
Banias – die performante Analytics-Pipeline auf Basis von Kubernetes, Apache Beam und Google BigQuery
Bei DoiT International arbeiten wir mit zahlreichen Startups zusammen. Sie alle wissen: Verlässliche Daten sind der Schlüssel zum Erfolg. Und viele kommen mit derselben Frage auf uns zu – wie baut man eine Analytics-Pipeline, um das Nutzerverhalten auszuwerten?
Aufbauend auf unseren Erfahrungen mit Unternehmen wie Jelly Button und Rounds haben wir Banias entwickelt – eine meinungsstarke, serverlose Event-Analytics-Pipeline auf Basis von Kubernetes, Apache Beam und Google BigQuery.
Banias (arabisch: بانياس الحولة; hebräisch: בניאס) ist der arabische und neuhebräische Name einer antiken Stätte, die rund um eine Quelle entstand, die einst dem griechischen Gott Pan geweiht war. Und so wie der Banias fließt, strömen auch die Events durch unser System – von den Nutzern bis nach Google BigQuery. Konzeptionell wollten wir eine Referenzarchitektur samt konkreter Implementierung einer Event-Analytics-Pipeline schaffen. Sie können den Code direkt einsetzen oder als Designvorlage nutzen.
Die Architektur sieht im Groben so aus:
- Eine API empfängt die Events von den Producern (Web-Apps, Mobile-Apps oder Backend-Server)
- Die Events werden an Google Pub/Sub gesendet
- Apache Beam läuft auf Google Cloud Dataflow, liest die Events aus Pub/Sub und schickt sie zur Auswertung an Google BigQuery.
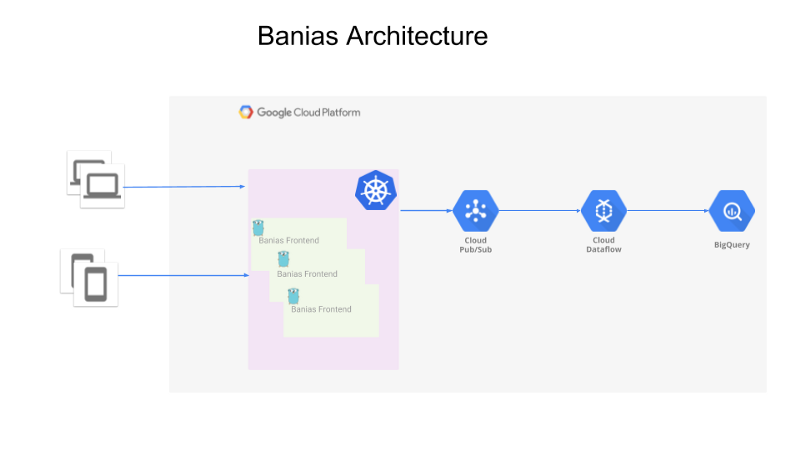 Architektur im Überblick
Architektur im Überblick
Events-API
Das Frontend ist in Golang geschrieben und läuft als Service in einem Google Kubernetes Cluster. Es nimmt einen Payload in folgendem Format entgegen:
https://gist.github.com/avivl/14add746bec42ba786a560d1038666d1
Jeder Request kann ein oder mehrere Events enthalten:
{ "sender_id": "my id", "events": [\ {\ "type": {\ "event_version": "16",\ "event_name": "transaction"\ },\ "payload": {\ "action": "buy",\ "price": 170,\ "date": "1967-03-31"\ }\ },\ {\ "type": {\ "event_version": "64",\ "event_name": "click"\ },\ "payload": {\ "screen": "welcome"\ }\ }\ ]}Das Payload-Feld ist ein einfaches JSON-Objekt – damit kann jeder seine eigene Event-Struktur definieren. Die App nimmt eine grundlegende, aber notwendige Validierung der Struktur vor, versieht jedes Event mit einer ID und legt es in einem gepufferten Channel von Golang ab. Worker lauschen auf diesem Channel, holen die Events ab und reichen sie an Google Pub/Sub weiter.
Unser Ziel war eine App, die hohe Request-Volumen kosteneffizient verarbeitet. Die API schafft rund 14.000 Requests pro Sekunde (mit bis zu fünf Events pro Request) – und das auf einer einzelnen Node mit zwei Cores im Google-Kubernetes-Engine-Cluster.
In der App setzen wir gezielt auf performance-orientierte Bibliotheken wie fasthttp, ffjson, jsonparser und zap, dazu Worker-Pools und sync pool – so holen wir aus unseren Servern das Maximum heraus.
Fürs Monitoring exportieren wir die Daten über OpenCensus nach Stackdriver und Prometheus (mehr dazu in diesem Blogbeitrag). Wer Prometheus einsetzen möchte, dem empfehlen wir die Installation per Prometheus Operator mit diesem Skript.
Backend
Um die Events zu verarbeiten und in BigQuery zu schreiben, setzen wir auf Cloud Dataflow. Cloud Dataflow ist ein vollständig verwalteter Service zum Transformieren und Anreichern von Daten – im Stream (Echtzeit) ebenso wie im Batch (historisch), mit derselben Zuverlässigkeit und Ausdrucksstärke. Wir nutzen das Java-basierte SDK aus dem aktuellen Apache Beam SDK v2.4.0.
Banias soll einen einfachen Weg bieten, Events in Googles BigQuery aufzunehmen – und dabei mit minimalen Codeänderungen neue Schemas zu unterstützen, wenn sich Events weiterentwickeln. Dafür setzen wir Apache Beam auf Googles Cloud Dataflow als Backend-Engine ein.
Der Code dient als Grundlage für jeden Transformations-Graph, den Sie künftig bauen möchten. BaseMap oder MapEvents lassen sich jederzeit erweitern, um eigene kreative Bausteine in den Graph zu integrieren :-).
BigQuery erlaubt es, das Schema einer Tabelle beim Laden von Daten oder beim Anlegen einer leeren Tabelle festzulegen. Dabei müssen Sie für jede Spalte Name und Datentyp angeben; Beschreibung und Mode sind optional. Mehr Informationen zu Schemas und deren Erstellung finden Sie hier.
Banias nutzt das Standard-Schema-Format von Googles BigQuery. Beispiel-Schemas finden Sie im Test-Ordner.
Fehler landen in einer Error-Tabelle. Dort sammeln sich alle Elemente, bei denen es Probleme gab (ein fehlendes Schema zählt übrigens nicht dazu …). Die Error-Tabelle enthält Event-Typ, Inhalt sowie den Fehler, der zum Eintrag geführt hat.
Pipeline starten:
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketSie können Banias direkt mit Ihren eigenen Schemas einsetzen – oder als Blueprint und Ausgangspunkt für eine maßgeschneiderte Datenpipeline nutzen.
Lust auf mehr? Schauen Sie in unseren Blog oder folgen Sie Aviv auf Twitter.