これは、何十年もの間、解決策のないまま放置されてきたよくある光景です。多くのデータエンジニア、ビジネスアナリスト、そしてデータドリブンな経営層には、思い当たる節があるのではないでしょうか。

データに関わる仕事に就く以上、混乱は避けて通れません
あなたの組織には複数のチーム/グループ/部門があり、それぞれが独自のデータチームを抱え、自分たちのデータセットを処理・保管し、レポートを作成しています。グループ間のやり取りはごくわずか。チームをまたいでデータにアクセスする必要が生じても、データを管理するエンジニアは必要に応じてアクセス権を付与する程度で、依頼者が適切に — あるいは少なくとも管理元チームのクエリと整合する形で — データを照会しているかをコードレビューで確認することはほとんどありません。SQLでは単純なアイデアの表現すら難しい場合があり、組織が大きくなり問いが複雑になるにつれて、他チームのクエリを検証する作業はチーム横断のデータ処理コードレビューにおける大きな時間的ボトルネックとなっていきます。
こうした連携不足の結果、意思決定や資料作成のためにデータやチャートをまとめる経営層は、ふと気づくのです。同じ生データを基にしているにもかかわらず、似たテーマでグループごとに作成されたチャートを並べると、数字が大きく食い違っていることに。そして、あるグループの結論が、別のグループの結論と矛盾していることに。
経営層がエンジニアリングチームにこの不整合の解決策を求めても、得られる答えは限られています。理由としては次のような点が挙げられます。
- グループの規模に対して問題があまりにも大きいこと。1つのグループから何百ものクエリが生まれ、そのそれぞれに他グループからの検証や修正が必要になる可能性があります。チーム横断でデータパイプラインのコードレビューに割ける人手も時間も、そもそも足りていません。
- あるグループのクエリの基盤となっているデータセットが、他のグループにとっては関連性が薄く、検証作業のためにわざわざ学ぶ価値が見出しにくいこと。1つのクエリは複雑で、何百行ものコードを含み、レビュー担当者がコードレビュー以外の場面では理解する必要のないデータセットへのジョインを伴うこともあります。そうしたSQLを読み解くのは、元の開発者以外にとっては膨大な時間を要する作業です。
こうした障害を踏まえ、経営層はクエリ専任のデータアナリストを雇い、信頼できるレポートの作成を委ねるという選択を取るかもしれません。しかしこの方法は、本質的な問題を回避しているにすぎません。同じ生データから類似または関連する問いを投げかけても、グループによって異なる結果が導き出される — この不整合は、組織内のグループが同じ生データを参照していても、データドリブンな意思決定にばらつきを生み出します。さらに、この経営層付きアナリストはデータセットを得るために複数のグループとやり取りせざるを得ないため、グループ間のデータ処理の食い違いをかえって温存してしまう恐れがあります。

誰もが一度は耳にしたことのある格言です
データドリブンな世界において、意思決定を支えるデータを自信を持って信頼できることは_すべて_です。機械学習の世界には、こんな言葉があります。
Garbage (data) in, garbage (predictions) out.(ゴミを入れれば、ゴミしか出てこない)
すべての生データソースを最先端のデータウェアハウス — BigQuery、Snowflake、Redshiftなど — に接続し、必要に応じてアクセス権を付与するだけでは、全社レベルでの一貫したデータ処理、チーム横断の連携不足、そして部門をまたいだ結果の信頼性という根本問題は解決できません。
従来の縦割り型でデータウェアハウスと分析に取り組むと、あるチームのクエリやデータソースを他チームがそのまま再利用できる場面はほとんどありません。サイロ化したレポート生成はやがて固定化し、各グループは結局、自分たちのデータチームが出した結果しか信用しなくなります。経営層は、組織全体を一貫した視点で見渡せないまま取り残されてしまうのです。

仕事を格段に楽にしてくれるクエリ言語、Malloyの公式ロゴ
そこで登場するのがMalloyです。Looker / LookMLの元創業者・開発者たちが、現在Google内で開発を進めている分析向け言語です。
SQLの限界を超えるべく設計されたMalloy — SQLが世に出たのは1979年、データウェアハウスがまだ存在しない44年も前のことです — は、皮肉なことに本質的にはSQLコンパイラですが、それをはるかに超える存在です。エンジニアリングチームに職人芸的な手書きSQLを依頼するのではなく、MalloyによるSQL生成を前提にデータ基盤を構築することには、いくつもの大きな利点があります。その利点に踏み込む前に、まずはMalloyチーム自身に「なぜSQLの代替が必要なのか」を語ってもらいましょう。
LookerおよびMalloy共同創業者、Ben Porterfield氏より
SQLは、あらゆるクエリを表現できる強力な言語ですが、弱点も抱えています。
