Das folgende Szenario kommt allzu häufig vor – und blieb über Jahrzehnte ungelöst. Vielen Data Engineers, Business-Analysten und datengetriebenen Führungskräften dürfte es bekannt vorkommen:

Verwirrung gehört in jeder datenzentrierten Karriere irgendwann dazu
Ihr Unternehmen besteht aus mehreren Teams, Gruppen oder Abteilungen, die jeweils ein eigenes Datenteam haben, das die eigenen Datensätze verarbeitet, speichert und auswertet. Die Kommunikation zwischen den Gruppen ist minimal. Wenn teamübergreifender Datenzugriff erforderlich ist, gewähren die Engineers des datenführenden Teams den Zugriff bei Bedarf, beteiligen sich aber selten an Code-Reviews, um zu prüfen, ob die anfragende Person die Daten korrekt – oder zumindest konsistent zu den Abfragen des datenführenden Teams – abfragt. Selbst einfache Sachverhalte lassen sich in SQL manchmal nur umständlich ausdrücken. Wächst eine Organisation und werden ihre Fragestellungen komplexer, wird die Validierung von Abfragen anderer Teams zu einem zeitraubenden Engpass im teamübergreifenden Review von Datenverarbeitungscode.
Aus dieser dürftigen Zusammenarbeit folgt: Führungskräfte, die Daten und Diagramme für Entscheidungen und Präsentationen zusammentragen, stellen mitunter fest, dass die Zahlen einer Gruppe zu ähnlichen Themen erheblich von den Zahlen einer anderen Gruppe abweichen – obwohl beide auf dieselben Rohdaten zugreifen. Entsprechend kommen verschiedene Gruppen zu widersprüchlichen Schlussfolgerungen.
Wenn Führungskräfte ihre Engineering-Teams nach Lösungen für diese Inkonsistenzen fragen, finden sie meist nur wenige. Mögliche Gründe:
- Die schiere Größe des Problems im Verhältnis zur Teamgröße. Allein aus einer einzigen Gruppe können Hunderte Abfragen stammen, die jeweils von anderen Gruppen validiert und ggf. korrigiert werden müssten. Schlicht zu wenig Personal und Zeit für teamübergreifende Code-Reviews der Datenpipelines.
- Die einer Abfrage zugrunde liegenden Datensätze einer Gruppe können für eine andere Gruppe so irrelevant sein, dass es sich für deren Engineers nicht lohnt, sich einzuarbeiten, um eine sinnvolle teamübergreifende Validierung zu leisten. Eine einzige Abfrage kann hochkomplex sein, hunderte Codezeilen umfassen und Joins zu Datensätzen enthalten, deren Verständnis außerhalb des Reviews kaum geschäftlichen Nutzen bringt. Solches SQL nachzuvollziehen ist für jeden außer den ursprünglichen Entwicklern aufwendig.
Angesichts dieser Hürden entscheidet sich die Führung mitunter dafür, einen Datenanalysten anzustellen, der ihre Abfragen übernimmt – in der Hoffnung, von dieser Person verlässliche Berichte zu erhalten. Diese Strategie umgeht jedoch das Kernproblem: Verschiedene Gruppen ziehen aus denselben Rohdaten unterschiedliche Ergebnisse, wenn sie ähnliche oder verwandte Fragen stellen. Solche Inkonsistenzen führen zu unterschiedlichen datenbasierten Entscheidungen innerhalb eines Unternehmens, selbst wenn die Gruppen auf dieselben Rohdaten zugreifen. Da der Analyst der Führung außerdem mit mehreren Gruppen für deren Datensätze kommunizieren muss, perpetuiert er meist die bestehenden Diskrepanzen in der Datenverarbeitung zwischen den Gruppen.

Den Spruch kennen wir alle
In einer datengetriebenen Welt ist alles davon abhängig, dass man den Daten, die Entscheidungen tragen, vertrauen kann. Wie es im Machine Learning heißt:
Garbage (Daten) in, Garbage (Vorhersagen) out.
Alle Rohdatenquellen einfach in ein modernes Data Warehouse – BigQuery, Snowflake, Redshift usw. – einzuspeisen und nach Bedarf Zugriff zu gewähren, löst die eigentlichen Probleme nicht: unternehmensweit konsistente Datenverarbeitung, mangelnde teamübergreifende Zusammenarbeit und die kollektive Vertrauenswürdigkeit der Ergebnisse über alle Abteilungen hinweg.
