
Conheça o Banias — pipeline de analytics de alta performance construído sobre Kubernetes, Apache Beam e Google BigQuery
Aqui na DoiT International, trabalhamos com várias startups. Todas sabem que ter dados confiáveis é fundamental para o sucesso. E muitas chegam até nós com a mesma pergunta: como montar um pipeline de analytics para entender o comportamento dos usuários?
Com base na nossa experiência com empresas como Jelly Button e Rounds, criamos o Banias — um pipeline serverless e opinativo de analytics de eventos baseado em Kubernetes, Apache Beam e Google BigQuery.
Banias (em árabe: بانياس الحولة; em hebraico: בניאס) é o nome árabe e hebraico moderno de um sítio antigo que se desenvolveu em torno de uma nascente outrora associada ao deus grego Pã. E, assim como as águas do Banias correm, os eventos correm dos usuários até o Google BigQuery dentro do nosso sistema. Como conceito, decidimos construir uma arquitetura de referência e uma implementação real de um pipeline de analytics de eventos. Você pode pegar o código e usá-lo como está ou aproveitá-lo como referência de design.
A arquitetura geral é a seguinte:
- API que recebe os eventos dos produtores (que podem ser apps web, apps mobile ou servidores de backend)
- Os eventos são enviados ao Google Pub/Sub
- O Apache Beam, rodando no Google Cloud Dataflow, lê os eventos do Pub/Sub e os envia ao Google BigQuery para análise.
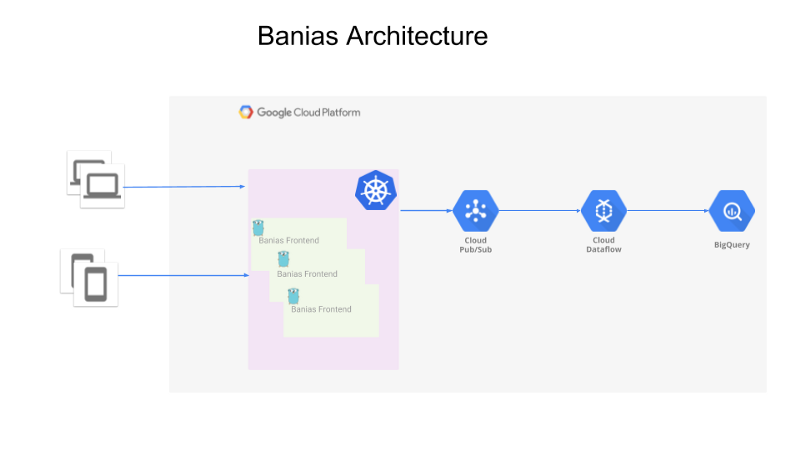 Visão geral da arquitetura
Visão geral da arquitetura
API de Eventos
O front-end é escrito em Golang e roda como um serviço dentro de um Google Kubernetes Cluster. Ele recebe um payload no seguinte formato:
https://gist.github.com/avivl/14add746bec42ba786a560d1038666d1
Cada requisição pode conter um ou mais eventos:
{ "sender_id": "my id", "events": [\ {\ "type": {\ "event_version": "16",\ "event_name": "transaction"\ },\ "payload": {\ "action": "buy",\ "price": 170,\ "date": "1967-03-31"\ }\ },\ {\ "type": {\ "event_version": "64",\ "event_name": "click"\ },\ "payload": {\ "screen": "welcome"\ }\ }\ ]}O campo payload é apenas um objeto JSON, o que permite ao usuário definir a estrutura do próprio evento. O app faz uma validação básica, mas necessária, dessa estrutura; depois, adiciona o id a cada evento e o coloca em um buffered channel do Golang. Há workers escutando esse channel, retirando os eventos da fila e enviando-os ao Google Pub/Sub.
Queríamos criar um app capaz de lidar com um grande volume de requisições de forma econômica. Nossa API consegue processar cerca de 14.000 requisições por segundo (cada requisição pode conter até cinco eventos), rodando em um único nó de dois núcleos no cluster do Google Kubernetes Engine.
No app, escolhemos a dedo bibliotecas focadas em performance, como fasthttp, ffjson, jsonparser e zap, além de usar pools de workers e sync pool para extrair o máximo de performance dos nossos servidores.
Para monitorar o app, exportamos dados para o Stackdriver e o Prometheus via OpenCensus (você pode ler mais a respeito neste post do blog). Se quiser usar o Prometheus, recomendamos instalá-lo com o Prometheus Operator usando este script.
Backend
Para processar os eventos e inseri-los no BigQuery, usamos o Cloud Dataflow. O Cloud Dataflow é um serviço totalmente gerenciado para transformar e enriquecer dados nos modos stream (tempo real) e batch (histórico), com a mesma confiabilidade e expressividade. Usamos o SDK em Java da versão mais recente do Apache Beam SDK v2.4.0.
O Banias tem como objetivo oferecer uma forma simples de ingerir eventos no BigQuery do Google, permitindo criar novos schemas à medida que os eventos evoluem, com o mínimo de mudanças no código. Para isso, usamos o Apache Beam sobre o Google Cloud Dataflow como motor de backend.
O código serve como base para qualquer grafo de transformação que você queira criar no futuro. Você sempre pode estender o BaseMap ou o MapEvents para incluir coisas mais sofisticadas no grafo :-).
O BigQuery permite definir o schema de uma tabela ao carregar dados nela ou ao criar uma tabela vazia. Ao definir o schema, é preciso informar o nome e o tipo de dado de cada coluna. Opcionalmente, você pode informar a descrição e o modo da coluna. Mais informações sobre schemas e como criá-los estão disponíveis aqui.
O Banias utiliza o formato padrão de schema do BigQuery do Google. Você encontra exemplos de schemas na pasta de testes.
Os erros são gravados em uma tabela Error. Nessa tabela, você encontra todos os elementos que apresentaram problemas (não ter um schema não é um problema…). A tabela de erros contém o tipo do evento, o conteúdo e o erro que levou esse evento para a tabela de erros.
Executando o pipeline:
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketVocê pode começar a usar o Banias como ele é, com seus próprios schemas, ou aproveitá-lo como blueprint ou ponto de partida para montar seu próprio pipeline de dados personalizado.
Quer ler mais histórias? Confira nosso blog ou siga o Aviv no Twitter.