
未来を予測するのは難しい、なんて誰が言ったのでしょう?必要なのはProphet(と、信頼できるインフラ)だけです。
ユーザーがクラウドコストをより手軽に分析できる支出管理システムを、私たちのチームで先日構築しました。さらに一歩踏み込み、ワンクリックで未来を覗ける予測機能まで提供したいと考えたのです。そこで、FacebookのProphetをはじめとする実力派の予測ツールをベースにソリューションを組み上げました。今回はその過程で得た知見をご紹介します。
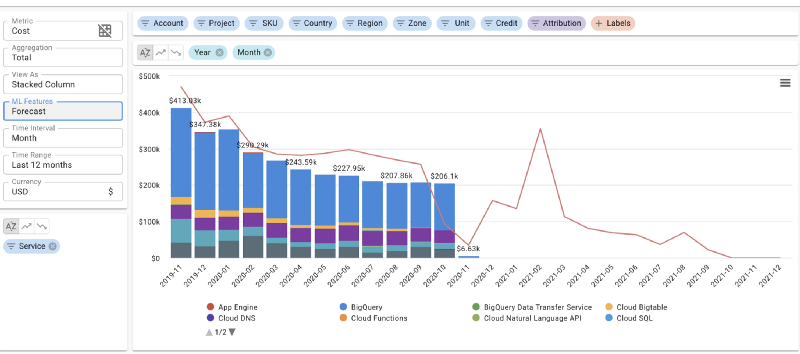
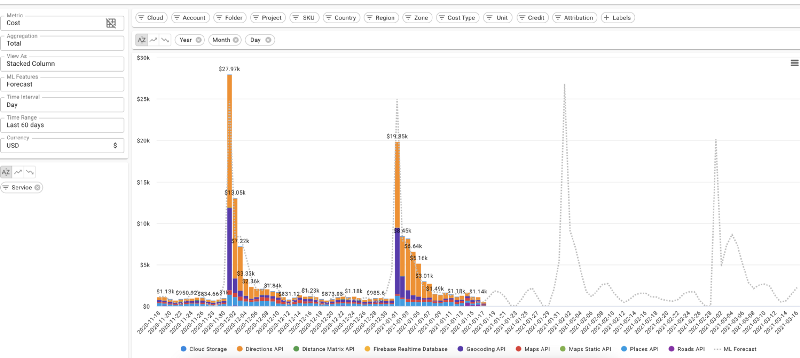 DoiT Cloud Intelligence™ 上での日次クラウドコスト予測
DoiT Cloud Intelligence™ 上での日次クラウドコスト予測
コツ #1:Prophetの得手不得手を知る
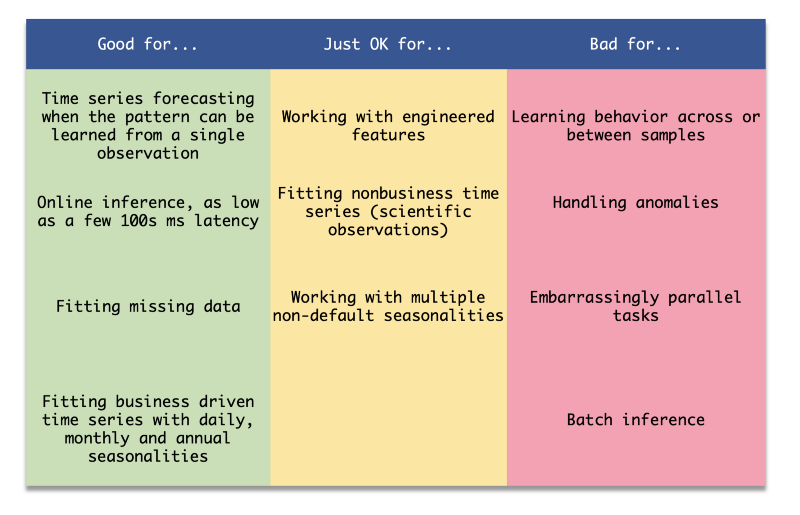
Prophetは_特定の_問題に対しては優秀なライブラリですが、タスクによっては他のツールに見劣りすることもあります。では何が得意なのか。Prophetは系列データそのものから、その系列の予測を生成するのが_とても_得意です。一方で、特徴量を追加したい場合や、似た挙動を示す系列同士から学習させたい場合(例:似たような使われ方をしている複数のアカウントがある場合)には、それほど力を発揮しません。
 Prophetのサマリーテーブル
Prophetのサマリーテーブル
Prophetの使い方は、ニューラルネットワークベースのサービスでよくある流れとは違います。シリアライズした学習済みモデルを保持してリアルタイムに推論を呼び出すのではなく、呼び出しごとに学習と予測を行います。そのため、1リクエストの処理に複数のCPUコア(8コア程度あれば十分)を要します。
もう一つの特徴は、ビジネス系のトレンド(日次・月次の季節性など)に合うよう設計されている点です。そのため、それ以外のタイプの時系列(無線信号など)には、デフォルトのままだと十分な精度が出ないことがあります。Prophetが想定していない問題に直面したら、NeuralProphet、DeepAR、ARIMA、その他の時系列予測に特化したアルゴリズム・ライブラリ・クラウドサービスを検討してみてください。
コツ #2:Prophetのサブクラスを作る
Prophetはデフォルト設定でも驚くほど高精度な予測を返してくれます。とはいえ、世の中うまい話ばかりではありません。トレンドによっては季節性の要素が強いものもあれば、変化点が少なく滑らかなものもあります。Prophetはpandasのtime offsetsと同じ長大な頻度リストをサポートしますが、自分のアプリでそのすべてを扱う必要があるとは限りません。
たとえば、日次・週次・_月次_といった限られた頻度だけサポートしたいケースもあるでしょう。そんなときは、頻度ごとにProphetのサブクラスを作り、クラスごとに以下を個別に設定すると便利です。
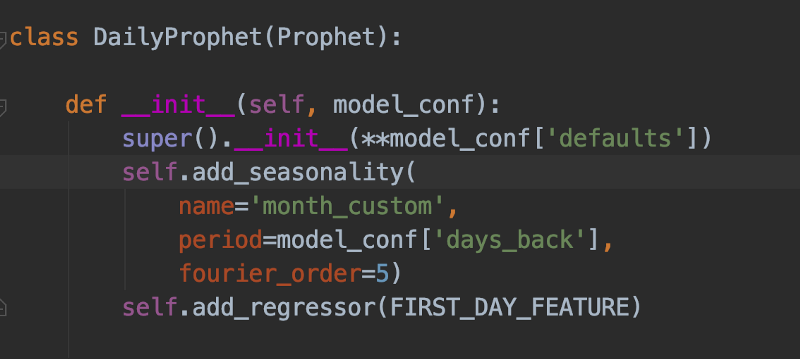 Daily prophetはProphetを継承し、カスタムパラメータで初期化され、"月初日"にフィットする回帰と前月比のカスタム季節性を備えています。トレローニー先生もきっと誇らしく思うはず…
