
Qui a dit que prédire l'avenir était difficile ? Il suffit d'un Prophet (et d'une infrastructure solide).
Mon équipe et moi venons de créer un système de pilotage des dépenses cloud pour aider les utilisateurs à analyser plus facilement leurs coûts. Nous voulions aussi aller plus loin et leur donner un aperçu de l'avenir grâce à des prévisions en un clic. Pour y parvenir, nous nous sommes appuyés sur des outils de prévision particulièrement performants, dont Prophet de Facebook, et il nous a semblé utile de partager ce que nous en avons retiré.
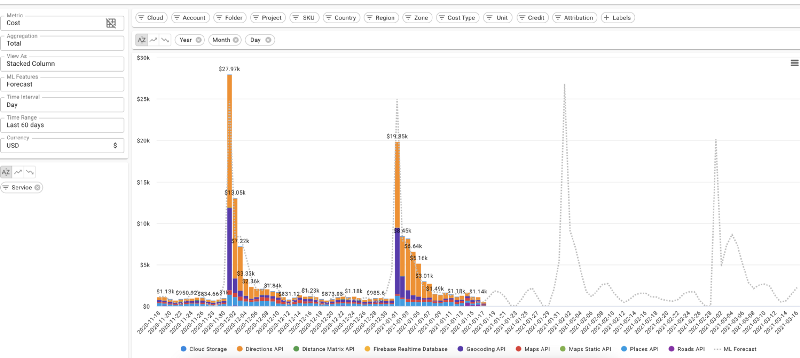 Prévision quotidienne des coûts cloud, dans DoiT Cloud Intelligence™
Prévision quotidienne des coûts cloud, dans DoiT Cloud Intelligence™
Astuce n°1 : apprenez à connaître Prophet
Prophet est une excellente bibliothèque pour certains problèmes, mais d'autres outils peuvent facilement faire mieux sur certaines tâches. Quels sont ses atouts ? Prophet excelle vraiment pour générer les prévisions d'une série à partir de ses propres données. Il est moins à l'aise dès qu'il s'agit d'ajouter des variables ou d'apprendre à partir de séries similaires (par exemple, lorsque l'on dispose de plusieurs comptes au comportement comparable).
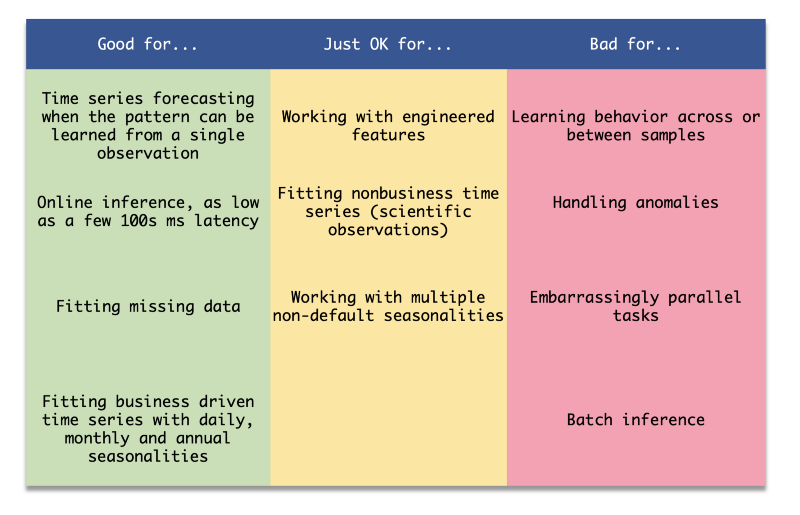 Tableau récapitulatif sur Prophet
Tableau récapitulatif sur Prophet
Travailler avec Prophet ne ressemble pas à l'usage habituel des services fondés sur des réseaux de neurones. Au lieu de conserver un modèle entraîné sérialisé et d'invoquer des prédictions en temps réel, on entraîne et on prédit le modèle à chaque appel. C'est pourquoi il faut plusieurs cœurs de CPU (8 cœurs environ font l'affaire) pour traiter une seule requête.
