrière un WAF, restreignez les plages d'IP et imposez TLS et HSTS.
- Moindre privilège : les scopes Graph se limitent aux actions automatisées ; le RBAC Azure pour Function/Logic App suit le principe du moindre privilège.
Coût et licences
- Coût principal : ingestion et rétention des logs. Maîtrisez via l'échantillonnage et une rétention de 30 à 90 jours.
- ML KQL : aucun coût d'infrastructure ML supplémentaire.
- Entra P2 (en option) : apporte des signaux de risque natifs ; vos détections KQL servent de contrôle compensatoire si vous n'avez pas P2.
- Pinniped : léger ; son coût d'infrastructure reste négligeable face à celui des logs.
Snippets prêts à copier (annexe)
FederationDomain (Supervisor ↔ Entra)
apiVersion: authentication.supervisor.pinniped.dev/v1alpha1
kind: FederationDomain
metadata:
name: entra-domain
namespace: pinniped-supervisor
spec:
issuer: https://pinniped.<votre-domaine>
identityProviders:
- name: azuread
type: OIDC
oidc:
clientID: "<CLIENT_ID>"
clientSecret: { name: "pinniped-azure-secret" }
issuer: "https://login.microsoftonline.com/<TENANT_ID>/v2.0"
OTel Collector minimal (vers Azure Monitor)
receivers:
otlp:
protocols:
grpc: {}
http: {}
processors:
batch: {}
resourcedetection:
detectors: [env, k8snode, k8scluster, k8s]
exporters:
azuremonitor:
connection_string: "InstrumentationKey=<APP_INSIGHTS_KEY>;IngestionEndpoint=https://<region>.in.applicationinsights.azure.com/"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
metrics:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
logs:
receivers: [otlp]
processors: [batch, resourcedetection]
exporters: [azuremonitor]
KQL — anomalie d'identité
SigninLogs
| where TimeGenerated > ago(14d)
| where ResultType != 0
| summarize failed=count() by bin(TimeGenerated, 1h), UserPrincipalName
| make-series failedSeries=avg(failed) on TimeGenerated from ago(7d) to now() step 1h by UserPrincipalName
| extend anomalies = series_decompose_anomalies(failedSeries, 95, 7)
| where array_length(anomalies) > 0
KQL — anomalie de latence de service
Perf
| where TimeGenerated > ago(7d) and CounterName == "request_duration_ms"
| summarize p95 = percentile(CounterValue, 95) by bin(TimeGenerated, 5m), ServiceName
| make-series p95Series=avg(p95) on TimeGenerated from ago(7d) to now() step 5m by ServiceName
| extend anomalies = series_decompose_anomalies(p95Series, 95, 7)
| where array_length(anomalies) > 0
Ce que vous obtenez clé en main
- Du Helm et du YAML prêts à coller pour déployer Supervisor/Concierge + OTel Collector
- Deux requêtes d'anomalie KQL prêtes pour la production
- Des étapes claires de câblage des alertes Azure Monitor et de la Logic App
En option : politique et automatisation (pourquoi, quand, comment)
Pourquoi l'ajouter
- Garde-fous, pas barrières : empêcher les configurations risquées avant exécution (admission) et détecter la dérive runtime (événements de politique vers les logs).
- Boucler la boucle avec l'engineering : des alertes qui se contentent de réveiller des humains allongent le MTTR. Une fine couche d'automatisation permet d'enrichir → décider → (éventuellement) agir en toute sécurité.
- Contrôle auditable : chaque action automatisée passe par Azure Monitor + Logic Apps avec approbations et logs.
Cas d'usage concrets
Pic de connexions suspectes (identité)
- Signal : une requête KQL sur
SigninLogsdétecte un outlier pour un utilisateur ou une app. - Automatisation : alerte → la Logic App enrichit avec le risque utilisateur/géo → ouvre un ticket et (avec approbation) appelle Microsoft Graph pour exiger une MFA renforcée ou un blocage de connexion temporaire.
Dérive de pod privilégié (runtime)
- Signal : Kyverno/Gatekeeper signale un pod avec
privileged: trueouCAP_SYS_ADMIN. - Automatisation : alerte → la Logic App publie sur Slack/Teams, ajoute un incident JIRA et (avec approbation) scale le déploiement à 0 dans le namespace concerné.