すべてを表現できるが、何ひとつ再利用できない
単純なアイデアほど表現が複雑になる
言語が冗長で、気の利いたデフォルトを欠いている
MalloyはSQLユーザーがすぐに理解でき、はるかに使いやすく学びやすい言語です [1]
[1] https://malloydata.github.io/documentation/about/features.html
Malloyプロダクトマネージャー、Carlin Eng氏より
言語は思考の道具です。言語の構文を改善することは、私たちが何を想像し、何を表現できるかに深く関わってきます。SQLが生まれたのはデータウェアハウスが存在しなかった1970年代であり、今日のユースケースを念頭に設計されているはずもありません。
これに対しMalloyは、複雑なデータセットの分析を目的に専用設計された言語です。
これらを踏まえると、SQLの代わりにMalloyで開発することで、次のような利点が得られます。
- もっとも複雑なクエリでさえ、シンプルかつ簡潔に書ける構文。決まり文句のSQLを延々と書き連ねたり、一時テーブルを多用しないと厄介なデータポイントを効率的に集められない、そんな日々はもう終わりです。言語のシンプルさは、次の点を大きく高めます。
- 協働での開発
- 開発スピード
- 出力結果の信頼性
2. モジュール化された再利用可能なコードベース。たとえば次のようなことが可能です。
- 複雑なデータソースを定義し、それを別のソースやクエリの土台として利用できる。複雑なソースを、よりシンプルな親子関係のデータソースに分割することで、複雑性を抑えられます。
- 処理のパイプライン化。あるクエリの出力を、別のクエリの入力として渡せます。
3. ダッシュボード性能に最適化されたSQL生成
- SQLコンパイラは高度に最適化されており、私が比較したかぎり、複雑な手書きクエリのいずれをも凌駕する性能を発揮します。これは重要なポイントです。なぜなら、時は文字どおりお金だからです。BigQuery Editions、Snowflake、サーバーレスRedshiftの料金体系を一度ご覧になってみてください。
4. (近日提供予定)Malloyのソースやクエリの更新後に、テーブル/ビューを自動で再生成
- たとえばMalloyのソースを1つ定義し、100個のクエリがそのソースを参照していて、それぞれのクエリから生成されたSQLがBigQueryのテーブル作成を担っているとします。次に、Malloyソースのフィルタにバグが見つかり、ソースに重要なフィルタ修正を加える必要が出たとしましょう。フィルタを更新したあと、Malloyエンジンが上流ソースに依存する下流クエリをすべて再実行することで、100個のBigQueryテーブルの再生成を自動化できます。各クエリに紐づくメタデータが、どのBigQueryテーブルを再生成すべきかをMalloyエンジンに伝えるのです。
5. …まだまだあります!
これらの機能が組み合わさると、組織にどのような恩恵をもたらし、より効果的にスケールでの運用を可能にするのか — 実践的な例で見ていきましょう。
Malloy実践編:現場の本番ユースケース
あなたが、カスタマーサポートのチケットシステムを持つ企業で働いていると仮定しましょう。このシステムには、複数のグループにまたがるトピックのチケットが集まります。技術系のチケット、セールス対応のチケット、財務関連のチケットなどです。エンジニアリング、セールス、財務の各チームは、チケットの扱われ方に関するさまざまな指標を捕捉したいと考えていますが、基本的にはそれぞれ自分のグループに関連する指標にしか関心がありません。
Malloyを使わない場合、各グループのエンジニアが生のチケットシステムのデータセットにアクセスし、必要な指標やレポートを作るために自分なりのやり方でデータを加工する、というのが典型的なシナリオです。同じグループ内ですら複数のデータエンジニアがほぼ独立して動き、フィルタリング、ジョイン、集計のやり方が微妙に異なる、ということもしばしばです。
このアプローチによるレポート作成は残念な結果を招きます。考慮すべき難しいフィルタやエッジケースが数多く存在し、データセットを扱うすべてのエンジニアがそれらをそれぞれ独立に発見できるとは到底思えないからです。主要な指標を計算する前に処理しておくべき課題には、たとえば次のようなものがあります。
- 「スパム」のようなチケットを除外する必要
- PIIデータを含むなど、さまざまな理由で「スクラブ」されたチケットを除外する必要
- アプリのテストなど、社内で生成されたチケットを除外する必要
- チケット割当までの時間、初回応答時間、エスカレーション応答時間、チケット解決時間、SLO違反時間など、難しい計算をグループ間で再現可能にする必要
- 類似ディメンション間の明確な区別の必要。たとえば、チケットの履歴を通じて割り当てられた「当初」「現在」「最高」「最低」の優先度。レポートが「チケットの優先度」と言うとき、いったいどれを指しているのでしょうか?