Autre particularité : la bibliothèque a été pensée pour s'adapter aux tendances métier (saisonnalités quotidiennes et mensuelles). En dehors de ce cadre, Prophet peut s'avérer moins performante sur d'autres types de séries temporelles (signaux radio, par exemple). Si votre problème ne correspond pas à ce pour quoi Prophet est optimisée, vous pouvez vous tourner vers NeuralProphet, DeepAR, ARIMA ou d'autres algorithmes, bibliothèques et outils cloud spécialisés dans la prévision de séries temporelles.
Astuce n°2 : créez des sous-classes de Prophet
Telle quelle, Prophet génère des prévisions d'une précision remarquable. Mais rien n'est jamais gratuit. Certaines tendances ont une composante saisonnière plus marquée, d'autres sont plus lisses avec moins de points de rupture, etc. Prophet prend en charge la même longue liste de fréquences que les décalages temporels de pandas, mais votre application n'a pas forcément besoin de toutes les gérer.
Vous souhaitez peut-être ne couvrir qu'un nombre restreint et fini de fréquences, comme Quotidien, Hebdomadaire et Mensuel. Dans ce cas, il est pertinent de créer une sous-classe de Prophet par fréquence et de la paramétrer différemment :
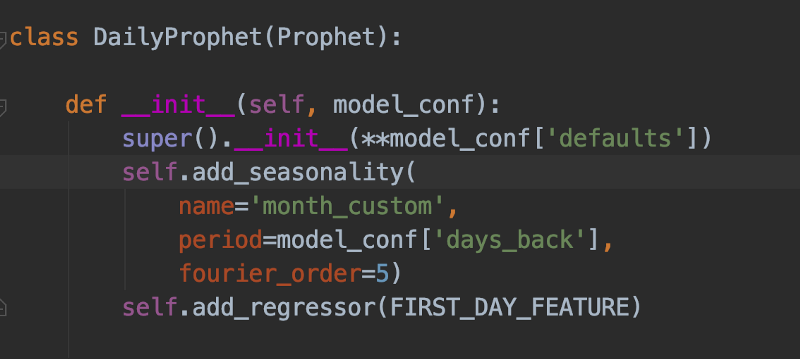 Daily Prophet hérite de Prophet, est initialisée avec des paramètres personnalisés, intègre une régression calée sur le premier jour du mois et une saisonnalité personnalisée d'un mois sur l'autre. Le professeur Trelawney en aurait été fier…
Daily Prophet hérite de Prophet, est initialisée avec des paramètres personnalisés, intègre une régression calée sur le premier jour du mois et une saisonnalité personnalisée d'un mois sur l'autre. Le professeur Trelawney en aurait été fier…
Pour trouver les paramètres optimaux par classe, constituez un jeu de données et lancez un job d'optimisation d'hyperparamètres. Cherchez un jeu de paramètres qui surpasse les autres sur des métriques objectives comme l'erreur quadratique moyenne ou l'erreur absolue moyenne en pourcentage.
Dans notre cas, les données quotidiennes contenaient des facturations mensuelles récurrentes (comme votre facture de support) qui apparaissent le 1er de chaque mois. Nous avons aussi remarqué que les données étaient corrélées d'un mois sur l'autre, en raison des régimes de remises appliqués par Google Cloud et AWS. Nous avons gagné en précision en créant un objet Daily-Prophet dédié, en ajoutant un régresseur personnalisé pour le 1er de chaque mois et en le paramétrant avec une saisonnalité personnalisée de 30,5 jours. Nous avons également initialisé la méthode super() de cet objet avec des hyperparamètres optimisés pour les prédictions quotidiennes.
Astuce n°3 : donnez à Prophet assez de CPU et de RAM
Le service Prophet se conteneurise facilement et se déploie sur des outils comme Cloud Run de Google Cloud. Cette bibliothèque, qui repose sur pystan, peut toutefois être très gourmande en ressources. Le meilleur compromis entre simplicité de gestion et performance, c'est, selon notre expérience, le déploiement du service sur Cloud Run for Anthos (GKE).
