
Banias: la pipeline di analytics ad alte prestazioni costruita su Kubernetes, Apache Beam e Google BigQuery
In DoiT International lavoriamo con moltissime startup. Tutte sanno bene che poter contare su dati affidabili è una condizione essenziale per il successo. E moltissime ci pongono la stessa domanda: come si costruisce una pipeline di analytics per analizzare il comportamento degli utenti?
Sulla scia dell'esperienza maturata con realtà come Jelly Button e Rounds, abbiamo realizzato Banias: una pipeline serverless e opinionated per l'event analytics, basata su Kubernetes, Apache Beam e Google BigQuery.
Banias (in arabo: بانياس الحولة; in ebraico: בניאס) è il nome arabo ed ebraico moderno di un sito antico nato attorno a una sorgente un tempo legata al dio greco Pan. E proprio come scorre il fiume Banias, gli eventi scorrono nel nostro sistema dagli utenti fino a Google BigQuery. L'idea di fondo è proporre un'architettura di riferimento accompagnata da un'implementazione concreta di una pipeline di event analytics. Potete riutilizzare il codice così com'è oppure prenderlo come modello di progettazione.
L'architettura generale è la seguente:
- Un'API che riceve gli eventi dai producer (web app, app mobile o server di backend)
- Gli eventi vengono inoltrati a Google Pub/Sub
- Apache Beam, in esecuzione su Google Cloud Dataflow, legge gli eventi da Pub/Sub e li invia a Google BigQuery per l'analisi.
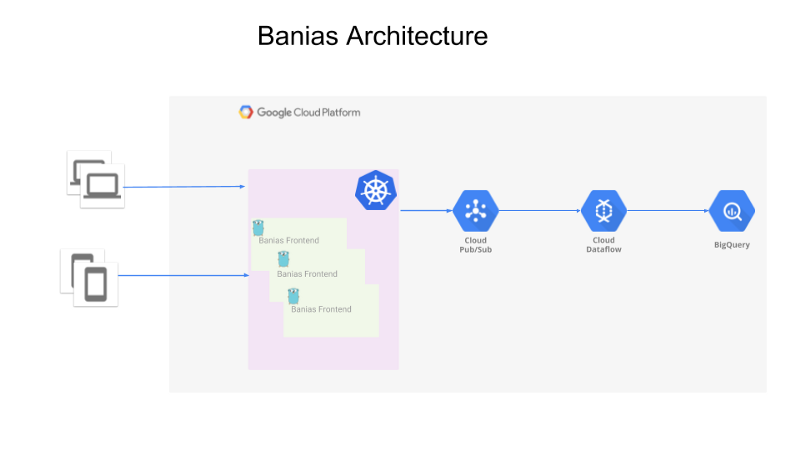 Panoramica dell'architettura
Panoramica dell'architettura
Events API
Il front end è scritto in Golang e gira come servizio all'interno di un cluster Google Kubernetes. Riceve un payload nel seguente formato:
https://gist.github.com/avivl/14add746bec42ba786a560d1038666d1
Ogni richiesta può contenere uno o più eventi:
{ "sender_id": "my id", "events": [\ {\ "type": {\ "event_version": "16",\ "event_name": "transaction"\ },\ "payload": {\ "action": "buy",\ "price": 170,\ "date": "1967-03-31"\ }\ },\ {\ "type": {\ "event_version": "64",\ "event_name": "click"\ },\ "payload": {\ "screen": "welcome"\ }\ }\ ]}Il campo payload è semplicemente un oggetto json, che lascia all'utente la libertà di definire la struttura del proprio evento. L'app esegue una validazione essenziale ma indispensabile della struttura, quindi assegna un id a ciascun evento e lo accoda in un buffered channel di Golang. Alcuni worker restano in ascolto sul canale, prelevano gli eventi e li inoltrano a Google Pub/Sub.
Volevamo costruire un'app capace di gestire un grande volume di richieste senza far esplodere i costi. La nostra API arriva a circa 14.000 richieste al secondo (ogni richiesta può contenere fino a cinque eventi) su un singolo nodo a due core nel cluster Google Kubernetes Engine.
Nell'app abbiamo scelto con cura librerie orientate alle prestazioni come fasthttp, ffjson, jsonparser e zap, affiancate da worker pool e sync pool, così da estrarre il massimo delle prestazioni dai nostri server.
Per monitorare l'app esportiamo i dati su Stackdriver e Prometheus tramite OpenCensus (per approfondire, vi rimandiamo a questo articolo del blog). Se intendete usare Prometheus, vi consigliamo di installarlo con Prometheus Operator tramite questo script.
Backend
Per elaborare gli eventi e inserirli in BigQuery ci affidiamo a Cloud Dataflow, un servizio completamente gestito per trasformare e arricchire i dati sia in modalità stream (in tempo reale) sia batch (dati storici), con pari affidabilità ed espressività. Utilizziamo l'SDK Java della più recente Apache Beam SDK v2.4.0.
L'obiettivo di Banias è offrire un modo semplice per immettere eventi in Google BigQuery, con la possibilità di introdurre nuovi schemi man mano che gli eventi evolvono, riducendo al minimo le modifiche al codice. Per riuscirci usiamo Apache Beam su Google Cloud Dataflow come motore di backend.
Il codice è una base di partenza per qualsiasi grafo di trasformazione vogliate sviluppare in futuro. Potete sempre estendere BaseMap o MapEvents per aggiungere qualche tocco originale al grafo :-).
BigQuery consente di specificare lo schema di una tabella sia quando vi caricate dati sia quando create una tabella vuota. Nel definire lo schema, occorre indicare nome e tipo di dato di ciascuna colonna; descrizione e mode sono invece facoltativi. Per ulteriori informazioni sugli schemi e sulla loro creazione, fate riferimento a questa pagina.
Banias adotta il formato di schema standard di Google BigQuery. Alcuni schemi di esempio sono disponibili nella cartella test.
Gli errori vengono scritti in una tabella Error, dove troverete tutti gli elementi che hanno generato problemi (l'assenza di uno schema non è considerata un problema…). La tabella degli errori contiene il tipo di evento, il contenuto e l'errore che ha portato l'evento a finire lì.
Per eseguire la pipeline:
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketPotete adottare Banias così com'è con i vostri schemi, oppure usarlo come blueprint o punto di partenza per costruire una pipeline di dati su misura.
Volete altri contenuti? Date un'occhiata al nostro blog o seguite Aviv su Twitter.