Der typische, teamzentrierte Ansatz im Data Warehousing und in der Analytik führt dazu, dass Abfragen und Datenquellen eines Teams – wenn überhaupt – kaum von anderen Teams wiederverwendet werden können. Silo-Reporting verfestigt sich, und Gruppen vertrauen am Ende nur dem, was ihr eigenes Datenteam liefert. Die Führung bleibt ohne ein verlässliches, konsistentes Gesamtbild ihrer Organisation.

Das offizielle Logo von Malloy, einer Abfragesprache, die Ihnen das Leben erheblich erleichtern wird
An dieser Stelle kommt Malloy ins Spiel – eine analytische Sprache aus der Feder der ehemaligen Gründer und Entwickler von Looker / LookML, die heute bei Google arbeiten.
Malloy wurde entwickelt, um die Schwächen von SQL zu überwinden – einer Sprache, die 1979 und damit vor 44 Jahren auf den Markt kam, lange bevor es Data Warehouses gab. Im Kern ist Malloy ironischerweise ein SQL-Compiler, aber eben deutlich mehr als das. Es gibt mehrere zentrale Vorteile, wenn Sie Ihre Dateninfrastruktur auf von Malloy generiertem SQL aufbauen, statt Ihre Engineering-Teams um handgefertigtes SQL zu bitten. Bevor wir uns diese Vorteile ansehen, hören wir aber zunächst direkt vom Malloy-Team, warum SQL überhaupt einen Nachfolger braucht:
Ben Porterfield, Mitgründer von Looker und Malloy
SQL ist eine mächtige Sprache, mit der sich jede denkbare Abfrage formulieren lässt. Aber sie hat ihre Schattenseiten:
Alles ist ausdrückbar, aber nichts wiederverwendbar
Einfache Sachverhalte sind nur umständlich auszudrücken
Die Sprache ist redundant und kennt keine sinnvollen Defaults
Malloy ist für SQL-Anwender sofort verständlich und deutlich einfacher zu nutzen und zu erlernen [1]
[1] https://malloydata.github.io/documentation/about/features.html
Carlin Eng, Product Manager Malloy
Sprache ist ein Werkzeug des Denkens, und die Verbesserung der Syntax einer Sprache hat tiefgreifende Auswirkungen darauf, was wir uns vorstellen und ausdrücken können. SQL wurde in den 1970er-Jahren erfunden, lange bevor es Data Warehouses gab – die heutigen Anwendungsfälle konnten also gar nicht mitgedacht werden.
Malloy hingegen ist eigens für die Analyse komplexer Datensätze konzipiert.
Mit diesen Punkten im Hinterkopf bietet Ihnen die Entwicklung mit Malloy statt SQL die folgenden Vorteile:
- Eine einfache und prägnante Syntax, selbst für komplexeste Abfragen. Vorbei sind die Zeiten, in denen Sie Zeile für Zeile Boilerplate-SQL schreiben und sich mühen, anspruchsvolle Datenpunkte effizient zu erheben, ohne ständig auf temporäre Tabellen auszuweichen. Die Einfachheit der Sprache verbessert deutlich:
- kollaborative Entwicklung
- Entwicklungstempo
- Vertrauenswürdigkeit der Ergebnisse
2. Eine modulare und wiederverwendbare Codebasis! Beispiele dafür sind:
- Komplexe Datenquellen lassen sich definieren und dann als Grundlage für weitere Quellen und Abfragen nutzen. Die Komplexität einer Quelle lässt sich reduzieren, indem man sie in mehrere einfachere Eltern-Kind-Datenquellen zerlegt.
- Pipelining von Operationen. Die Ausgabe einer Abfrage kann die Eingabe für die nächste sein.
3. Auf Dashboard-Performance optimierte SQL-Generierung
- Der SQL-Compiler ist gut optimiert und übertrifft alle komplexen, handgeschriebenen Abfragen, mit denen ich ihn verglichen habe. Das ist wichtig, denn Zeit ist Geld – im wahrsten Sinne. Werfen Sie einen Blick auf die Preismodelle von BigQuery Editions, Snowflake und Serverless Redshift.
