
Quem disse que prever o futuro é difícil? Basta um Prophet (e uma infraestrutura confiável)
Recentemente, eu e meu time criamos um sistema de controle de gastos em nuvem que facilita a análise dos custos pelos usuários. Mas queríamos ir além e dar a eles um vislumbre do futuro, com previsões em um clique. Para isso, baseamos a solução em ferramentas de previsão muito robustas, entre elas o Prophet do Facebook, e achamos que valeria a pena compartilhar o que aprendemos!
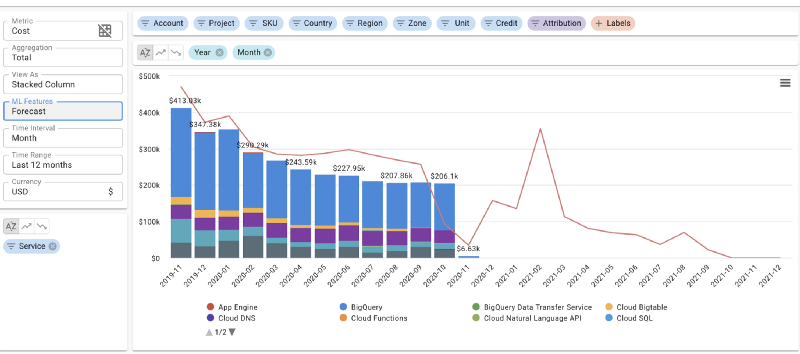
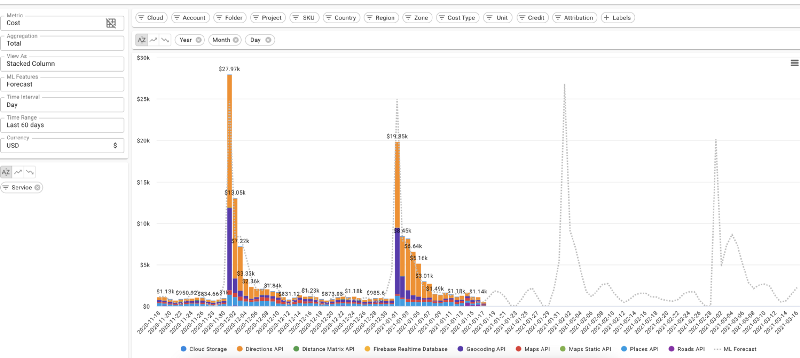 Previsão diária de custos em nuvem no DoiT Cloud Intelligence™
Previsão diária de custos em nuvem no DoiT Cloud Intelligence™
Dica nº 1: conheça seu Prophet
O Prophet é uma ótima biblioteca para certos problemas, mas pode facilmente perder para outras ferramentas em determinadas tarefas. Para o que ele serve bem? O Prophet é muito bom em gerar previsões de uma série usando os próprios dados dela. Já não vai tão bem quando você quer adicionar mais features ou aprender com séries semelhantes (por exemplo: quando você tem várias contas com comportamento parecido).
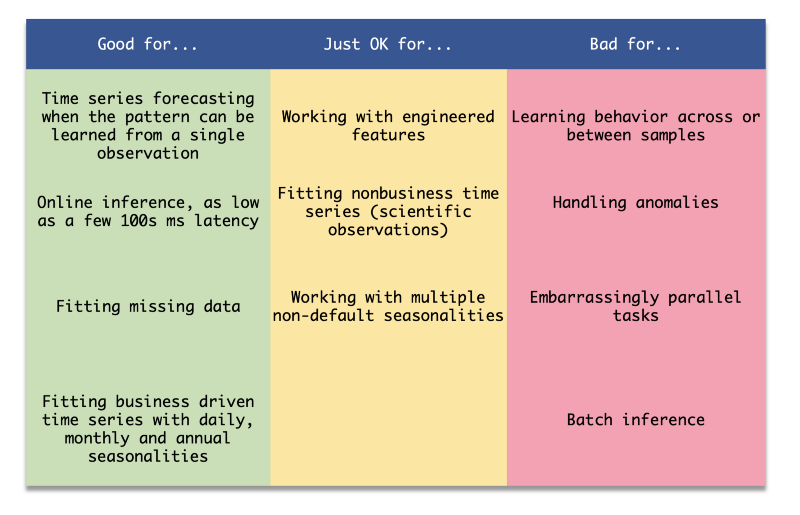 Tabela-resumo do Prophet
Tabela-resumo do Prophet
Trabalhar com o Prophet é diferente do que costumamos fazer com serviços baseados em redes neurais. Em vez de manter um modelo treinado serializado e acionar previsões em tempo real, você de fato treina e prevê o modelo a cada chamada. Por isso, são necessários vários núcleos de CPU (uns 8 costumam dar conta) para atender uma única requisição.