- 複雑な正規表現を使って特定のチケットから抽出した有用なディメンションを捕捉する能力。抽出対象のテキストは複数のフォーマットを取り得ます。
Malloyを使えば、これらの懸念はことごとく些細なものになっていきます。
部門横断的な機能を念頭にこの問題に取り組むエンジニアは、まずすべてのグループが利用する基盤となるMalloyソースを書くことから始められます — それをticketsと呼びましょう。前述のすべての課題に対処したうえで、ticketsソースは次の擬似コードのようになるかもしれません。
source: tickets is table('bigquery_project.dataset_name.table_name'){ primary_key: id where: spam_ticket = false, scrubbed_ticket = false, internal_test_ticket = false join_one: priority_history on priority_history.ticket_id = id join_one: agents is users on agents.id = assignee_id dimension: priority_original is priority_history.priority_original dimension: priority_highest is priority_history.priority_highest dimension: priority_highest_chartable is priority? pick '1_urgent' when 'urgent' pick '2_high' when 'high' pick '3_normal' when 'normal' pick '4_low' when 'low' else null dimension: priority_current is priority dimension: agent_is_engineer is agents.agent_is_engineer dimension: agent_is_sales is agents.agent_is_sales dimension: agent_is_finance is agents.agent_is_finance dimension: special_request_requester_email is pick coalesce(lower(regexp_extract(description, r'Requested by: (\S+@doit(?:-intl)?\.com)\n')), lower(regexp_extract(subject, r'^(\S+@doit(?:-intl)?\.com) ', 1))) when is_special_request = true else null dimension: time_to_solve_hours is seconds(created_at to solved_at) / 3600 measure: avg_solve_time_hours is round(avg(time_to_solve_hours), 1) measure: ticket_count is count(distinct id)}ticketsにジョインしているMalloyソース — usersとpriority_history — を定義するコードはここでは示していませんが、それを見なくても、これらのソースがどう使われているかは理解できます。エージェントの職務役割やチケット優先度履歴に関するディメンションの定義に使われていることは明らかです。ticketsソースに取り込まれているそれらのディメンションが具体的にどう定義されているかは、ほとんど重要ではありません。これがMalloyのモジュール性を活かしたコードベースの妙味です。
この基盤ソース(これ自体が他の2つのソースへのジョインに依存しています)が用意できたら、ticketsソースに依存する子ソースを部門ごとに複数作成できます。
source: engineering_tickets is tickets { where: agent_is_engineer = true}source: sales_tickets is tickets { where: agent_is_sales = true}source: finance_tickets is tickets { where: agent_is_finance = true}こうして部門ごとに最適化されたMalloyソースが用意され、複雑なフィルタ・ディメンション・エッジケースが裏側で処理されている状態になりました。各グループのエンジニアは安心してチケットに対するクエリを投げかけることができ、指標の計算方法(対象とするチケットや指標計算のロジック)がグループ間で一致することを信頼できます。指標avg_solve_time_hoursのアルゴリズムはticketsソース内で定義されているのに対し、子ソースではaggregateコマンド経由で呼び出されている点に注目してください。
query: avg_solve_time_engineering is engineering_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_sales is sales_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_finance is finance_tickets -> { aggregate: avg_solve_time_hours}さらに各チームが、過去3か月以内に自部門で発生し、かつチケット履歴のいずれかの時点で緊急/P1だったチケットの件数を知りたいとしましょう。
query: tickets_past_3_months_engineering is engineering_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_sales is sales_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_finance is finance_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}こうしたMalloyのクエリは — モジュラーな言語特性のおかげで驚くほど読みやすい一方で — 依存する各ソース内の親ソース依存・ジョイン・フィルタ・集計の数しだいで、何百行にもおよぶSQLにコンパイルされ得ます。
そして、そのSQLは手書きの同等クエリと比べて、はるかに高速かつコスト効率よく実行されます。
このSQLに代わるモジュラーなアプローチには、もうひとつ利点があります。あるクエリでバグが見つかった場合でも、上流の読みやすく比較的シンプルな一連のソースをたどっていくだけで、最終的にバグを発見・修正できるのです。修正後は、その更新されたソースに依存するすべてのクエリ — そしてそれらが支えるデータベースのテーブル/ビュー — を素早く再実行・再構築できます。
こうして、あるグループによるバグ修正が、同じMalloyデータソースの上に構築されている他グループの作業へとスムーズかつ迅速に反映されていくのです。
Malloyのコードは、本当にどこまで明快で簡潔になり得るのか?
