
Wer hat eigentlich behauptet, die Zukunft vorherzusagen sei schwierig? Sie brauchen nur einen Propheten (und etwas verlässliche Infrastruktur).
Mein Team und ich haben kürzlich ein System zur Steuerung von Cloud-Ausgaben gebaut, das die Analyse von Cloud-Kosten erleichtert. Wir wollten aber noch einen Schritt weitergehen und unseren Nutzern mit Ein-Klick-Prognosen einen Blick in die Zukunft ermöglichen. Dafür haben wir auf sehr leistungsfähige Forecasting-Tools gesetzt, darunter Facebooks Prophet – und dachten, unsere Erkenntnisse könnten auch für andere hilfreich sein!
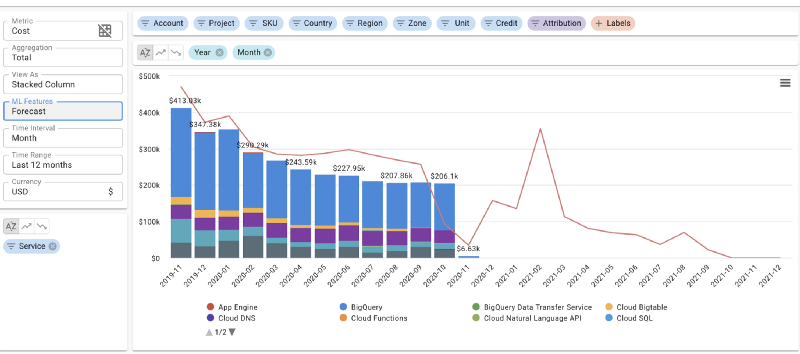
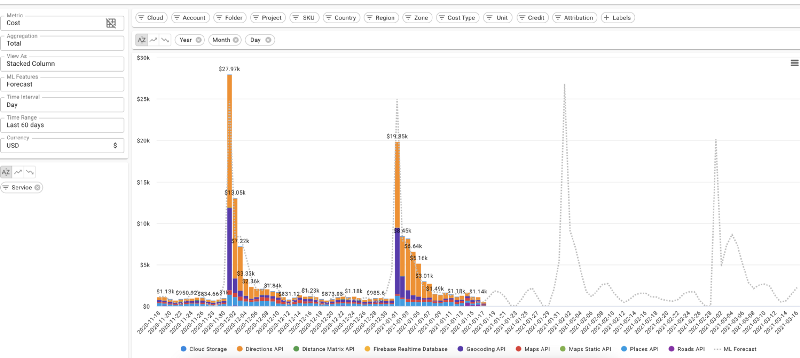 Prognose täglicher Cloud-Kosten in DoiT Cloud Intelligence™
Prognose täglicher Cloud-Kosten in DoiT Cloud Intelligence™
Tipp #1: Lernen Sie Ihren Prophet kennen
Prophet ist eine großartige Library für bestimmte Probleme – bei manchen Aufgaben kann sie aber leicht hinter anderen Tools zurückbleiben. Wofür eignet sie sich? Prophet ist besonders stark darin, Prognosen für eine Zeitreihe allein aus den Daten dieser Reihe zu erzeugen. Weniger geeignet ist sie, wenn Sie weitere Features einbinden oder aus ähnlichen Reihen lernen wollen (etwa wenn Sie mehrere Konten mit ähnlichem Verhalten haben).
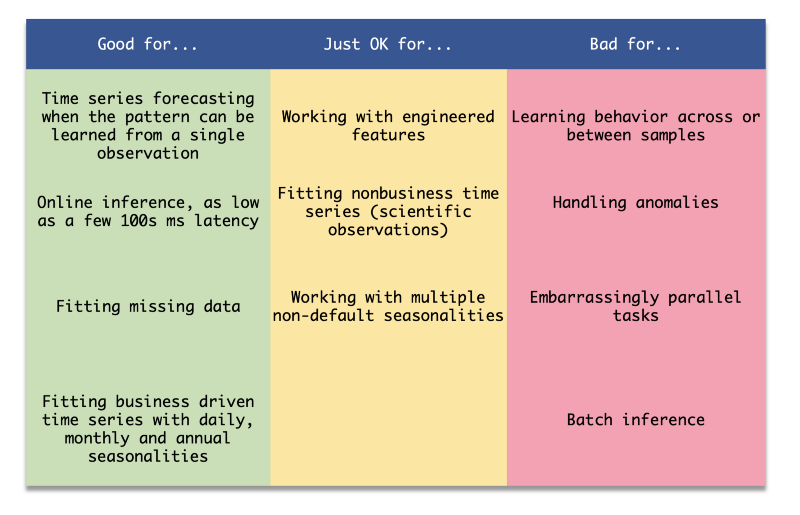 Übersichtstabelle zu Prophet
Übersichtstabelle zu Prophet
Die Arbeit mit Prophet unterscheidet sich von dem, was Sie üblicherweise von Diensten auf Basis neuronaler Netze gewohnt sind. Statt ein serialisiertes, trainiertes Modell vorzuhalten und Vorhersagen in Echtzeit abzurufen, trainieren Sie das Modell und sagen damit pro Aufruf vorher. Aus diesem Grund braucht es mehrere CPU-Kerne (rund 8 Kerne sollten ausreichen), um eine einzige Anfrage zu bedienen.