4. (Demnächst) Automatisierte Neuerstellung von Tabellen und Views nach Änderungen an Malloy-Quellen und -Abfragen
- Angenommen, Sie haben eine Malloy-Quelle definiert, 100 Abfragen greifen darauf zu, und das aus jeder Abfrage generierte SQL erzeugt jeweils eine BigQuery-Tabelle. Nehmen wir weiter an, Sie entdecken einen Fehler darin, wie die Malloy-Quelle gefiltert wird, und müssen daher einen entscheidenden Filter ändern. Nach dieser Anpassung können Sie die Neuerstellung aller 100 BigQuery-Tabellen automatisieren, indem Sie die Malloy-Engine alle nachgelagerten Abfragen, die von dieser Quelle abhängen, erneut ausführen lassen. Über Metadaten zu jeder Abfrage weiß die Malloy-Engine, welche BigQuery-Tabelle eine Malloy-Abfrage neu erzeugen soll.
5. … und vieles mehr!
Schauen wir uns ein praktisches Beispiel an, um zu verstehen, wie diese Funktionen ineinandergreifen, um einer Organisation echten Mehrwert zu bringen und sie effektiver skalieren zu lassen.
Malloy in Aktion: ein realer Produktiv-Anwendungsfall
Stellen Sie sich vor, Sie arbeiten in einem Unternehmen mit einem Kundensupport-Ticketsystem. Über dieses System werden Tickets zu Themen aus mehreren Bereichen erfasst: technische Tickets, Vertriebs-Tickets und Finance-Tickets. Engineering, Vertrieb und Finance interessieren sich also für unterschiedliche Kennzahlen rund um die Bearbeitung von Tickets – jede Gruppe in der Regel aber nur für ihre eigenen.
Ohne Malloy bedeutet dieses Szenario typischerweise: Aus jeder Gruppe erhält ein Engineer Zugriff auf den Rohdatensatz des Ticketsystems und manipuliert die Daten nach eigenem Gutdünken, um die nötigen Kennzahlen und Berichte zu erzeugen. Häufig arbeiten innerhalb derselben Gruppe sogar mehrere Data Engineers weitgehend unabhängig voneinander, filtern, joinen und aggregieren die Daten dabei jeweils etwas anders.
Dieser Reporting-Ansatz ist bedauerlich, denn es gibt zahlreiche knifflige Filter und Edge Cases zu berücksichtigen, die kaum ein Data Engineer für sich allein vollständig findet. Beispiele für Probleme, die vor der Berechnung zentraler Kennzahlen behandelt werden sollten:
- Spam-artige Tickets müssen ausgeschlossen werden
- ‚Bereinigte‘ Tickets, die aus verschiedenen Gründen entfernt wurden – z. B. weil sie PII-Daten enthielten – müssen ausgeschlossen werden
- Intern erzeugte Tickets, etwa aus App-Tests, müssen ausgeschlossen werden
- Reproduzierbarkeit über Gruppen hinweg bei anspruchsvollen Berechnungen wie: Zeit bis zur Ticketzuweisung, erste Reaktionszeit, Reaktionszeit bei Eskalationen, Lösungszeit, SLO-Verletzungszeit usw.
- Klare Abgrenzung zwischen ähnlichen Dimensionen. Beispiel: ursprüngliche vs. aktuelle vs. höchste vs. niedrigste Ticketpriorität im Verlauf eines Tickets. Wenn ein Bericht von "Ticketpriorität" spricht, welche ist gemeint?
- Möglichkeit, wertvolle Dimensionen über komplexe reguläre Ausdrücke aus bestimmten Tickets zu extrahieren, wobei der extrahierte Text in mehreren Formaten vorliegen kann.
Mit Malloy werden all diese Sorgen nahezu trivial.
Engineers, die dieses Problem mit Blick auf abteilungsübergreifende Funktionalität angehen, beginnen am besten mit einer fundamentalen Malloy-Quelle, die alle Gruppen nutzen – nennen wir sie tickets. Wenn sie alle oben genannten Punkte abdeckt, könnte die tickets-Quelle in etwa so aussehen wie der folgende Pseudocode:
source: tickets is table('bigquery_project.dataset_name.table_name'){ primary_key: id where: spam_ticket = false, scrubbed_ticket = false, internal_test_ticket = false join_one: priority_history on priority_history.ticket_id = id join_one: agents is users on agents.id = assignee_id dimension: priority_original is priority_history.priority_original dimension: priority_highest is priority_history.priority_highest dimension: priority_highest_chartable is priority? pick '1_urgent' when 'urgent' pick '2_high' when 'high' pick '3_normal' when 'normal' pick '4_low' when 'low' else null dimension: priority_current is priority dimension: agent_is_engineer is agents.agent_is_engineer dimension: agent_is_sales is agents.agent_is_sales dimension: agent_is_finance is agents.agent_is_finance dimension: special_request_requester_email is pick coalesce(lower(regexp_extract(description, r'Requested by: (\S+@doit(?:-intl)?\.com)\n')), lower(regexp_extract(subject, r'^(\S+@doit(?:-intl)?\.com) ', 1))) when is_special_request = true else null dimension: time_to_solve_hours is seconds(created_at to solved_at) / 3600 measure: avg_solve_time_hours is round(avg(time_to_solve_hours), 1) measure: ticket_count is count(distinct id)}Den Code für die Malloy-Quellen, die wir an tickets joinen – users und priority_history – zeigen wir hier nicht, aber wir brauchen ihn auch nicht zu sehen, um zu verstehen, wie diese Quellen verwendet werden. Ihre Rolle bei der Definition von Dimensionen rund um die Funktion des Agenten und die Prioritätshistorie eines Tickets ist klar erkennbar. Wie genau diese in tickets übernommenen Dimensionen aufgebaut sind, ist weitgehend irrelevant. Genau das ist die Schönheit einer Codebasis, die den modularen Charakter von Malloy konsequent nutzt.