先ほどのMalloyソースとクエリの例は、言語のモジュラー性をよく示してはいますが、複雑な問いを投げるときにどれほど明快になり得るかという点では、まだ伝えきれていません。
先に見たように、ticketsソースにジョインされ、チケットの優先度履歴に関するディメンション(当初、現在、そして履歴上の最高優先度)を提供しているpriority_historyソースを見てみましょう。
これらの優先度を判定するには、チケットに加えられた変更履歴を検索する必要があり、複数のネストされたサブクエリを伴うクエリが必要になります。SQLでのネストクエリは見るに堪えないものですが、Malloyのネストクエリはきれいで読みやすい。priority_historyがそれぞれの言語でどう定義されるか、まずはMalloyから比較してみましょう。
source: priority_history is from(field_history{where: field_name = 'priority'} -> { group_by: ticket_id nest: priority_original is { group_by: priority_original is value, updated order_by: updated asc limit: 1 } nest: priority_final is { group_by: priority_final is value, updated order_by: updated desc limit: 1 } nest: priority_urgent_present is { group_by: priority_urgent_present is true where: value = 'urgent' limit: 1 } nest: priority_high_present is { group_by: priority_high_present is true where: value = 'high' limit: 1 } nest: priority_normal_present is { group_by: priority_normal_present is true where: value = 'normal' limit: 1 } nest: priority_low_present is { group_by: priority_low_present is true where: value = 'low' limit: 1 }} -> { project: ticket_id, priority_original.priority_original, priority_final.priority_final, priority_highest is pick 'urgent' when priority_urgent_present.priority_urgent_present = true pick 'high' when priority_high_present.priority_high_present = true pick 'normal' when priority_normal_present.priority_normal_present = true pick 'low' when priority_low_present.priority_low_present = true else null order_by: ticket_id desc})そして、これが生成されるダッシュボード最適化されたSQLです。
WITH __stage0 AS ( SELECT group_set, CASE WHEN group_set IN (0,1,2,3,4,5,6) THEN field_history.ticket_id END as ticket_id__0, CASE WHEN group_set=1 THEN field_history.value END as priority_original__1, CASE WHEN group_set=1 THEN field_history.updated END as updated__1, CASE WHEN group_set=2 THEN field_history.value END as priority_final__2, CASE WHEN group_set=2 THEN field_history.updated END as updated__2, CASE WHEN group_set=3 THEN true END as priority_urgent_present__3, CASE WHEN group_set=4 THEN true END as priority_high_present__4, CASE WHEN group_set=5 THEN true END as priority_normal_present__5, CASE WHEN group_set=6 THEN true END as priority_low_present__6 FROM `project-name.dataset-name.table-name` as field_history CROSS JOIN (SELECT row_number() OVER() -1 group_set FROM