Outra característica da biblioteca é que ela foi desenhada para se ajustar a tendências ligadas a negócios (como sazonalidades diárias e mensais); de fábrica, o Prophet pode não se sair tão bem em outros tipos de série temporal (como sinais de rádio). Se você cair em um problema para o qual o Prophet não foi otimizado, pode valer a pena olhar para o NeuralProphet, o DeepAR, o ARIMA ou outros algoritmos, bibliotecas e ferramentas de nuvem especializados em previsão de séries temporais.
Dica nº 2: crie subclasses do Prophet
De fábrica, o Prophet consegue gerar previsões impressionantemente precisas. Mas, mesmo aqui, não existe almoço grátis. Algumas tendências têm um componente de sazonalidade mais forte que outras, enquanto outras costumam ser mais suaves, com menos pontos de mudança, e por aí vai. Embora o Prophet aceite a mesma longa lista de frequências dos time offsets do pandas, sua aplicação não precisa, necessariamente, dar suporte a todas elas.
Talvez você queira oferecer apenas um conjunto pequeno e finito de frequências, como Diária, Semanal e Mensal. Nesse caso, pode ser útil criar uma subclasse do Prophet por frequência e configurá-la de forma diferente em cada classe:
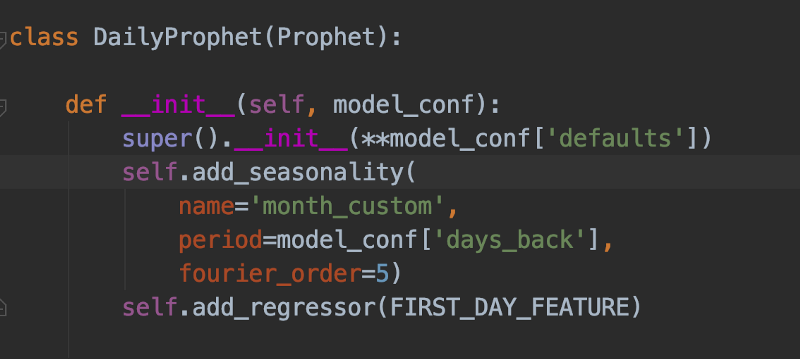 O Daily prophet herda do Prophet, é inicializado com parâmetros customizados, tem uma regressão que se ajusta ao "primeiro dia do mês" e uma sazonalidade customizada mês a mês. A Profa. Trelawney teria muito orgulho…
O Daily prophet herda do Prophet, é inicializado com parâmetros customizados, tem uma regressão que se ajusta ao "primeiro dia do mês" e uma sazonalidade customizada mês a mês. A Profa. Trelawney teria muito orgulho…
Para encontrar os parâmetros ótimos por classe, monte um dataset e rode um job de tuning de hiperparâmetros em cima dele. Veja se consegue achar um conjunto de parâmetros que supere os demais em métricas objetivas, como mean-squared-error ou mean-absolute-percentage-error.
