
¿Quién dijo que predecir el futuro es difícil? Solo necesitas un Prophet (y algo de infraestructura confiable).
Hace poco mi equipo y yo construimos un sistema de control de gasto en la nube que les facilita a los usuarios analizar sus costos. Pero quisimos ir más allá y darles también un vistazo al futuro con pronósticos en un solo clic. Para lograrlo, nos apoyamos en herramientas de pronóstico muy potentes, entre ellas Prophet de Facebook, y nos pareció valioso compartir lo que aprendimos.
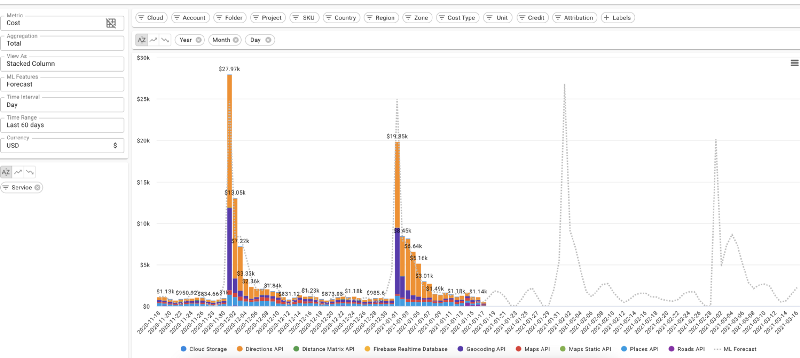 Predicción de costos diarios de nube en DoiT Cloud Intelligence™
Predicción de costos diarios de nube en DoiT Cloud Intelligence™
Tip #1: Conoce a tu Prophet
Prophet es una gran biblioteca para ciertos problemas, pero en algunas tareas puede quedarse corto frente a otras herramientas. ¿En qué brilla? Prophet es muy bueno para generar pronósticos de una serie usando los datos de la propia serie. Rinde menos cuando quieres sumar más features o aprender de series parecidas (por ejemplo, cuando tienes varias cuentas con un comportamiento similar).
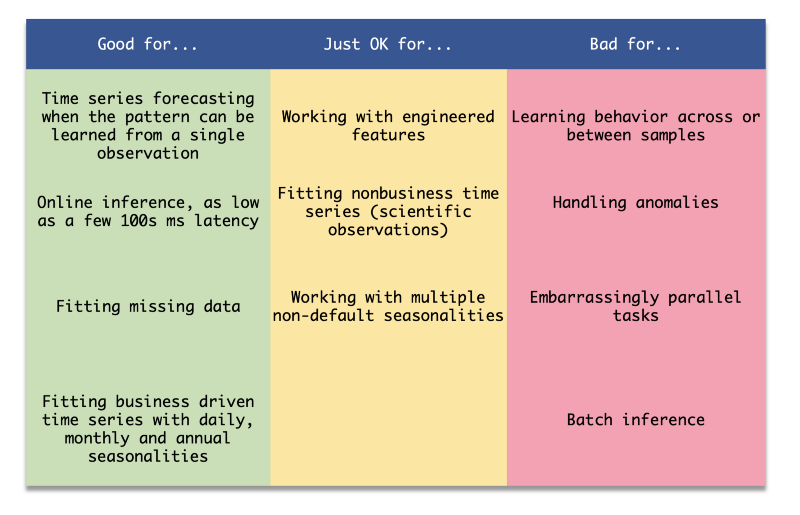 Tabla resumen de Prophet
Tabla resumen de Prophet
Trabajar con Prophet no se parece a lo que sueles hacer con servicios basados en redes neuronales. En lugar de mantener un modelo entrenado serializado e invocar predicciones en tiempo real, en cada llamada se entrena y se predice el modelo. Por eso hacen falta varios núcleos de CPU (con unos 8 suele alcanzar) para atender una sola solicitud.
Otra característica de la biblioteca es que está pensada para ajustarse a tendencias de negocio (como estacionalidades diarias y mensuales); por defecto, Prophet puede no rendir igual de bien con otros tipos de series temporales (como señales de radio). Si tu problema no es de los que Prophet optimiza, vale la pena considerar NeuralProphet, DeepAR, ARIMA, u otros algoritmos, bibliotecas y herramientas cloud especializadas en pronóstico de series temporales.
Tip #2: Crea subclases de Prophet
De fábrica, Prophet puede generar pronósticos increíblemente precisos. Pero nada es gratis, ni siquiera aquí. Algunas tendencias tienen un componente estacional más fuerte que otras, mientras que otras son más suaves y con menos puntos de cambio, etc. Aunque Prophet soporta la misma extensa lista de frecuencias que los time offsets de pandas, tu app no necesariamente tiene que cubrirlas todas.