UNNEST(GENERATE_ARRAY(0,6,1))) WHERE (field_history.field_name='priority') AND ((group_set NOT IN (3) OR (group_set IN (3) AND field_history.value='urgent'))) AND ((group_set NOT IN (4) OR (group_set IN (4) AND field_history.value='high'))) AND ((group_set NOT IN (5) OR (group_set IN (5) AND field_history.value='normal'))) AND ((group_set NOT IN (6) OR (group_set IN (6) AND field_history.value='low'))) GROUP BY 1,2,3,4,5,6,7,8,9,10), __stage1 AS ( SELECT ticket_id__0 as ticket_id, ARRAY_AGG(CASE WHEN group_set=1 THEN STRUCT( priority_original__1 as priority_original, updated__1 as updated ) END IGNORE NULLS ORDER BY updated__1 asc LIMIT 1) as priority_original, ARRAY_AGG(CASE WHEN group_set=2 THEN STRUCT( priority_final__2 as priority_final, updated__2 as updated ) END IGNORE NULLS ORDER BY updated__2 desc LIMIT 1) as priority_final, ARRAY_AGG(CASE WHEN group_set=3 THEN STRUCT( priority_urgent_present__3 as priority_urgent_present ) END IGNORE NULLS ORDER BY priority_urgent_present__3 asc LIMIT 1) as priority_urgent_present, ARRAY_AGG(CASE WHEN group_set=4 THEN STRUCT( priority_high_present__4 as priority_high_present ) END IGNORE NULLS ORDER BY priority_high_present__4 asc LIMIT 1) as priority_high_present, ARRAY_AGG(CASE WHEN group_set=5 THEN STRUCT( priority_normal_present__5 as priority_normal_present ) END IGNORE NULLS ORDER BY priority_normal_present__5 asc LIMIT 1) as priority_normal_present, ARRAY_AGG(CASE WHEN group_set=6 THEN STRUCT( priority_low_present__6 as priority_low_present ) END IGNORE NULLS ORDER BY priority_low_present__6 asc LIMIT 1) as priority_low_present FROM __stage0 GROUP BY 1 ORDER BY 1 asc), __stage2 AS ( SELECT base.ticket_id as ticket_id, priority_original_0.priority_original as priority_original, priority_final_0.priority_final as priority_final, CASE WHEN priority_urgent_present_0.priority_urgent_present=true THEN 'urgent' WHEN priority_high_present_0.priority_high_present=true THEN 'high' WHEN priority_normal_present_0.priority_normal_present=true THEN 'normal' WHEN priority_low_present_0.priority_low_present=true THEN 'low' ELSE NULL END as priority_highest FROM __stage1 as base LEFT JOIN UNNEST(base.priority_urgent_present) as priority_urgent_present_0 LEFT JOIN UNNEST(base.priority_high_present) as priority_high_present_0 LEFT JOIN UNNEST(base.priority_normal_present) as priority_normal_present_0 