Eine weitere Eigenschaft der Library: Sie ist darauf ausgelegt, geschäftsbezogene Trends abzubilden (etwa tägliche und monatliche Saisonalitäten). Out of the Box schneidet Prophet bei anderen Arten von Zeitreihen (etwa Funksignalen) unter Umständen weniger gut ab. Stoßen Sie auf ein Problem, für das Prophet nicht optimiert ist, lohnt ein Blick auf NeuralProphet, DeepAR, ARIMA oder andere Algorithmen, Libraries und Cloud-Tools, die auf Zeitreihenprognosen spezialisiert sind.
Tipp #2: Legen Sie Prophet-Subklassen an
Out of the Box liefert Prophet erstaunlich präzise Prognosen. Doch nichts ist umsonst – auch hier nicht. Manche Trends haben eine stärkere Saisonalitätskomponente als andere, manche verlaufen glatter mit weniger Change-Points usw. Prophet unterstützt zwar dieselbe lange Liste an Frequenzen wie die Time Offsets von pandas, Ihre Anwendung muss aber nicht zwingend alle davon abdecken.
Vielleicht möchten Sie nur eine kleine, fest umrissene Auswahl an Frequenzen unterstützen, etwa täglich, wöchentlich und monatlich. In diesem Fall kann es sinnvoll sein, je Frequenz eine Subklasse von Prophet anzulegen und sie pro Klasse unterschiedlich zu konfigurieren:
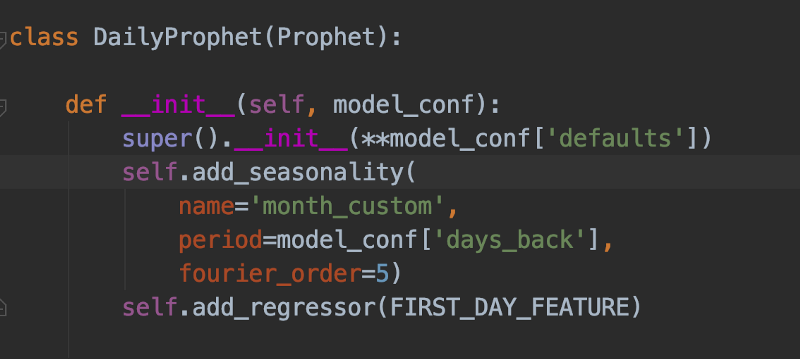 Daily Prophet erbt von Prophet, wird mit eigenen Parametern initialisiert und besitzt eine Regression auf den "ersten Tag des Monats" sowie eine Custom Seasonality über Monatsvergleiche. Prof. Trelawney wäre stolz gewesen …
Daily Prophet erbt von Prophet, wird mit eigenen Parametern initialisiert und besitzt eine Regression auf den "ersten Tag des Monats" sowie eine Custom Seasonality über Monatsvergleiche. Prof. Trelawney wäre stolz gewesen …
Um die optimalen Parameter pro Klasse zu finden, können Sie einen Datensatz aufbauen und darauf einen Hyperparameter-Tuning-Job laufen lassen. Prüfen Sie, ob sich ein Parameterset finden lässt, das andere bei objektiven Metriken wie Mean Squared Error oder Mean Absolute Percentage Error übertrifft.
In unserem Fall enthielten die täglichen Daten wiederkehrende monatliche Abrechnungen (etwa Ihre Support-Rechnung), die jeweils am ersten Tag des Monats auftauchen. Außerdem ist uns aufgefallen, dass die Daten von Monat zu Monat korrelieren, weil Google Cloud und AWS bestimmte Rabattmodelle anwenden. Wir haben die Genauigkeit unserer Prognosen verbessert, indem wir ein eigenes Daily-Prophet-Objekt angelegt, einen Custom Regressor für den Monatsersten ergänzt und das Ganze mit einer Custom Seasonality von 30,5 Tagen ausgestattet haben. Zusätzlich haben wir die super()-Methode dieses Objekts mit eigenen, gezielt für tägliche Prognosen optimierten Hyperparametern initialisiert.