No nosso caso, os dados diários traziam cobranças mensais recorrentes (como a fatura de suporte) que aparecem sempre no primeiro dia do mês. Além disso, percebemos que os dados têm correlação mês a mês, por causa de alguns regimes de desconto aplicados pelo Google Cloud e pela AWS. Melhoramos a precisão das previsões criando um objeto Daily-Prophet específico, adicionando um regressor customizado para o início do dia 1º de cada mês e configurando-o com uma sazonalidade customizada de 30,5 dias. Também inicializamos o método super() desse objeto com hiperparâmetros customizados, otimizados para previsões diárias.
Dica nº 3: dê CPU e RAM suficientes ao Prophet
O serviço do Prophet pode ser facilmente containerizado e servido em ferramentas como o Cloud Run do Google Cloud. Só que essa biblioteca, baseada em pystan, pode ser bem exigente em recursos. Para nós, a solução ideal em termos de gestão e desempenho foi implantar o serviço no Cloud Run sobre o Anthos (GKE).
Assim, conseguimos rodar o serviço em máquinas potentes e otimizadas para computação, que reduziram em 60% o tempo de previsão em relação ao Cloud Run nativo. Como o serviço usava todos os núcleos e a RAM disponíveis, também limitamos cada instância do Cloud Run a um número pequeno de requisições em paralelo, aproveitando a capacidade de escalar para cima e para baixo do Cloud Run e do GKE!
 Um node-pool robusto com máquinas c2, cada uma com 8 vCPUs, atuando como parte do ambiente de desenvolvimento
Um node-pool robusto com máquinas c2, cada uma com 8 vCPUs, atuando como parte do ambiente de desenvolvimento
Dica nº 4: não esqueça de plotar e incorporar mais conhecimento de negócio
Às vezes, olhar para as tendências geradas é mais importante do que avaliar os resultados em um conjunto de teste. Você pode até otimizar o mean-squared-error, mas, em alguns casos, esse número não vai refletir algum comportamento de negócio que ficou de fora.
No nosso caso, descobrimos que os gastos em nuvem não costumam crescer de forma linear. Eles se comportam mais como uma função logística, com uma assíntota (limite de capacidade) que vem de considerações financeiras.
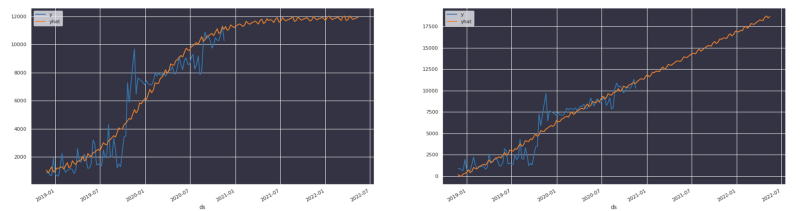 Por mais que a gente queira que a receita cresça desse jeito, é mais provável que o crescimento desacelere e bata em uma assíntota. Usamos conhecimento de domínio para definir esse limite
Por mais que a gente queira que a receita cresça desse jeito, é mais provável que o crescimento desacelere e bata em uma assíntota. Usamos conhecimento de domínio para definir esse limite
Dica nº 5: na dúvida? Mostre sua incerteza!
Aprendemos que os usuários tendem a esperar uma margem de erro pequena na previsão — muitas vezes, menor do que se pode esperar de forma realista de uma ferramenta de previsão de séries temporais.
Nas imagens acima dá para ver claramente que, ao usar o Prophet, a biblioteca devolve uma estimativa da tendência original, e não necessariamente os números reais. Os usuários ficam bem confusos quando recebem uma previsão parecida demais com a tendência original.
Por isso, vale considerar o seguinte:
- Represente a previsão como uma linha cinza pontilhada.
- Adicione um intervalo de confiança.
- Considere substituir "yhat" (previsões) por "y" (observações históricas) sempre que possível.
