
Te presentamos Banias: un pipeline de analítica de alto rendimiento construido sobre Kubernetes, Apache Beam y Google BigQuery
En DoiT International trabajamos con varias startups, y todas tienen claro que contar con datos confiables es clave para su éxito. Muchas se acercan con la misma duda: cómo armar un pipeline de analítica para entender el comportamiento de los usuarios.
Con base en nuestra experiencia previa con compañías como Jelly Button y Rounds, creamos Banias: un pipeline serverless y opinionated de analítica de eventos basado en Kubernetes, Apache Beam y Google BigQuery.
Banias (en árabe: بانياس الحولة; en hebreo: בניאס) es el nombre, en árabe y hebreo moderno, de un sitio antiguo que se desarrolló en torno a un manantial que en su momento se asoció al dios griego Pan. Y al igual que el caudal del Banias, los eventos fluyen por nuestro sistema desde los usuarios hasta Google BigQuery. Como concepto, decidimos construir una arquitectura de referencia y una implementación real de un pipeline de analítica de eventos. Puedes tomar el código tal cual y usarlo, o tomarlo como referencia de diseño.
La arquitectura general es la siguiente:
- Una API que recibe los eventos de los productores (pueden ser apps web, apps móviles o servidores backend)
- Los eventos se envían a Google Pub/Sub
- Apache Beam, ejecutándose en Google Cloud Dataflow, lee los eventos desde Pub/Sub y los envía a Google BigQuery para su análisis.
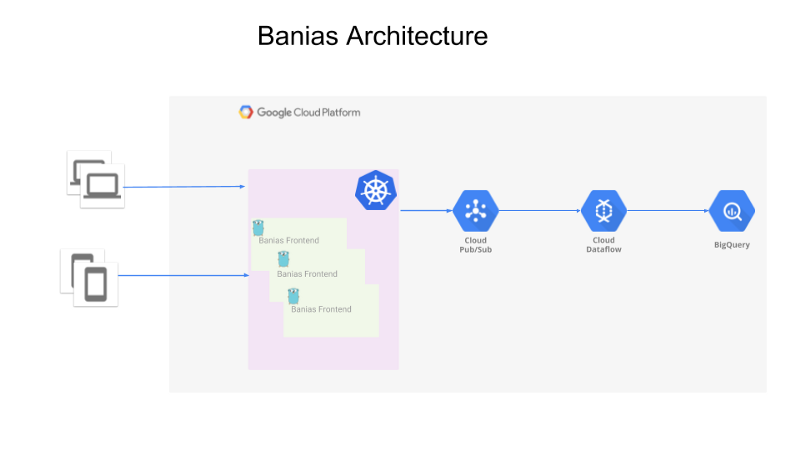 Visión general de la arquitectura
Visión general de la arquitectura
Events API
El front-end está escrito en Golang y se ejecuta como un servicio dentro de un Google Kubernetes Cluster. Recibe un payload con el siguiente formato:
https://gist.github.com/avivl/14add746bec42ba786a560d1038666d1
Cada solicitud puede contener uno o varios eventos:
{ "sender_id": "my id", "events": [\ {\ "type": {\ "event_version": "16",\ "event_name": "transaction"\ },\ "payload": {\ "action": "buy",\ "price": 170,\ "date": "1967-03-31"\ }\ },\ {\ "type": {\ "event_version": "64",\ "event_name": "click"\ },\ "payload": {\ "screen": "welcome"\ }\ }\ ]}El campo payload es simplemente un objeto JSON que le permite al usuario definir la estructura de su evento. La aplicación hace una validación básica pero necesaria de la estructura; luego le agrega un id a cada evento y lo encola en un buffered channel de Golang. Hay workers que escuchan ese canal, desencolan los eventos y los envían a Google Pub/Sub.
Quisimos crear una aplicación capaz de manejar un gran volumen de solicitudes de manera costo-eficiente. Nuestra API atiende cerca de 14.000 solicitudes por segundo (cada una puede contener hasta cinco eventos) ejecutándose en un único nodo de dos cores en el clúster de Google Kubernetes Engine.
En la aplicación elegimos con cuidado librerías orientadas al rendimiento, como fasthttp, ffjson, jsonparser y zap, además de pools de workers y sync pool, para sacarle el máximo rendimiento a nuestros servidores.
Para monitorear la aplicación exportamos datos a Stackdriver y Prometheus mediante OpenCensus (puedes leer más al respecto en este artículo del blog). Si quieres usar Prometheus, te recomendamos instalarlo con Prometheus Operator usando este script.
Backend
Para procesar los eventos e insertarlos en BigQuery utilizamos Cloud Dataflow, un servicio totalmente administrado para transformar y enriquecer datos en modo stream (tiempo real) y batch (histórico), con la misma confiabilidad y expresividad. Usamos el SDK basado en Java de la última versión del SDK de Apache Beam, la v2.4.0.
Banias busca ofrecer una forma sencilla de ingerir eventos en BigQuery de Google, con la posibilidad de incorporar nuevos esquemas a medida que los eventos evolucionan, con cambios mínimos de código. Para lograrlo, usamos Apache Beam sobre Cloud Dataflow como motor de backend.
El código sirve de base para cualquier grafo de transformación que quieras crear más adelante. Siempre puedes extender BaseMap o MapEvents para sumarle cosas más interesantes al grafo :-).
BigQuery te permite especificar el esquema de una tabla al cargar datos en ella, así como al crear una tabla vacía. Al especificar el esquema, debes indicar el nombre y el tipo de dato de cada columna. De manera opcional puedes proporcionar también la descripción y el modo de cada columna. Encuentra más información sobre esquemas y su creación aquí.
Banias utiliza el formato de esquema estándar de BigQuery. Encontrarás esquemas de ejemplo en la carpeta de tests.
Los errores se escriben en una tabla Error. Allí encontrarás todos los elementos que tuvieron problemas (no tener un esquema no se considera un problema…). La tabla de errores contiene el tipo de evento, el contenido y el error que llevó a ese evento a parar allí.
Para ejecutar el pipeline:
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketPuedes empezar a usar Banias tal cual con tus propios esquemas, o tomarlo como blueprint o punto de partida para armar tu propio pipeline de datos a la medida.
¿Quieres más contenido como este? Visita nuestro blog o sigue a Aviv en Twitter.