
Chi ha detto che prevedere il futuro è difficile? Basta un Prophet (e un'infrastruttura affidabile)
Insieme al mio team ho costruito di recente un sistema di controllo della spesa cloud che aiuta gli utenti ad analizzare più facilmente i propri costi cloud. Ma volevamo spingerci oltre e dare agli utenti uno sguardo sul futuro con previsioni a portata di clic. Per riuscirci ci siamo affidati a strumenti di forecasting di alto livello, tra cui Prophet di Facebook, e abbiamo pensato di condividere ciò che abbiamo imparato lungo il percorso!
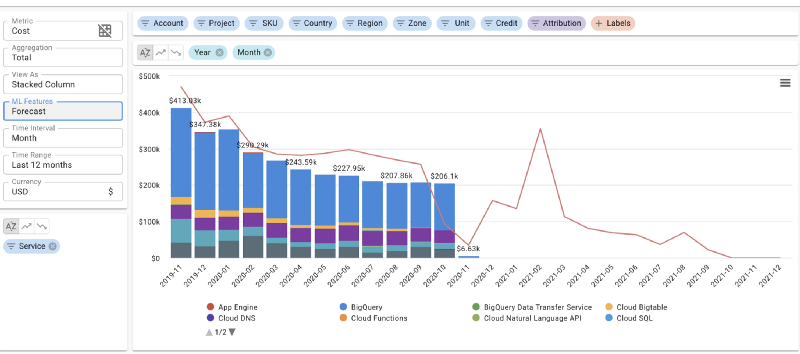
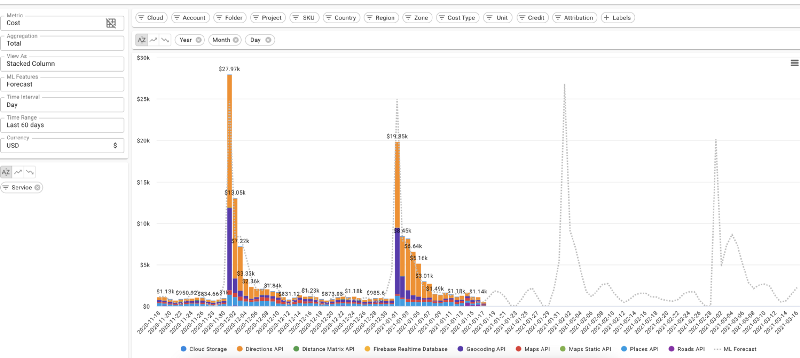 Previsione dei costi cloud giornalieri su DoiT Cloud Intelligence™
Previsione dei costi cloud giornalieri su DoiT Cloud Intelligence™
Consiglio #1: conosci il tuo Prophet
Prophet è un'ottima libreria per certi problemi, ma in altri casi può facilmente risultare meno performante di strumenti diversi. In cosa eccelle? Prophet è davvero bravo nel generare previsioni per una serie utilizzando i dati della serie stessa. Lo è meno quando si vogliono aggiungere altre feature o si vuole imparare da serie simili (ad esempio, quando si hanno più account con un comportamento analogo).
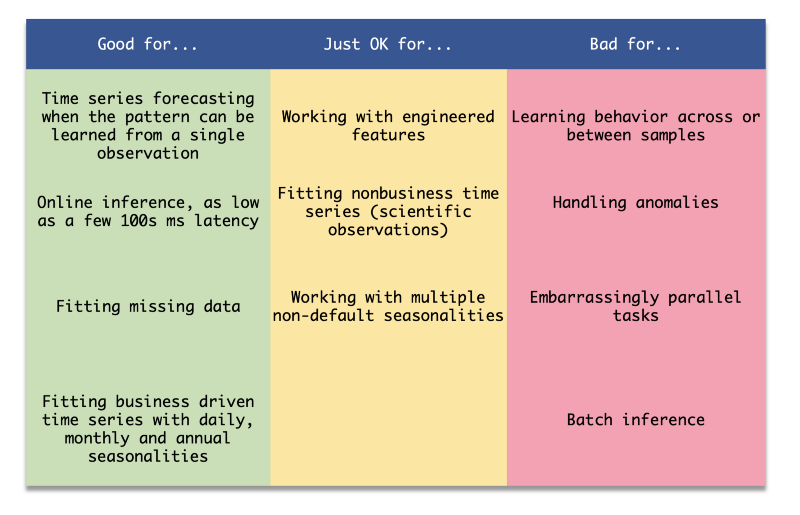 Tabella riassuntiva di Prophet
Tabella riassuntiva di Prophet
Lavorare con Prophet è diverso da come ci si abitua a fare con i servizi basati su reti neurali. Invece di mantenere un modello addestrato e serializzato e di invocarne le previsioni in tempo reale, qui si addestra il modello e si effettua la previsione a ogni chiamata. Per questo motivo servono più core CPU (intorno a 8 dovrebbero bastare) per gestire una singola richiesta.
