
Découvrez Banias — un pipeline analytique haute performance bâti sur Kubernetes, Apache Beam et Google BigQuery
Chez DoiT International, nous accompagnons de nombreuses startups. Toutes savent qu'une donnée fiable est essentielle à leur réussite. Beaucoup d'entre elles nous sollicitent pour savoir comment construire un pipeline analytique permettant d'analyser le comportement des utilisateurs.
Forts de notre expérience auprès d'entreprises comme Jelly Button et Rounds, nous avons conçu Banias — un pipeline serverless d'analyse d'événements, articulé autour de Kubernetes, Apache Beam et Google BigQuery.
Banias (en arabe : بانياس الحولة ; en hébreu : בניאס) est le nom arabe et hébreu moderne d'un site antique développé autour d'une source autrefois associée au dieu grec Pan. À l'image du flot du Banias, les événements s'écoulent dans notre système, des utilisateurs jusqu'à Google BigQuery. Nous avons choisi d'élaborer une architecture de référence et une implémentation concrète d'un pipeline analytique d'événements. Vous pouvez utiliser le code tel quel ou vous en inspirer comme référence de conception.
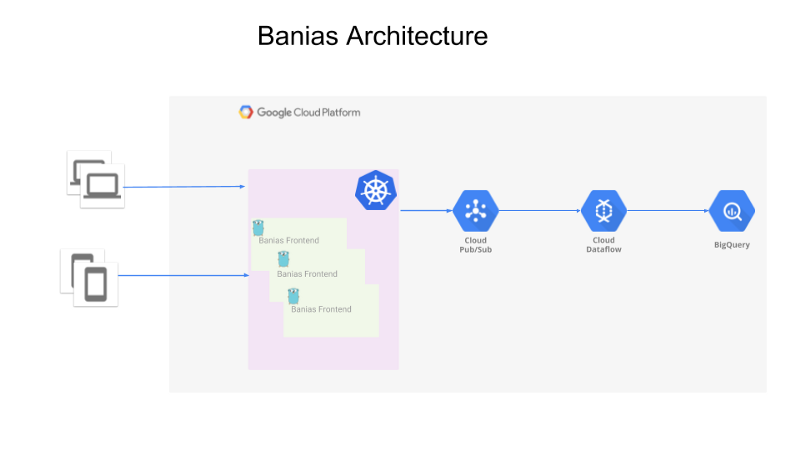
L'architecture générale se présente ainsi :
- Une API qui reçoit les événements émis par les producteurs (applications web, applications mobiles ou serveurs backend)
- Les événements sont envoyés vers Google Pub/Sub
- Apache Beam, exécuté sur Google Cloud Dataflow, lit les événements depuis Pub/Sub et les transmet à Google BigQuery pour analyse.
 Vue d'ensemble de l'architecture
Vue d'ensemble de l'architecture
Events API
Le front-end est écrit en Golang et tourne comme un service au sein d'un cluster Google Kubernetes. Il reçoit une charge utile au format suivant :
https://gist.github.com/avivl/14add746bec42ba786a560d1038666d1
Chaque requête peut contenir un ou plusieurs événements :
{ "sender_id": "my id", "events": [\ {\ "type": {\ "event_version": "16",\ "event_name": "transaction"\ },\ "payload": {\ "action": "buy",\ "price": 170,\ "date": "1967-03-31"\ }\ },\ {\ "type": {\ "event_version": "64",\ "event_name": "click"\ },\ "payload": {\ "screen": "welcome"\ }\ }\ ]}Le champ payload est tout simplement un objet JSON qui laisse à l'utilisateur le soin de définir la structure de ses événements. L'application effectue une validation basique mais indispensable de la structure ; elle attribue ensuite un identifiant à chaque événement et le place dans un canal Golang à mémoire tampon. Des workers à l'écoute du canal récupèrent les événements et les transmettent à Google Pub/Sub.
Notre objectif était de créer une application capable d'absorber un fort volume de requêtes à moindre coût. Notre API gère environ 14 000 requêtes par seconde (chaque requête pouvant contenir jusqu'à cinq événements) sur un unique nœud bi-cœur du cluster Google Kubernetes Engine.
Côté code, nous avons soigneusement retenu des bibliothèques taillées pour la performance : fasthttp, ffjson, jsonparser et zap, en tirant aussi parti de pools de workers et de sync pool pour exploiter au mieux nos serveurs.
Pour superviser l'application, nous exportons les données vers Stackdriver et Prometheus via OpenCensus (plus de détails dans cet article de blog). Pour Prometheus, nous recommandons l'installation via Prometheus Operator à l'aide de ce script.
Backend
Pour traiter les événements et les insérer dans BigQuery, nous nous appuyons sur Cloud Dataflow. Cloud Dataflow est un service entièrement managé qui transforme et enrichit les données en mode stream (temps réel) ou batch (historique), avec la même fiabilité et la même expressivité dans les deux cas. Nous utilisons le SDK Java issu de la dernière version d'Apache Beam, la v2.4.0.
Banias a pour ambition de simplifier l'ingestion d'événements dans Google BigQuery, tout en permettant l'arrivée de nouveaux schémas au fil de l'évolution des événements, avec un minimum de modifications de code. Pour cela, nous nous appuyons sur Apache Beam, exécuté sur Google Cloud Dataflow, comme moteur backend.
Le code sert de base à n'importe quel graphe de transformation que vous voudrez créer par la suite. Vous pouvez à tout moment étendre BaseMap ou MapEvents pour intégrer vos propres traitements dans le graphe :-).
BigQuery vous permet de spécifier le schéma d'une table lorsque vous y chargez des données ou lorsque vous créez une table vide. Lors de la spécification d'un schéma, vous devez fournir le nom et le type de données de chaque colonne. Vous pouvez également préciser, en option, la description et le mode d'une colonne. Plus d'informations sur les schémas et leur création ici.
Banias s'appuie sur le format de schéma standard de Google BigQuery. Des exemples de schémas sont disponibles dans le dossier de tests.
Les erreurs sont consignées dans une table Error. Vous y retrouverez tous les éléments ayant rencontré un problème (l'absence de schéma n'en étant pas un…). Cette table contient le type d'événement, son contenu, ainsi que l'erreur ayant conduit à son enregistrement.
Pour lancer le pipeline :
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketVous pouvez utiliser Banias tel quel avec vos propres schémas, ou vous en servir comme modèle ou point de départ pour construire votre propre pipeline de données sur mesure.
Envie d'en lire davantage ? Rendez-vous sur notre blog, ou suivez Aviv sur Twitter.