Tal vez te baste con soportar un conjunto pequeño y finito de frecuencias, como Diaria, Semanal y Mensual. Si es tu caso, te puede convenir crear una subclase de Prophet por frecuencia y configurar de forma distinta para cada una:
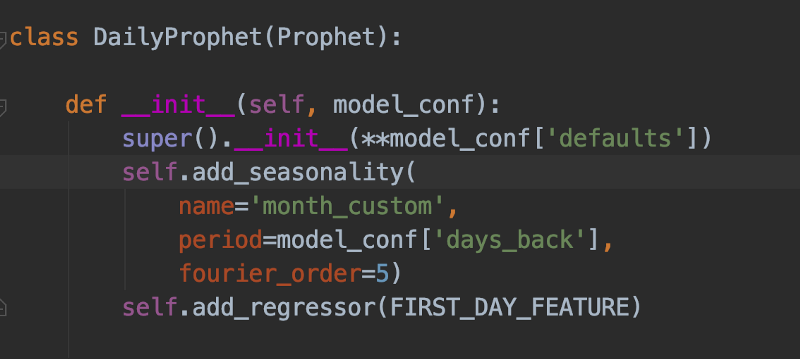 Daily prophet hereda de Prophet, se inicializa con parámetros personalizados, incluye una regresión que se ajusta al "primer día del mes" y una estacionalidad personalizada de mes a mes. La profesora Trelawney estaría orgullosa…
Daily prophet hereda de Prophet, se inicializa con parámetros personalizados, incluye una regresión que se ajusta al "primer día del mes" y una estacionalidad personalizada de mes a mes. La profesora Trelawney estaría orgullosa…
Para encontrar los parámetros óptimos por clase, puedes armar un dataset y correr un job de tuning de hiperparámetros sobre él. A ver si das con un conjunto de parámetros que supere a los demás en métricas objetivas como mean-squared-error o mean-absolute-percentage-error.
En nuestro caso, los datos diarios contenían cobros mensuales recurrentes (como tu factura de soporte) que aparecen el primer día de cada mes. Además, notamos que los datos suelen estar correlacionados de mes a mes por ciertos esquemas de descuento que aplican Google Cloud y AWS. Mejoramos la precisión de las predicciones creando un objeto Daily-Prophet especial, sumando un regresor personalizado para el inicio del día 1 de cada mes y configurándolo con una estacionalidad personalizada de 30.5 días. También inicializamos el método super() de ese objeto con hiperparámetros personalizados, optimizados para predicciones diarias.
Tip #3: Dale a Prophet suficiente CPU y RAM
El servicio de Prophet se puede contenerizar fácilmente y servirlo en herramientas como Cloud Run de Google Cloud. Sin embargo, esta biblioteca, basada en pystan, puede consumir muchos recursos. Encontramos que la solución óptima en términos de facilidad de gestión y desempeño fue desplegar el servicio en Cloud Run sobre Anthos (GKE).
Así pudimos darle al servicio máquinas potentes optimizadas para cómputo, que redujeron el tiempo de predicción en un 60% frente a Cloud Run nativo. Como el servicio aprovechaba todos los núcleos y la RAM que le asignábamos, también limitamos cada instancia de Cloud Run a atender solo unas pocas solicitudes en paralelo, ¡aprovechando la capacidad de Cloud Run y GKE de escalar hacia arriba y hacia abajo rápidamente!
 Un node-pool robusto con máquinas c2, cada una con 8 vCPUs, sirviendo como parte del entorno de desarrollo
Un node-pool robusto con máquinas c2, cada una con 8 vCPUs, sirviendo como parte del entorno de desarrollo
Tip #4: No olvides graficar e incorporar más conocimiento del negocio
A veces ver las tendencias que obtienes pesa más que evaluar tus resultados sobre un set de prueba. Aunque optimices el mean-squared-error, ese número a veces no refleja algún comportamiento de negocio que se te escapó.
En nuestro caso, aprendimos que el gasto en la nube no suele crecer de forma lineal. Se describe mejor como una función logística con una asíntota (límite de capacidad) que surge de consideraciones financieras.
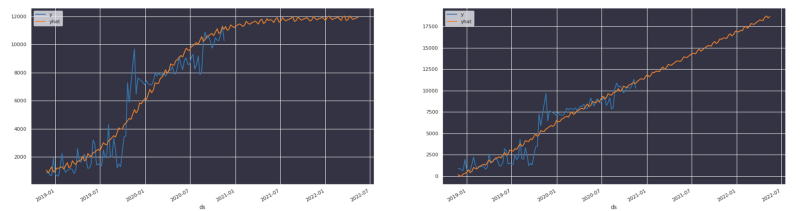 Por más que soñemos con que nuestros ingresos crezcan así, lo más probable es que el crecimiento termine desacelerándose y choque con una asíntota. Usamos conocimiento del dominio para definir ese límite
Por más que soñemos con que nuestros ingresos crezcan así, lo más probable es que el crecimiento termine desacelerándose y choque con una asíntota. Usamos conocimiento del dominio para definir ese límite
Tip #5: ¿No estás seguro? ¡Expresa tu incertidumbre!