Daily prophetはProphetを継承し、カスタムパラメータで初期化され、"月初日"にフィットする回帰と前月比のカスタム季節性を備えています。トレローニー先生もきっと誇らしく思うはず…
クラスごとに最適なパラメータを見つけるには、データセットを構築してハイパーパラメータのチューニングジョブを回すのがおすすめです。平均二乗誤差や平均絶対パーセント誤差といった客観指標で、他より優れたパラメータの組み合わせを探してみましょう。
私たちのケースでは、日次データに毎月初日のサポート費用など、月次の繰り返し請求が含まれていました。さらに、Google CloudやAWSの割引制度の影響で、データが月単位で相関する傾向もありました。そこで、専用のDaily-Prophetオブジェクトを用意し、毎月1日に対応するカスタム回帰変数を追加し、30.5日のカスタム季節性を設定することで、予測精度を引き上げました。あわせて、このオブジェクトのsuper()メソッドを、日次予測向けに最適化したカスタムハイパーパラメータで初期化しています。
コツ #3:ProphetにはCPUとRAMをたっぷり与える
Prophetを使ったサービスは簡単にコンテナ化でき、Google CloudのCloud Runなどで提供できます。ただし、pystanベースのこのライブラリはリソースを大量に消費します。運用のしやすさとパフォーマンスの両立という観点で最適だったのは、Anthos(GKE)上のCloud Runにデプロイする構成でした。
これにより、ネイティブのCloud Runに比べて予測時間を60%短縮できる、強力なコンピュート最適化マシンでサービスを動かせるようになりました。サービスは与えたコアとRAMを使い切るため、各Cloud Runインスタンスが並列で受けるリクエスト数も少数に絞り、Cloud RunとGKEのスケールアップ/ダウンの俊敏さを活かしています。
 8vCPUのc2マシンで構成された大型ノードプール。開発環境の一部として稼働しています
8vCPUのc2マシンで構成された大型ノードプール。開発環境の一部として稼働しています
コツ #4:プロットを忘れずに、ビジネス知見を組み込む
得られたトレンドを目で見て確認することが、テストセットでのスコア評価よりも重要な場面があります。平均二乗誤差を最小化していても、そのスコアでは捉えきれていないビジネス上の挙動が抜け落ちていることがあるからです。
私たちのケースでは、クラウド支出は線形には伸びないことが分かりました。むしろ、財務的な制約から導かれる漸近線(容量上限)を持つロジスティック関数として捉えるほうが実態に合います。
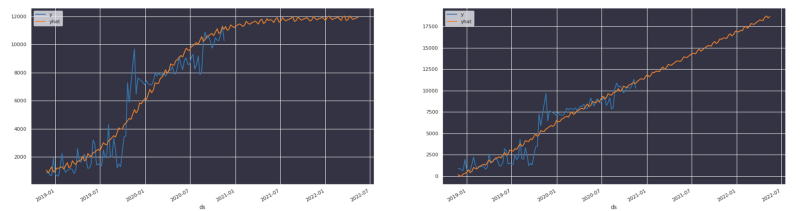 売上もこのまま伸び続けてほしいところですが、現実には成長はやがて鈍化し、漸近線にぶつかる可能性が高いものです。私たちはドメイン知識を使ってこの上限を指定します
売上もこのまま伸び続けてほしいところですが、現実には成長はやがて鈍化し、漸近線にぶつかる可能性が高いものです。私たちはドメイン知識を使ってこの上限を指定します
コツ #5:自信がないなら、不確実性をきちんと示そう
ユーザーは予測の誤差幅が小さいことを期待しがちで、その期待値は時系列予測ツールから現実的に得られる精度よりもかなり厳しいことが多いと分かりました。
上の画像を見れば一目瞭然ですが、Prophetが返すのは元のトレンドの推定であって、必ずしも実際の数値そのものではありません。そのため、元のトレンドにそっくりな予測を見せられると、ユーザーはひどく混乱してしまいます。