Tipp #3: Geben Sie Prophet genügend CPU und RAM
Der Prophet-Service lässt sich problemlos containerisieren und auf Tools wie Cloud Run von Google Cloud ausliefern. Allerdings ist diese Library, die auf pystan basiert, ausgesprochen ressourcenhungrig. Aus Sicht von Wartbarkeit und Performance war für uns die optimale Lösung, den Service auf Cloud Run für Anthos (GKE) zu deployen.
So konnten wir dem Service starke, compute-optimierte Maschinen zur Verfügung stellen, die die Vorhersagezeit gegenüber dem nativen Cloud Run um 60 % reduziert haben. Da der Service alle Kerne und den gesamten zugewiesenen RAM ausgenutzt hat, haben wir jede Cloud-Run-Instanz so beschränkt, dass sie nur eine Handvoll Anfragen parallel verarbeitet – und dabei die Skalierungsfähigkeit von Cloud Run und GKE genutzt, um schnell hoch- und runterzuskalieren!
 Ein üppiger Node-Pool mit c2-Maschinen, jede mit 8 vCPUs, als Teil der Dev-Umgebung
Ein üppiger Node-Pool mit c2-Maschinen, jede mit 8 vCPUs, als Teil der Dev-Umgebung
Tipp #4: Plotten Sie – und bringen Sie mehr Business-Wissen ein
Manchmal ist es wichtiger, sich die entstehenden Trends anzusehen, als die Ergebnisse anhand eines Test-Sets zu bewerten. Sie können den Mean Squared Error noch so gut optimieren – manchmal spiegelt dieser Wert ein bestimmtes Geschäftsverhalten nicht wider, das Sie schlicht nicht erfasst haben.
In unserem Fall haben wir gelernt, dass Cloud-Ausgaben in der Regel nicht linear wachsen. Sie lassen sich besser als logistische Funktion mit einer Asymptote (Kapazitätsgrenze) beschreiben, die sich aus finanziellen Überlegungen ableitet.
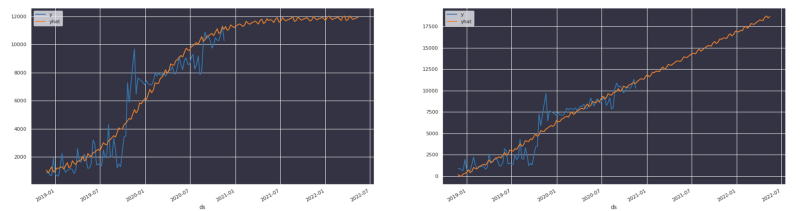 So sehr wir uns wünschen, dass unsere Umsätze so wachsen – wahrscheinlicher ist, dass das Wachstum irgendwann abflacht und auf eine Asymptote zuläuft. Diese Grenze definieren wir mit Domänenwissen.
So sehr wir uns wünschen, dass unsere Umsätze so wachsen – wahrscheinlicher ist, dass das Wachstum irgendwann abflacht und auf eine Asymptote zuläuft. Diese Grenze definieren wir mit Domänenwissen.
Tipp #5: Unsicher? Machen Sie die Unsicherheit sichtbar!
Wir haben festgestellt, dass Nutzer von einer Prognose oft eine sehr geringe Fehlermarge erwarten – häufig geringer, als es von einem Tool zur Zeitreihenprognose realistisch erwartet werden kann.
In den obigen Bildern sehen Sie deutlich: Wenn Sie Prophet einsetzen, liefert die Library eine Schätzung des ursprünglichen Trends und nicht zwangsläufig die tatsächlichen Zahlen. Nutzer sind dann oft irritiert, wenn ihnen eine Prognose präsentiert wird, die dem ursprünglichen Trend stark ähnelt.
Folgendes sollten Sie deshalb in Betracht ziehen:
- Stellen Sie die Prognose als gestrichelte graue Linie dar.
- Ergänzen Sie ein Konfidenzintervall.
- Erwägen Sie, "yhat" (Vorhersagen) wo möglich durch "y" (historische Beobachtungen) zu ersetzen.
Die Breite der Intervalle steuern Sie, indem Sie sie als Parameter im Konstruktor übergeben.