Mit dieser fundamentalen Quelle (die selbst auf Joins zu zwei weiteren Quellen aufbaut) können Sie nun mehrere abgeleitete Quellen definieren, die jeweils auf eine Abteilung zugeschnitten sind:
source: engineering_tickets is tickets { where: agent_is_engineer = true}source: sales_tickets is tickets { where: agent_is_sales = true}source: finance_tickets is tickets { where: agent_is_finance = true}Jetzt haben wir für jede Abteilung eine eigens zugeschnittene Malloy-Quelle, in der mehrere komplexe Filter, Dimensionen und Edge Cases bereits unter der Haube behandelt werden. Engineers in den jeweiligen Gruppen können nun Abfragen auf Tickets formulieren und sich darauf verlassen, dass ihre Kennzahlen über Gruppen hinweg konsistent berechnet werden (also dieselben Tickets berücksichtigen und dieselbe Rechenlogik nutzen). Beachten Sie, dass der Algorithmus hinter der Kennzahl avg_solve_time_hours in der tickets-Quelle definiert, in den abgeleiteten Quellen aber per aggregate aufgerufen wird:
query: avg_solve_time_engineering is engineering_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_sales is sales_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_finance is finance_tickets -> { aggregate: avg_solve_time_hours}Nehmen wir an, jedes Team möchte außerdem wissen, wie viele Tickets in den letzten drei Monaten in seiner Abteilung erzeugt wurden, die zu irgendeinem Zeitpunkt in der Historie als dringend/P1 eingestuft waren:
query: tickets_past_3_months_engineering is engineering_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_sales is sales_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_finance is finance_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}Solche Malloy-Abfragen – dank der modularen Sprachstruktur überraschend gut lesbar – können sich, je nach Anzahl übergeordneter Quellabhängigkeiten, Joins, Filter und Aggregationen, in hunderte SQL-Zeilen kompilieren.
Dieses SQL läuft deutlich schneller – und kosteneffizienter – als jedes handgeschriebene Pendant.
Diese modulare SQL-Alternative bedeutet außerdem: Wird in einer Abfrage ein Bug entdeckt, müssen Sie lediglich eine Reihe übergeordneter, gut lesbarer und wenig komplexer Quellen durchgehen, um den Fehler zu finden und zu beheben. Sobald der Bug korrigiert ist, lassen sich alle abhängigen Abfragen – und die davon gespeisten Tabellen/Views – schnell neu ausführen und neu aufbauen.
Bugfixes einer Gruppe lassen sich so nahtlos und schnell in die Arbeit anderer Gruppen integrieren, die auf denselben Malloy-Datenquellen aufbauen.
Wie klar und prägnant ist Malloy-Code wirklich?
Die obigen Beispiele für Malloy-Quellen und -Abfragen veranschaulichen die Modularität gut, werden aber der Klarheit der Sprache bei komplexen Fragestellungen nicht voll gerecht.
Schauen wir uns die priority_history-Quelle an, die – wie oben gezeigt – in die tickets-Quelle gejoint wird, um Dimensionen rund um die Prioritätshistorie eines Tickets bereitzustellen, nämlich: ursprüngliche, aktuelle und historisch höchste Priorität.