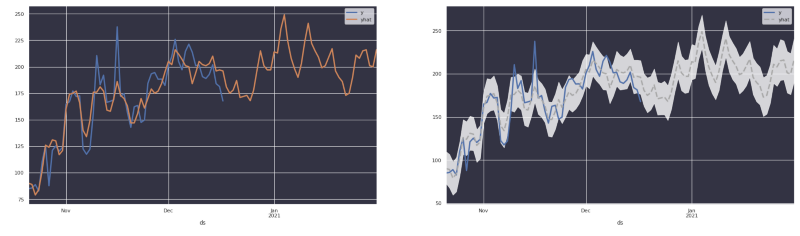
Aprendimos que los usuarios suelen esperar que la predicción tenga un margen de error bajo —muchas veces, más estrecho de lo que se puede esperar de manera realista de una herramienta de pronóstico de series temporales.
En las imágenes anteriores se ve claramente que, al usar Prophet, la biblioteca devuelve una estimación de la tendencia original y no necesariamente los números reales. Y los usuarios se confunden bastante cuando ven un pronóstico tan parecido a la tendencia original.
Por eso, te conviene considerar lo siguiente:
- Mostrar el pronóstico como una línea gris punteada.
- Agregar un intervalo de confianza.
- Reemplazar "yhat" (predicciones) por "y" (observaciones históricas) cuando sea posible.
Puedes controlar el ancho de los intervalos pasándolo como parámetro al constructor.
 Usar el diseño para distinguir entre valores reales y estimaciones, ¡y dejar visible la incertidumbre!
Usar el diseño para distinguir entre valores reales y estimaciones, ¡y dejar visible la incertidumbre!
Tip #6: Usa pre-procesamiento y post-procesamiento
Cuando enviamos datos para predecir, se nos olvida que los algoritmos no conocen el contexto en el que se genera la serie temporal.
En nuestro caso, solíamos enviar datos de costos agregados de forma mensual para generar predicciones mensuales. En las primeras semanas de cada mes, la última observación era bastante más baja, lo que hacía que Prophet ajustara una caída pronunciada en la tendencia futura. Eliminar puntos de datos que sabemos que están corruptos puede mejorar muchísimo los resultados. Recuerda que Prophet maneja bien los valores faltantes; muchas veces es mejor descartar el ruido que ajustarlo.
 Datos mensuales enviados al servicio de pronóstico. Prophet "no sabe" que la caída se debe a datos faltantes
Datos mensuales enviados al servicio de pronóstico. Prophet "no sabe" que la caída se debe a datos faltantes
Otras opciones de mejora vía procesamiento incluyen usar la función rolling de Pandas para aplicar filtros de ventana deslizante sobre los resultados.
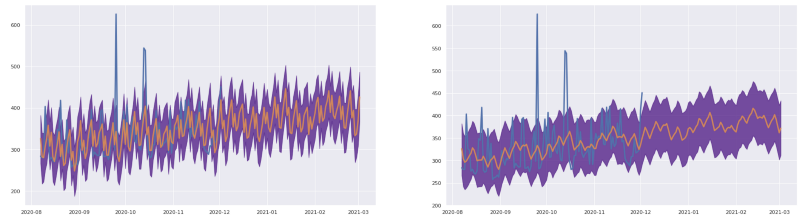 Los datos originales son demasiado ruidosos, pero podemos aplicarles una ventana de media móvil y ver una tendencia más suavizada, si tiene sentido desde la perspectiva del negocio
Los datos originales son demasiado ruidosos, pero podemos aplicarles una ventana de media móvil y ver una tendencia más suavizada, si tiene sentido desde la perspectiva del negocio
Tip #7: Acelera tu inferencia ignorando la incertidumbre
Prophet ajusta un modelo probabilístico a los datos y luego muestrea de forma iterativa la distribución para estimar el ruido (y los intervalos de predicción asociados).
Al hacer profiling de mi servicio, descubrí que ese proceso de muestreo se lleva una porción bastante grande del tiempo total de ejecución. Esa iteración corre muchas veces hasta generar suficientes muestras para estimar el ruido. Si no te interesan los intervalos de predicción, puedes bajar el parámetro uncertainty_samples a un número menor (incluso 0) y ¡reducir muchísimo el tiempo de ejecución del programa!
 Esta parte del código, encargada de estimar el ruido del modelo ajustado, consume mucho tiempo; pero si no necesitas la estimación de incertidumbre, ¡sáltala sin más!
Esta parte del código, encargada de estimar el ruido del modelo ajustado, consume mucho tiempo; pero si no necesitas la estimación de incertidumbre, ¡sáltala sin más!
Claro, este tip contradice al tip #5, que insiste en lo importante que es presentar la incertidumbre. Supongo que el desarrollo de software siempre se trata de trade-offs, ¿no? :)
¡Eso es todo! Si tienes algún comentario, déjalo abajo sin problema.
Gad Benram es Senior Research Engineer en la Office of the CTO de DoiT International. ¿Quieres trabajar con Gad? Visita nuestra página de careers.