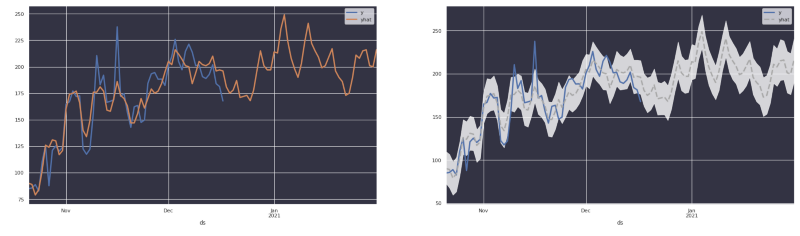 Per Design tatsächliche Werte von Schätzungen unterscheiden – und gleichzeitig die Unsicherheit visualisieren!
Per Design tatsächliche Werte von Schätzungen unterscheiden – und gleichzeitig die Unsicherheit visualisieren!
Tipp #6: Setzen Sie auf Pre- und Post-Processing
Wenn wir Daten zur Vorhersage übergeben, vergessen wir leicht, dass Algorithmen den Kontext, in dem die Zeitreihe entstanden ist, nicht kennen.
In unserem Fall haben wir aggregierte Monatskostendaten geschickt, um daraus monatliche Prognosen zu erzeugen. In den ersten Wochen jedes Monats lag die letzte Beobachtung deutlich niedriger – Prophet hat daraufhin einen scharfen Einbruch im künftigen Trend modelliert. Datenpunkte, von denen wir wissen, dass sie verfälscht sind, zu entfernen, kann die Ergebnisse drastisch verbessern. Denken Sie daran: Prophet kommt gut mit fehlenden Werten zurecht – oft ist es besser, Rauschen zu verwerfen, als es zu fitten!
 Monatsdaten, die an den Forecast-Service gehen. Prophet "weiß nicht", dass der Einbruch durch fehlende Daten entsteht.
Monatsdaten, die an den Forecast-Service gehen. Prophet "weiß nicht", dass der Einbruch durch fehlende Daten entsteht.
Weitere Verbesserungen über die Verarbeitung lassen sich etwa mit der rolling-Funktion von Pandas erzielen, mit der sich Sliding-Window-Filter auf die Ergebnisse anwenden lassen.
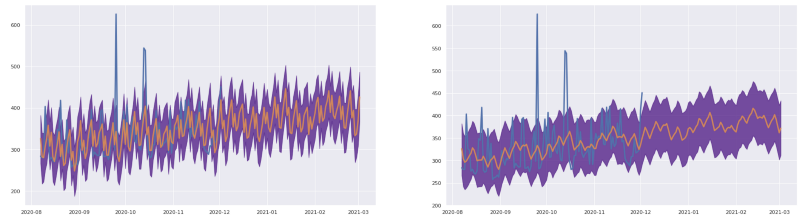 Die Originaldaten sind zu verrauscht – mit einem Rolling-Mean-Fenster sehen wir einen geglätteten Trend, sofern das fachlich sinnvoll ist.
Die Originaldaten sind zu verrauscht – mit einem Rolling-Mean-Fenster sehen wir einen geglätteten Trend, sofern das fachlich sinnvoll ist.
Tipp #7: Beschleunigen Sie Ihre Inferenz, indem Sie auf Unsicherheit verzichten
Prophet passt ein probabilistisches Modell an die Daten an und sampelt anschließend iterativ aus der Verteilung, um das Rauschen (und die zugehörigen Vorhersageintervalle) zu schätzen.
Nach etwas Profiling meines Services habe ich festgestellt, dass dieser Sampling-Prozess für einen erheblichen Teil der gesamten Programmlaufzeit verantwortlich ist. Diese Schleife läuft so lange, bis genügend Samples zur Schätzung des Rauschens vorliegen. Wenn Sie die Vorhersageintervalle nicht benötigen, können Sie den Parameter uncertainty_samples auf einen niedrigeren Wert setzen (sogar auf 0) und so die Laufzeit des Programms deutlich verkürzen!
 Dieser Codeabschnitt, der das Rauschen des gefitteten Modells schätzt, ist sehr zeitaufwendig – wenn Sie die Unsicherheitsschätzung nicht brauchen, überspringen Sie ihn einfach!
Dieser Codeabschnitt, der das Rauschen des gefitteten Modells schätzt, ist sehr zeitaufwendig – wenn Sie die Unsicherheitsschätzung nicht brauchen, überspringen Sie ihn einfach!
Klar, dieser Tipp widerspricht Tipp #5, der ja gerade betont, wie wichtig es ist, Unsicherheit darzustellen. Aber Softwareentwicklung ist eben immer eine Sache von Trade-offs, oder? :)
Das war's! Wenn Sie Anmerkungen haben, hinterlassen Sie sie gerne unten!
Gad Benram ist Senior Research Engineer im Office of the CTO bei DoiT International. Sie möchten mit Gad arbeiten? Schauen Sie auf unserer Karriereseite vorbei.