Nous avons ainsi pu fournir au service de puissantes machines optimisées pour le calcul, qui ont réduit le temps de prédiction de 60 % par rapport à Cloud Run natif. Comme le service utilisait à plein tous les cœurs et la RAM mis à disposition, nous avons aussi limité chaque instance Cloud Run à un faible nombre de requêtes en parallèle, en tirant parti de la capacité de Cloud Run et de GKE à monter et descendre en charge rapidement.
 Un node-pool généreusement dimensionné, équipé de machines c2 dotées chacune de 8 vCPU, dans l'environnement de développement
Un node-pool généreusement dimensionné, équipé de machines c2 dotées chacune de 8 vCPU, dans l'environnement de développement
Astuce n°4 : visualisez et intégrez davantage de connaissance métier
Observer les tendances obtenues compte parfois plus que d'évaluer ses résultats sur un jeu de test. On peut bien optimiser l'erreur quadratique moyenne, ce score ne reflétera pas toujours certains comportements métier qui vous auront échappé.
Dans notre cas, nous avons constaté que les dépenses cloud ne croissent pas linéairement. Elles correspondent plutôt à une fonction logistique assortie d'une asymptote (limite de capacité) issue de considérations financières.
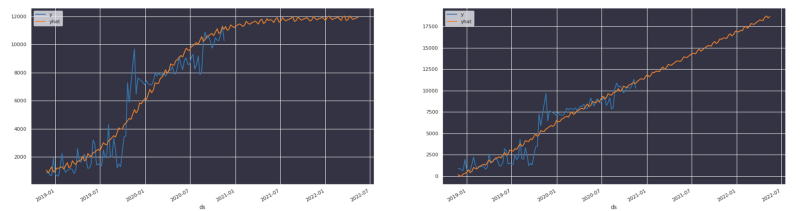 On aimerait tous voir ses revenus croître ainsi, mais il est plus probable que la croissance finisse par s'essouffler et bute sur une asymptote. Nous mobilisons la connaissance métier pour fixer cette limite
On aimerait tous voir ses revenus croître ainsi, mais il est plus probable que la croissance finisse par s'essouffler et bute sur une asymptote. Nous mobilisons la connaissance métier pour fixer cette limite
Astuce n°5 : un doute ? Affichez votre incertitude !
Nous avons remarqué que les utilisateurs s'attendent souvent à une marge d'erreur faible — souvent plus faible que ce que l'on peut raisonnablement attendre d'un outil de prévision de séries temporelles.
Sur les images ci-dessus, on voit clairement que Prophet renvoie une estimation de la tendance d'origine, et pas nécessairement les valeurs réelles. Les utilisateurs sont alors déconcertés face à une prévision qui ressemble à la tendance d'origine.
Vous pouvez donc envisager les approches suivantes :
- Tracer la prévision en pointillés gris.
- Ajouter un intervalle de confiance.
- Remplacer dès que possible yhat (prédictions) par y (observations historiques).
La largeur des intervalles se contrôle en la passant en paramètre au constructeur.
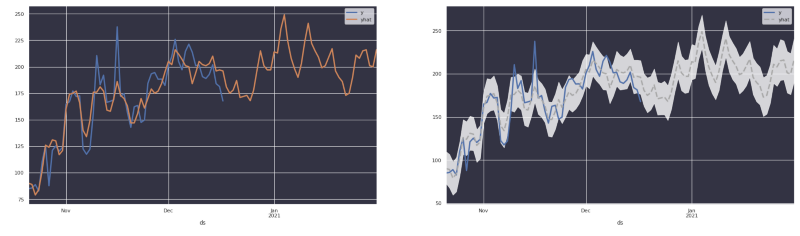 Le design permet de distinguer les valeurs réelles des estimations tout en visualisant l'incertitude.
Le design permet de distinguer les valeurs réelles des estimations tout en visualisant l'incertitude.
Astuce n°6 : pensez au pré- et post-traitement
Quand on envoie des données pour prédiction, on oublie parfois que les algorithmes ignorent le contexte dans lequel la série temporelle a été générée.