そこで、次のような工夫を検討してみてください。
- 予測値はグレーの点線で表示する。
- 信頼区間を併せて示す。
- 可能であれば"yhat"(予測値)を"y"(過去の実績値)で置き換えることを検討する。
区間の幅はコンストラクタにパラメータとして渡すことで調整できます
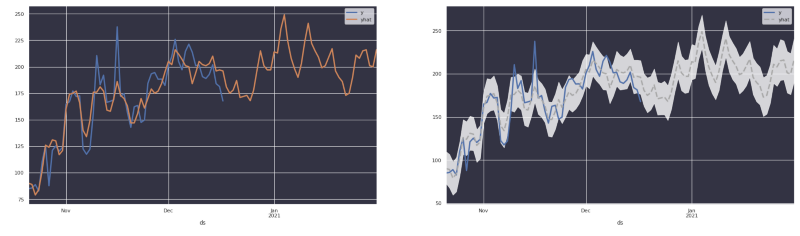 デザインの工夫で実績値と推定値を区別し、不確実性も可視化!
デザインの工夫で実績値と推定値を区別し、不確実性も可視化!
コツ #6:前処理と後処理を活用する
予測用にデータを送るとき、アルゴリズムはその時系列がどんな文脈で生成されたかを知らない、という事実をついつい忘れがちです。
私たちのケースでは、月次の予測を出すために集計済みの月次コストデータを送っていました。すると、月の最初の数週間は最新の観測値が大幅に低くなり、Prophetが将来のトレンドに急落をフィットさせてしまっていたのです。明らかに不正確だと分かっているデータポイントを取り除くだけで、結果は劇的に改善します。Prophetは欠損値をうまく扱えるので、ノイズを無理にフィットさせるくらいなら捨ててしまったほうが良い場面は意外と多いものです。
 予測サービスに送った月次データ。Prophetは、この落ち込みがデータの欠落によるものだとは"知らない"
予測サービスに送った月次データ。Prophetは、この落ち込みがデータの欠落によるものだとは"知らない"
処理による改善策としては、Pandasの_rolling_関数を使って結果にスライディングウィンドウフィルタをかける方法もあります。
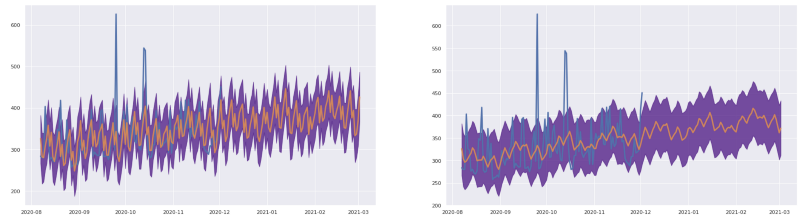 元データはノイズが多すぎますが、ビジネス的に妥当であれば移動平均をかけることで、より滑らかなトレンドを得られます
元データはノイズが多すぎますが、ビジネス的に妥当であれば移動平均をかけることで、より滑らかなトレンドを得られます
コツ #7:不確実性の計算を省いて推論を高速化する
Prophetはデータに確率モデルをフィットさせ、その分布を反復サンプリングしてノイズ(および対応する予測区間)を推定します。
サービスのランプロファイリングをかけてみたところ、このサンプリング処理がプログラム全体の実行時間のかなりの部分を占めていると分かりました。このイテレーションは、ノイズ推定に十分なサンプル数が得られるまで何度も繰り返されます。予測区間が不要であれば、uncertainty_samplesパラメータを小さい値(0でも構いません)に設定することで、プログラムの実行時間を大幅に短縮できます!
 フィット済みモデルのノイズ推定に使われるこのコード部分は非常に時間がかかります。不確実性の推定が要らないなら、思い切ってスキップしてしまいましょう!
フィット済みモデルのノイズ推定に使われるこのコード部分は非常に時間がかかります。不確実性の推定が要らないなら、思い切ってスキップしてしまいましょう!
もちろん、このコツは「不確実性を見せることが大事」と説いたコツ #5と矛盾します。ソフトウェア開発は結局のところトレードオフの連続、ということでしょうか :)
以上です!ご意見・ご感想があれば、ぜひ下のコメント欄にお寄せください!
Gad BenramはDoiT InternationalのOffice of the CTOに所属するシニアリサーチエンジニアです。Gadと一緒に働いてみたい方は、ぜひ採用ページをご覧ください。