Un'altra caratteristica della libreria è che è progettata per intercettare trend di tipo business (come stagionalità giornaliere e mensili): di default Prophet potrebbe non comportarsi altrettanto bene su altri tipi di serie temporali (come i segnali radio). Se ti trovi davanti a un problema per cui Prophet non è ottimizzato, puoi valutare NeuralProphet, DeepAR, ARIMA o altri algoritmi, librerie e strumenti cloud specializzati nel forecasting di serie temporali.
Consiglio #2: crea sottoclassi di Prophet
Out of the box, Prophet riesce a generare previsioni incredibilmente accurate. Ma non c'è mai un pasto gratis, nemmeno in questo caso. Alcuni trend hanno una componente di stagionalità più marcata di altri, alcuni sono più regolari e con meno change-point, e così via. Prophet supporta lo stesso lungo elenco di frequenze degli offset temporali di pandas, ma la tua applicazione non è detto debba supportarle tutte.
Magari ti basta gestire un set ristretto e ben definito di frequenze, come giornaliera, settimanale e mensile. In questo caso può essere utile creare una sottoclasse di Prophet per ogni frequenza e configurarla in modo diverso per ciascuna classe:
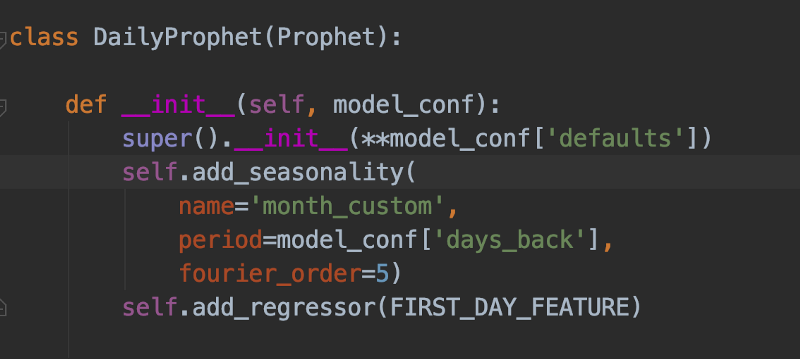 Daily prophet eredita da Prophet, viene inizializzato con parametri personalizzati, ha una regressione che intercetta il "primo giorno del mese" e una stagionalità personalizzata mese su mese. La professoressa Cooman ne sarebbe stata fiera…
Daily prophet eredita da Prophet, viene inizializzato con parametri personalizzati, ha una regressione che intercetta il "primo giorno del mese" e una stagionalità personalizzata mese su mese. La professoressa Cooman ne sarebbe stata fiera…
Per individuare i parametri ottimali di ciascuna classe puoi costruire un dataset ed eseguire un job di hyperparameter tuning. Cerca un set di parametri che batta gli altri su metriche oggettive come mean-squared-error o mean-absolute-percentage-error.
Nel nostro caso i dati giornalieri contenevano fatturazioni mensili ricorrenti (come la fattura del supporto) che compaiono il primo giorno di ogni mese. Inoltre abbiamo notato che i dati tendono a essere correlati di mese in mese a causa di alcuni regimi di sconto applicati da Google Cloud e AWS. Abbiamo migliorato l'accuratezza delle previsioni creando un oggetto Daily-Prophet dedicato, aggiungendo un regressore personalizzato per il 1° di ogni mese e impostando una stagionalità personalizzata di 30,5 giorni. Abbiamo anche inizializzato il metodo super() di questo oggetto con iperparametri ottimizzati per le previsioni giornaliere.