LEFT JOIN UNNEST(base.priority_low_present) as priority_low_present_0 LEFT JOIN UNNEST(base.priority_original) as priority_original_0 LEFT JOIN UNNEST(base.priority_final) as priority_final_0 ORDER BY 1 desc)SELECT priority_history.ticket_id as ticket_id, priority_history.priority_original as priority_original, priority_history.priority_final as priority_final, priority_history.priority_highest as priority_highestFROM __stage2 as priority_historyあなたなら、どちらをデバッグしたいでしょうか?
覚えておいてほしいのは、tickets_historyはticketsソースにジョインしてチケット分析でディメンションを使えるようにしているMalloyソースのほんの1つにすぎず、ticketsソースのSQLが内包する複雑さの、ごく小さな一部を表しているにすぎないということです。私が実際にやっているように、20個のMalloyソースをticketsにジョインし、各ジョインからディメンション/メジャーを使うとなったら、そのticketsソースのSQLを書き、デバッグする際の複雑さを想像してみてください。
Malloy + Looker:効率的、スケーラブル、協働的。信頼に足るデータエンジニアリングの実現

「全体は部分の総和に勝る」 — アリストテレス
上で紹介した例は架空の話ではなく、私がDoiT Internationalで立ち上げた、協働的なデータの取り組みをそのまま反映したものです。複数のデータシステム(チケット、セールス、ユーザー、従業員など)の探索を、経営層がそのデータセット上の分析に最大限の信頼を置けて、かつ仲間のデータエンジニアが参加するための導入コストを最小限に抑えられるフレームワークの中で統合することを目指しました。
Malloyは協働分析への道のりを確実に後押ししてくれる素晴らしいツールですが、それ単体では、新しい言語を学ぶよりもレポートを素早く生成したいエンドユーザー(つまり経営層・上級管理職)にとっての使いやすさまでは実現できません。これに対処するため、私は最先端のダッシュボードツール、たとえばLookerと組み合わせて使うことで、Malloyが真価を発揮することを発見しました。
他のBIツールと比べて、Lookerは中央集約された「単一の真実の源」として機能するよう専用設計されています。独自言語LookMLでディメンションとメジャーの定義を適切にセットアップしておけば、想像し得るほぼあらゆる対象に対する直感的なチャート生成を、技術者でない人にすら数分で教えられます。ユーザーは見たいディメンションとメジャー(複数のテーブルにまたがっていても構いません)をクリックし、必要に応じてフィルタを追加したりディメンションでピボットしたりして、最後にRunを押すだけ。LookerのExplore UIに慣れれば、複数のデータソースをまたぐチャートも数秒で作れます。
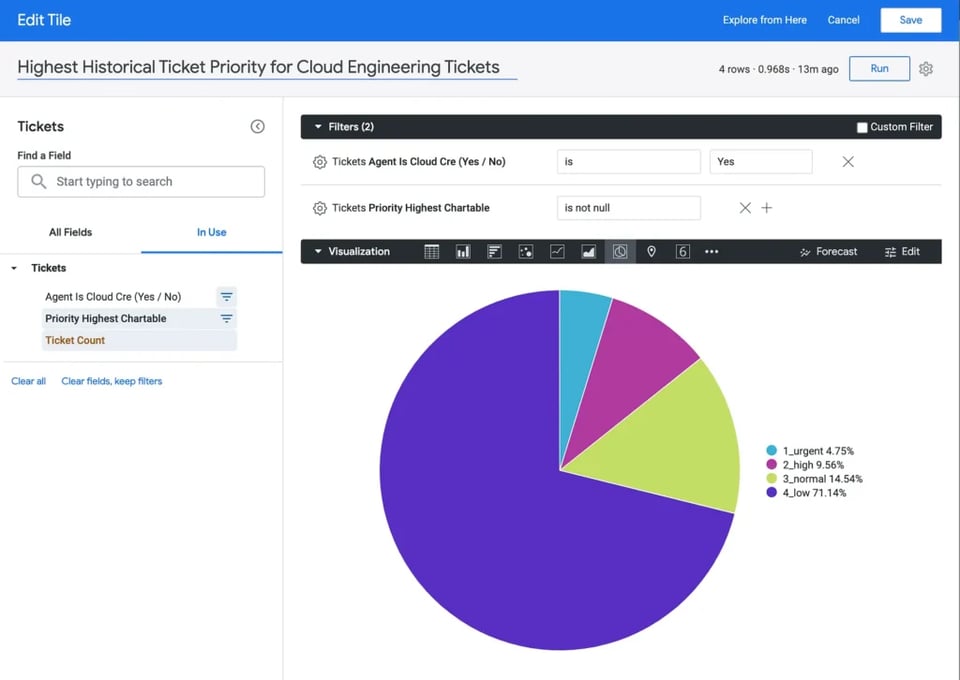
もうひとつ、別の例にすぐ飛び込んでみましょう。経営層の誰かが、エンジニアリングチームに割り当てられたチケット全体に占める各優先度の比率を知りたいと考えているとします。より正確に言えば、エンジニアが扱うチケットがそのライフサイクルのいずれかの段階で到達した最高優先度を特定したい、ということです。
先ほどのticketsソースから生成されたSQLがLooker内で使えるようになっていると仮定すれば、エンドユーザーはこの問いに答えるためにLooker上で次のように操作するだけで済みます。
- Looker内で「Tickets」データセットを選択
- 「Priority Highest Chartable」ディメンションをクリック
- 「Ticket Count」メジャーをクリック
- 「Agent is Cloud Cre Is Yes」というディメンションにフィルタを追加
- 円グラフのビジュアライゼーションをクリックし、Runを押す
右上の実行時間に注目してください。Malloy生成のSQLから作成されたデータテーブルにアクセスしているため、クエリは1秒未満で実行されました。
Lookerのエンドユーザーにとっての使いやすさに、開発・本番環境のダッシュボードデプロイを可能にするバージョン管理システムや、ダッシュボードおよびダッシュボードフォルダに対するきめ細やかなIAM権限を実現する高度なセキュリティ設定といった他の最新機能を組み合わせれば、Malloyコードで定義されたデータソースの可視化に最適なツールである理由は明らかでしょう。
データの一貫性こそが要
Malloy生成のSQLをLookerや任意のダッシュボードツールに統合する際に、ひとつだけ忘れてはならないことがあります。信頼性が高くアクセスしやすいデータウェアハウスを構築するための鍵は、これです。
レポートを生成するエンドユーザーには、生データへのアクセス権を絶対に与えないこと!