Você pode controlar a largura dos intervalos passando-a como parâmetro no construtor
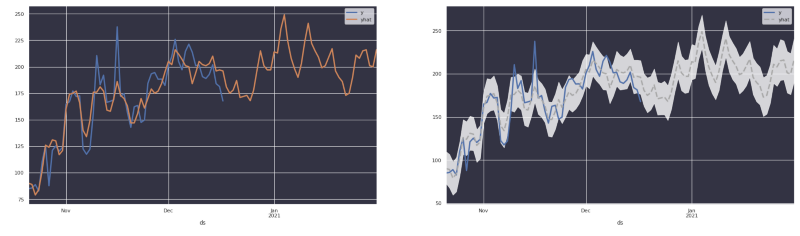 Usando o design para diferenciar valores reais de estimativas e ainda visualizar a incerteza!
Usando o design para diferenciar valores reais de estimativas e ainda visualizar a incerteza!
Dica nº 6: use pré-processamento e pós-processamento
Ao enviar dados para previsão, é fácil esquecer que os algoritmos não conhecem o contexto em que a série temporal foi gerada.
No nosso caso, costumávamos enviar dados de custo agregados por mês para gerar previsões mensais. Nas primeiras semanas de cada mês, a última observação era bem mais baixa, e isso fazia o Prophet ajustar uma queda brusca na tendência futura. Remover pontos que sabemos estar corrompidos pode melhorar drasticamente os resultados. Lembre-se: o Prophet lida bem com valores ausentes, então muitas vezes é melhor descartar o ruído do que ajustar a ele!
 Dados mensais enviados ao serviço de previsão. O Prophet "não sabe" que a queda se deve a dados ausentes
Dados mensais enviados ao serviço de previsão. O Prophet "não sabe" que a queda se deve a dados ausentes
Outras opções de melhoria via processamento incluem usar a função rolling do Pandas para aplicar filtros de janela deslizante aos resultados.
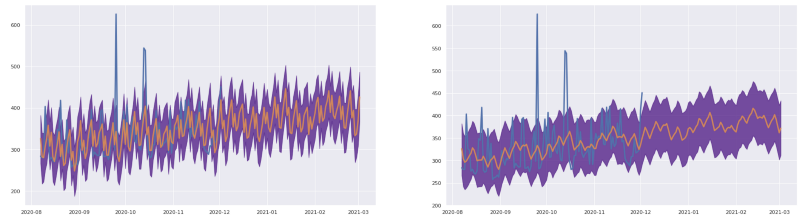 Os dados originais são ruidosos demais, mas podemos aplicar uma janela de média móvel e ver uma tendência mais suave, se isso fizer sentido para o negócio
Os dados originais são ruidosos demais, mas podemos aplicar uma janela de média móvel e ver uma tendência mais suave, se isso fizer sentido para o negócio
Dica nº 7: acelere a inferência ignorando a incerteza
O Prophet ajusta um modelo probabilístico aos dados e, depois, amostra a distribuição de forma iterativa para estimar o ruído (e os intervalos de previsão associados a ele).
Depois de rodar alguns profilings de execução no meu serviço, descobri que esse processo de amostragem responde por boa parte do tempo total de execução do programa. Essa iteração roda várias vezes, até gerar amostras suficientes para estimar o ruído. Se você não tem interesse nos intervalos de previsão, pode reduzir o parâmetro uncertainty_samples para um valor menor (até 0) e reduzir significativamente o tempo de execução do programa!
 Essa parte do código, usada para estimar o ruído do modelo ajustado, consome muito tempo; mas, se você não precisa da estimativa de incerteza, é só pular!
Essa parte do código, usada para estimar o ruído do modelo ajustado, consome muito tempo; mas, se você não precisa da estimativa de incerteza, é só pular!
Claro, essa dica vai contra a dica nº 5, que fala da importância de apresentar a incerteza. Mas desenvolvimento de software é sempre uma questão de trade-offs, né? :)
É isso, pessoal! Se tiver algum comentário, fique à vontade para deixar aqui embaixo!
Gad Benram é Senior Research Engineer no Office of the CTO da DoiT International. Quer trabalhar com o Gad? Confira nossa página de carreiras.