Consiglio #3: dai a Prophet abbastanza CPU e RAM
Il servizio di Prophet può essere facilmente containerizzato ed esposto tramite strumenti come Cloud Run di Google Cloud. Tuttavia questa libreria, basata su pystan, può essere molto esigente in termini di risorse. Abbiamo scoperto che la soluzione ottimale, sia per facilità di gestione sia per prestazioni, era distribuire il servizio su Cloud Run su Anthos (GKE).
In questo modo siamo riusciti a dotare il servizio di macchine potenti e compute-optimized che hanno ridotto del 60% i tempi di previsione rispetto a Cloud Run nativo. Dato che il servizio sfruttava tutti i core e la RAM messi a disposizione, abbiamo anche limitato ogni istanza di Cloud Run alla gestione di poche richieste in parallelo, sfruttando la capacità di Cloud Run e GKE di scalare rapidamente verso l'alto e verso il basso.
 Un node-pool generoso con macchine c2, ciascuna con 8 vCPU, parte dell'ambiente di sviluppo
Un node-pool generoso con macchine c2, ciascuna con 8 vCPU, parte dell'ambiente di sviluppo
Consiglio #4: non dimenticare di tracciare i grafici e di portare più conoscenza di business
A volte osservare i trend ottenuti conta più che valutare i risultati su un test-set. Anche ottimizzando il mean-squared-error, in certi casi questo punteggio non riflette comportamenti di business che non sei riuscito a catturare.
Nel nostro caso abbiamo imparato che la spesa cloud non tende a crescere in modo lineare. Si descrive meglio come una funzione logistica con un asintoto (limite di capacità) derivato da considerazioni di natura finanziaria.
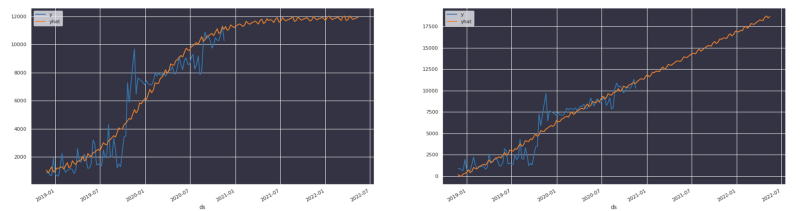 Per quanto possiamo augurarci che i ricavi crescano così, è più probabile che la crescita rallenti col tempo e tenda a un asintoto. Sfruttiamo la conoscenza del dominio per definire questo limite
Per quanto possiamo augurarci che i ricavi crescano così, è più probabile che la crescita rallenti col tempo e tenda a un asintoto. Sfruttiamo la conoscenza del dominio per definire questo limite
Consiglio #5: hai dei dubbi? Esprimi la tua incertezza!
Abbiamo notato che gli utenti tendono ad aspettarsi un margine di errore basso nelle previsioni — spesso più stretto di quanto sia realisticamente lecito attendersi da uno strumento di forecasting di serie temporali.
Nelle immagini sopra si vede chiaramente che, quando si usa Prophet, la libreria restituisce una stima del trend originale e non necessariamente i numeri reali. Gli utenti finiscono così per disorientarsi quando vedono una previsione molto simile al trend originale.
Per questo vale la pena considerare alcuni accorgimenti:
- Rappresenta la previsione con una linea grigia tratteggiata.
- Aggiungi un intervallo di confidenza.
- Valuta di sostituire "yhat" (previsioni) con "y" (osservazioni storiche) quando possibile.