Image non signée / mauvais registry (chaîne d'approvisionnement)
- Signal : la politique d'admission refuse les images ne provenant pas de
my-acr.azurecr.ioou dépourvues de cosignature. - Automatisation : créer une exemption éphémère (24 h) uniquement si un approbateur valide ; consigner l'exemption dans LA.
Namespace sans propriétaire ni labels (hygiène ops)
- Signal : l'admission refuse la création du namespace, faute de
owner/costCenter. - Automatisation : la Logic App contacte le demandeur avec une commande
kubectl labelpréremplie.
Secrets dans les variables d'environnement (mauvaise configuration)
- Signal : la politique audite un manifeste référençant des secrets en clair.
- Automatisation : conversion en
Secret+ montage en volume via un bot PR (flux GitOps) et ouverture d'un ticket sécurité.
Que déployer (au minimum)
- Admission (prévenir/muter) : Kyverno ou OPA Gatekeeper.
- Audit runtime → logs : envoyez les résultats de politique vers Log Analytics.
- Décision : règles d'alerte Azure Monitor (à partir de KQL ou d'événements de politique).
- Orchestration : Logic Apps (ou Azure Functions) avec approbation humaine dès que l'impact est élevé.
Politiques de démarrage (Kyverno)
Refuser les conteneurs privilégiés :
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged
spec:
validationFailureAction: enforce
rules:
- name: no-priv
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: "false"
Exiger les labels owner/cost center :
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-owner-labels
spec:
validationFailureAction: enforce
rules:
- name: require-labels
match: { resources: { kinds: ["Namespace","Deployment","StatefulSet"] } }
validate:
message: "owner and costCenter labels are required."
pattern:
metadata:
labels:
owner: "?*"
costCenter: "?*"
Restreindre les images à votre ACR :
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-registries
spec:
validationFailureAction: enforce
rules:
- name: only-acr
match: { resources: { kinds: ["Pod"] } }
validate:
message: "Images must come from my-acr.azurecr.io"
pattern:
spec:
containers:
- image: "my-acr.azurecr.io/*"
Privilégiez d'abord le mode audit : positionnez
validationFailureAction: auditpendant une semaine, ajustez, puis basculez enenforce
Flux d'anomalie d'identité
- Requête KQL sur
SigninLogs(issue de l'article) → règle d'alerte (toutes les 15 min). - Action Group : webhook Logic App + Teams/JIRA.
- Étapes de la Logic App :
- Récupérer les détails de l'utilisateur + l'historique des connexions (Graph).
- Vérifier la dernière MFA réussie.
- Branchement :
- Faible impact : notification + ticket.
- Fort impact : Approbation (Service Owner) → mise à jour
conditionalAccessvia Graph ou blocage temporaire. - Consigner le résultat dans Log Analytics.
Flux runtime/politique
- Kyverno → envoie les événements de politique vers une table Log Analytics (via OTel ou les diagnostics AKS).
- Alerte KQL sur les nouveaux échecs d'enforcement pour
disallow-privileged. - Logic App :
- Récupérer les métadonnées du Deployment/Pod.
- Notifier le propriétaire du service avec le snippet de remédiation.
- Approbation facultative →
az aks command invokeou PR GitOps pour revert/patch.
Quand reporter (pour l'instant)
- Cluster unique, petite équipe ou absence de culture d'automatisation d'astreinte.
- Si vous n'avez pas les privilèges Entra/Graph pour appliquer l'accès conditionnel — démarrez par l'observabilité + tickets, ajoutez l'enforcement plus tard.
Besoin d'un coup de main ? Nous sommes là.
Si vous évaluez cette approche dans le cadre d'un proof of concept ou si vous planifiez un déploiement, DoiT peut vous accompagner. Notre équipe de plus de 100 experts est spécialisée dans des solutions cloud sur mesure, prêtes à vous guider tout au long du processus et à optimiser votre infrastructure pour la conformité comme pour les exigences à venir.
Échangeons sur l'approche la plus pertinente pour votre entreprise durant cette phase d'application des politiques, afin de garantir une infrastructure cloud robuste, conforme et optimisée. Contactez-nous dès aujourd'hui.