Dans notre cas, nous transmettions des données de coûts agrégées au mois pour produire des prévisions mensuelles. Lors des premières semaines de chaque mois, la dernière observation était nettement plus basse, et Prophet modélisait alors une chute brutale dans la tendance future. Supprimer les points que l'on sait corrompus améliore considérablement les résultats. N'oubliez pas que Prophet gère bien les valeurs manquantes : mieux vaut souvent écarter le bruit que de l'apprendre.
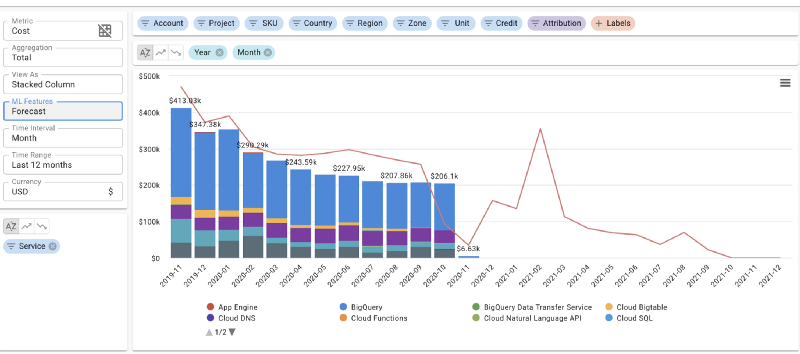 Données mensuelles envoyées au service de prévision. Prophet ignore que la chute correspond à des données manquantes
Données mensuelles envoyées au service de prévision. Prophet ignore que la chute correspond à des données manquantes
Autre piste d'amélioration par traitement : utiliser la fonction rolling de Pandas pour appliquer des filtres à fenêtre glissante sur les résultats.
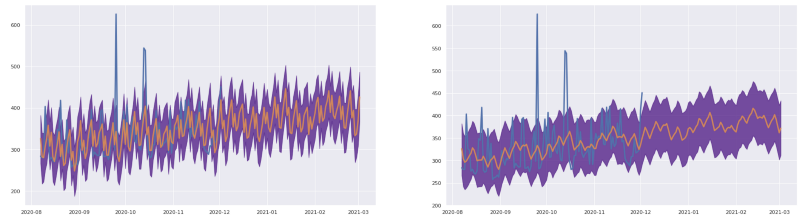 Les données d'origine sont trop bruitées : on peut leur appliquer une moyenne glissante pour obtenir une tendance plus lisse, lorsque cela a du sens d'un point de vue métier
Les données d'origine sont trop bruitées : on peut leur appliquer une moyenne glissante pour obtenir une tendance plus lisse, lorsque cela a du sens d'un point de vue métier
Astuce n°7 : accélérez l'inférence en ignorant l'incertitude
Prophet ajuste un modèle probabiliste aux données puis échantillonne itérativement la distribution pour estimer le bruit (et les intervalles de prédiction qui lui sont associés).
Après avoir profilé l'exécution de mon service, j'ai constaté que ce processus d'échantillonnage représente une part assez importante du temps d'exécution global. Cette itération tourne de nombreuses fois jusqu'à générer assez d'échantillons pour estimer le bruit. Si les intervalles de prédiction ne vous intéressent pas, abaissez le paramètre uncertainty_samples (jusqu'à 0 si besoin) pour réduire significativement le temps d'exécution.
 Cette portion de code, qui sert à estimer le bruit du modèle ajusté, est très coûteuse en temps. Si vous n'avez pas besoin de l'estimation d'incertitude, passez-la !
Cette portion de code, qui sert à estimer le bruit du modèle ajusté, est très coûteuse en temps. Si vous n'avez pas besoin de l'estimation d'incertitude, passez-la !
Bien sûr, cette astuce contredit la n°5, qui rappelle l'importance d'afficher l'incertitude. Le développement logiciel, c'est toujours une affaire de compromis, non ? :)
Voilà, c'est tout ! Si vous avez des remarques, n'hésitez pas à les laisser ci-dessous.
Gad Benram est Senior Research Engineer au sein de l'Office of the CTO de DoiT International. Envie de travailler avec Gad ? Consultez notre page carrières.