Puoi controllare l'ampiezza degli intervalli passandola come parametro al costruttore
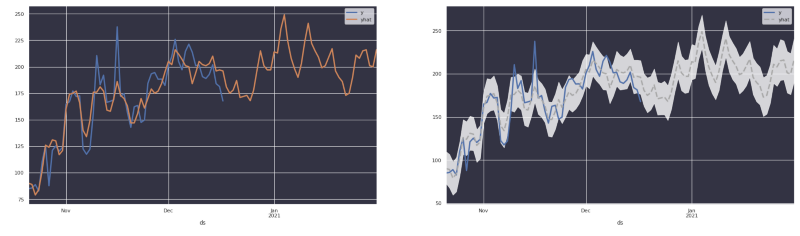 Usare il design per distinguere tra valori reali e stime, visualizzando al contempo l'incertezza!
Usare il design per distinguere tra valori reali e stime, visualizzando al contempo l'incertezza!
Consiglio #6: usa pre-processing e post-processing
Quando inviamo i dati per le previsioni rischiamo di dimenticare che gli algoritmi non conoscono il contesto in cui la serie temporale viene generata.
Nel nostro caso eravamo soliti inviare dati di costo aggregati su base mensile per generare previsioni mensili. Nelle prime settimane di ogni mese l'ultima osservazione era nettamente più bassa, e questo portava Prophet a prevedere un crollo nel trend futuro. Rimuovere i punti dati che sappiamo essere alterati può migliorare drasticamente i risultati. Ricorda che Prophet gestisce bene i valori mancanti: spesso è meglio scartare il rumore che cercare di adattarvisi.
 Dati mensili inviati al servizio di forecasting. Prophet "non sa" che il calo è dovuto a dati mancanti
Dati mensili inviati al servizio di forecasting. Prophet "non sa" che il calo è dovuto a dati mancanti
Tra le altre possibilità di miglioramento c'è l'uso della funzione rolling di Pandas per applicare filtri a finestra mobile sui risultati.
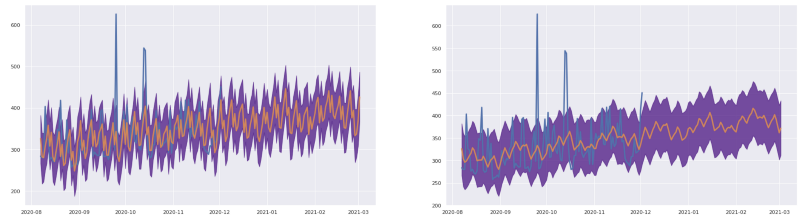 I dati originali sono troppo rumorosi, ma applicando una finestra di media mobile possiamo osservare un trend più regolare, se ha senso dal punto di vista di business
I dati originali sono troppo rumorosi, ma applicando una finestra di media mobile possiamo osservare un trend più regolare, se ha senso dal punto di vista di business
Consiglio #7: velocizza l'inferenza ignorando l'incertezza
Prophet adatta un modello probabilistico ai dati e poi campiona iterativamente la distribuzione per stimare il rumore (e i relativi intervalli di previsione).
Profilando l'esecuzione del mio servizio, ho scoperto che questo processo di campionamento pesa per una porzione piuttosto consistente del tempo di esecuzione totale. Questa iterazione viene ripetuta molte volte, finché non raccoglie campioni sufficienti a stimare il rumore. Se gli intervalli di previsione non ti interessano, puoi impostare il parametro uncertainty_samples a un valore più basso (anche 0) e ridurre in modo significativo il tempo di esecuzione del programma!
 Questa parte del codice, usata per stimare il rumore del modello adattato, è molto onerosa in termini di tempo, ma se non ti serve la stima dell'incertezza puoi tranquillamente saltarla!
Questa parte del codice, usata per stimare il rumore del modello adattato, è molto onerosa in termini di tempo, ma se non ti serve la stima dell'incertezza puoi tranquillamente saltarla!
Naturalmente questo consiglio va in direzione opposta al #5, che ricorda quanto sia importante mostrare l'incertezza. D'altronde lo sviluppo software è sempre una questione di compromessi, no? :)
Per oggi è tutto! Se hai commenti, lasciali pure qui sotto.
Gad Benram è Senior Research Engineer presso l'Office of the CTO di DoiT International. Vuoi lavorare con Gad? Dai un'occhiata alla nostra pagina careers.