生データへのアクセスこそが、グループや部門ごとに作成されるレポートを支えるデータが食い違い、矛盾する根本原因です。なぜなら、各グループのエンジニアは — そして同じグループ内の複数のエンジニアでさえ — フィルタリング、ジョイン、集計について必ず独自のやり方を追求してしまうからです。
そのかわりに、レポート作成者(たとえばLookerのエンドユーザー)に提示するのは、Malloyソースに裏打ちされたテーブル_のみ_にしてください。Malloyソース(そしてある程度はLookMLも)は理想的には、よくあるエッジケース、フィルタ、複雑なジョイン、ディメンションや集計の定義をすべて事前に処理してくれているはずです。これらすべての複雑さを、個々のレポート作成者が完全に正しく扱えるとは思えませんし、ましてや複数グループ分のアナリストの間で一貫して再現できるはずがありません。
十分に検証され、協働で設計されたMalloyソース群を、Looker内で構築の出発点として使える唯一の選択肢として提示すれば、最高品質のデータがアナリティクスを支えることが保証されるだけでなく、異なるグループのエンドユーザーがチャートを作成しても、その数値が他グループのチャートとほぼ一致するか、極めて近い値になることが保証されます。データの複雑さは可能な限り舞台裏で処理し、エンドユーザーに影響が及ばないようにすることが重要です。
現時点での制限事項
MalloyとLookerを組み合わせて、スケーラブルで信頼性が高く、協働で開発できるデータウェアハウスとレポートシステムを設計するこの手法はDoiTでうまく機能していますが、いくつかの(一時的な)制限があります。具体的には次のとおりです。
- Malloyはまだ初期開発段階の新しいプログラミング言語です。私自身の日常利用ではすでに安定していると感じていますが、エッジケースではバグに遭遇する可能性もあります。多くの場合、最新かつ最良の機能はVSCodeプラグインのプレリリースチャネルで入手できます。それでも、Malloy SlackチャネルのMalloy開発者たちは協力的で、バグ報告、機能リクエスト、デバッグ支援にはたいてい当日中に応えてくれます。
- MalloyはBigQuery、Postgres、DuckDB(およびその延長としてCSV/TSV/Parquet形式やバケット内のオブジェクト)をサポートしていますが、RedshiftやSnowflakeといった他のデータウェアハウスプラットフォームはまだサポートしていません。とはいえ、このオープンソースプロジェクトが成熟するにつれ、「複雑なデータセットの分析のために専用設計された言語」というミッションを追求する以上、最も普及しているデータウェアハウスソリューションがいずれサポートされないとは考えにくいでしょう。
- Lookerを支える言語LookMLは独自仕様の言語であり、私の見るところ、ドキュメントの質の低さ、ウォークスルー型の学習素材の不足、そして「詳しくは営業までお問い合わせください」というスタイルのエンタープライズ価格設定により、導入のハードルが大きく高まっています。Lookerなしでも、Malloyはエンドユーザー支援機能ではやや劣るがコスト効率に優れたBIツール、たとえばLooker Studioなどの強力な基盤になり得ます。
スケーラブルで協働開発可能なデータウェアハウスとレポートシステムを成功裏に設計する
MalloyとLookerをうまく統合し、組織のあらゆる階層がより効果的かつ信頼性高く運用できる土台となるデータ基盤を作り、データエンジニア、アナリスト、Cスイートチームの失われかけた正気を少しでも取り戻せるよう、皆さんの成功を祈っています :)
本記事で紹介したアプローチを、組織全体のデータウェアハウス成功のためにご自身の組織で活用するうえで、まだ疑問はありますか?
DoiT Internationalまでお気軽にご連絡ください。シニアエンジニアのみで構成された当社は、高度なクラウドコンサルティングのアーキテクチャ設計とデバッグに関するアドバイスを — 完全に無償で — 提供することを専門としています。
その他のクラウドデータアーキテクチャに関するトピックの深掘りに関心がある方は、MediumおよびDoiT Internationalブログにある私の他の記事もぜひご覧ください。