
Banias — Kubernetes、Apache Beam、Google BigQueryで構築された高性能分析パイプライン
DoiT Internationalでは、多くのスタートアップを支援しています。各社に共通しているのは、信頼できるデータが事業の成否を左右するという認識です。そして「ユーザー行動を分析するためのパイプラインをどう構築すべきか」というご相談を数多くいただきます。
Jelly ButtonやRoundsなどの企業との取り組みで得た知見を活かし、Kubernetes、Apache Beam、Google BigQueryをベースにした、思想あるサーバーレス・イベント分析パイプラインBaniasを開発しました。
Banias(アラビア語:بانياس الحولة、ヘブライ語:בניאס)は、ギリシャ神話の神Panと結び付けられていた泉の周辺で発展した古代遺跡を指す、アラビア語および現代ヘブライ語の名称です。Baniasの泉が絶えず流れ続けるように、本システムでもユーザーから届くイベントが途切れることなくGoogle BigQueryへ流れ込みます。私たちはコンセプトとして、イベント分析パイプラインのリファレンスアーキテクチャと実装を構築することにしました。コードはそのまま使うことも、設計の参考として活用することもできます。
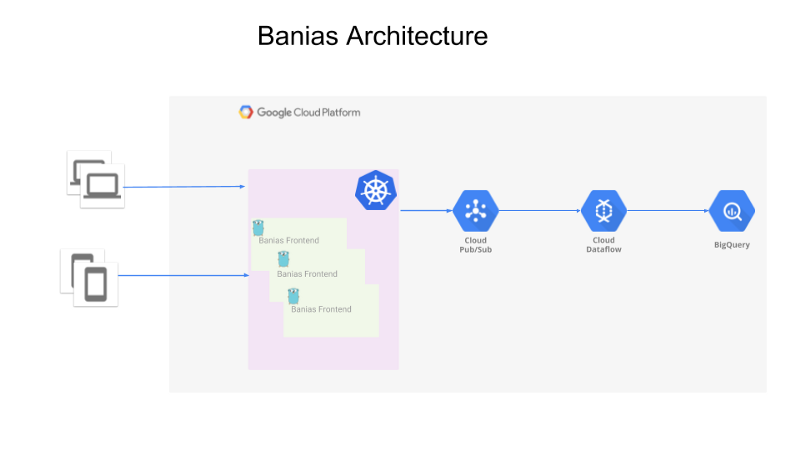
全体のアーキテクチャは次のとおりです。
- 送信元(Webアプリ、モバイルアプリ、バックエンドサーバーなど)からイベントを受け取るAPI
- 受け取ったイベントはGoogle Pub/Subへ送信
- Google Cloud Dataflow上で動作するApache BeamがPub/Subからイベントを読み取り、分析のためにGoogle BigQueryへ送信
 アーキテクチャ概要
アーキテクチャ概要
Events API
フロントエンドはGolangで実装されており、Google Kubernetes Cluster内のサービスとして稼働します。受け取るペイロードの形式は次のとおりです。
https://gist.github.com/avivl/14add746bec42ba786a560d1038666d1
1リクエストにつき、1つ以上のイベントを含められます。
{ "sender_id": "my id", "events": [\ {\ "type": {\ "event_version": "16",\ "event_name": "transaction"\ },\ "payload": {\ "action": "buy",\ "price": 170,\ "date": "1967-03-31"\ }\ },\ {\ "type": {\ "event_version": "64",\ "event_name": "click"\ },\ "payload": {\ "screen": "welcome"\ }\ }\ ]}payloadフィールドは単なるJSONオブジェクトであり、ユーザーが自由にイベント構造を定義できます。アプリは必要最低限のバリデーションを行ったうえで、各イベントにIDを付与し、Golangのバッファ付きチャネルへキューイングします。チャネルを監視するワーカーがイベントを取り出し、Google Pub/Subへ送信します。
目指したのは、コスト効率を保ちながら大量のリクエストをさばけるアプリです。本APIは、Google Kubernetes Engineクラスタ上の2コアノード1台で、毎秒約14,000リクエスト(1リクエストあたり最大5イベント)を処理できます。
実装にあたっては、fasthttp、ffjson、jsonparser、zapといったパフォーマンス重視のライブラリを厳選。さらにワーカープールやsync poolも活用し、サーバーから最大限の性能を引き出しています。
アプリの監視には、OpenCensusを経由してStackdriverとPrometheusへデータをエクスポートしています(詳細はこちらのブログ記事をご覧ください)。Prometheusを使う場合は、こちらのスクリプトでPrometheus Operatorを使ってインストールする方法をおすすめします。
Backend
イベントの処理とBigQueryへの投入にはCloud Dataflowを活用しています。Cloud Dataflowは、ストリーム(リアルタイム)とバッチ(履歴)の両モードを同等の信頼性と表現力で扱える、データの変換・拡充に特化したフルマネージドサービスです。SDKは最新のApache Beam SDK v2.4.0のJavaベース版を採用しています。
Baniasが目指すのは、イベントの進化に伴うスキーマ変更を最小限のコード修正で取り込みつつ、GoogleのBigQueryへ手軽にイベントを送り込めることです。これを実現するため、バックエンドエンジンとしてGoogleのCloud Dataflow上でApache Beamを動かしています。
このコードは、今後構築したい変換グラフのベースとなる雛形です。_BaseMap_や_MapEvents_を拡張すれば、グラフに自由な処理を組み込めます :-)。
BigQueryでは、テーブルへのデータロード時や空のテーブル作成時にスキーマを指定できます。スキーマを指定する際は、各カラムの名前とデータ型が必須で、カラムの説明やモードは任意で指定できます。スキーマとその作成方法の詳細はこちらをご覧ください。
Baniasは、GoogleのBigQueryで使われる標準のスキーマフォーマットに準拠しています。サンプルスキーマはtestフォルダ配下に用意しています。
エラーは_Error_テーブルに記録されます。このテーブルには問題が発生した要素がすべて格納されます(スキーマがないことは「問題」には含めていません…)。エラーテーブルには、イベントの種別、内容、そして該当イベントがエラーテーブルに入る原因となったエラー内容が記録されます。
パイプラインの実行方法:
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketBaniasはそのまま自社のスキーマで使い始めることもできますし、独自のデータパイプラインを構築する際の設計図や出発点として活用することもできます。
ほかの記事もぜひ。ブログを覗いてみるか、AvivのTwitterをフォローしてみてください。