Diese Prioritäten zu ermitteln, erfordert die Suche in der Änderungshistorie eines Tickets – und damit eine Abfrage mit mehreren verschachtelten Unterabfragen. Verschachtelte Abfragen in SQL sind hässlich; in Malloy sind sie sauber und gut lesbar. Vergleichen wir, wie priority_history in beiden Sprachen definiert wird – beginnen wir mit Malloy:
source: priority_history is from(field_history{where: field_name = 'priority'} -> { group_by: ticket_id nest: priority_original is { group_by: priority_original is value, updated order_by: updated asc limit: 1 } nest: priority_final is { group_by: priority_final is value, updated order_by: updated desc limit: 1 } nest: priority_urgent_present is { group_by: priority_urgent_present is true where: value = 'urgent' limit: 1 } nest: priority_high_present is { group_by: priority_high_present is true where: value = 'high' limit: 1 } nest: priority_normal_present is { group_by: priority_normal_present is true where: value = 'normal' limit: 1 } nest: priority_low_present is { group_by: priority_low_present is true where: value = 'low' limit: 1 }} -> { project: ticket_id, priority_original.priority_original, priority_final.priority_final, priority_highest is pick 'urgent' when priority_urgent_present.priority_urgent_present = true pick 'high' when priority_high_present.priority_high_present = true pick 'normal' when priority_normal_present.priority_normal_present = true pick 'low' when priority_low_present.priority_low_present = true else null order_by: ticket_id desc})Vergleichen Sie das mit dem dashboard-optimierten SQL, das daraus generiert wird:
WITH __stage0 AS ( SELECT group_set, CASE WHEN group_set IN (0,1,2,3,4,5,6) THEN field_history.ticket_id END as ticket_id__0, CASE WHEN group_set=1 THEN field_history.value END as priority_original__1, CASE WHEN group_set=1 THEN field_history.updated END as updated__1, CASE WHEN group_set=2 THEN field_history.value END as priority_final__2, CASE WHEN group_set=2 THEN field_history.updated END as updated__2, CASE WHEN group_set=3 THEN true END as priority_urgent_present__3, CASE WHEN group_set=4 THEN true END as priority_high_present__4, CASE WHEN group_set=5 THEN true END as priority_normal_present__5, CASE WHEN group_set=6 THEN true END as priority_low_present__6 FROM `project-name.dataset-name.table-name` as field_history CROSS JOIN (SELECT row_number() OVER() -1 group_set FROM UNNEST(GENERATE_ARRAY(0,6,1))) WHERE (field_history.field_name='priority') AND ((group_set NOT IN (3) OR (group_set IN (3) AND field_history.value='urgent'))) AND ((group_set NOT IN (4) OR (group_set IN (4) AND field_history.value='high'))) AND ((group_set NOT IN (5) OR (group_set IN (5) AND field_history.value='normal'))) AND ((group_set NOT IN (6) OR (group_set IN (6) AND field_history.value='low'))) GROUP BY 1,2,3,4,5,6,7,8,9,10), __stage1 AS ( SELECT ticket_id__0 as ticket_id, ARRAY_AGG(CASE WHEN group_set=1 THEN STRUCT( priority_original__1 as priority_original, updated__1 as updated ) END IGNORE NULLS ORDER BY updated__1 asc LIMIT 1) as priority_original, ARRAY_AGG(CASE WHEN group_set=2 THEN STRUCT( priority_final__2 as priority_final, updated__2 as updated ) END IGNORE NULLS ORDER BY updated__2 desc LIMIT 1) as priority_final, ARRAY_AGG(CASE WHEN group_set=3 THEN STRUCT( priority_urgent_present__3 as priority_urgent_present ) END IGNORE NULLS ORDER BY priority_urgent_present__3 asc LIMIT 1) as priority_urgent_present, ARRAY_AGG(CASE WHEN group_set=4 THEN STRUCT( priority_high_present__4 as priority_high_present ) END IGNORE NULLS ORDER BY priority_high_present__4 asc LIMIT 1) as priority_high_present, ARRAY_AGG(CASE WHEN group_set=5 THEN STRUCT( priority_normal_present__5 as priority_normal_present ) END IGNORE NULLS ORDER BY priority_normal_present__5 asc LIMIT 1) as priority_normal_present, ARRAY_AGG(CASE WHEN group_set=6 THEN STRUCT( priority_low_present__6 as priority_low_present ) END IGNORE NULLS ORDER BY priority_low_present__6 asc LIMIT 1) as priority_low_present FROM __stage0 GROUP BY 1 ORDER BY 1 asc), __stage2 AS ( SELECT base.ticket_id as ticket_id, priority_original_0.priority_original as priority_original, priority_final_0.priority_final as priority_final, CASE WHEN priority_urgent_present_0.priority_urgent_present=true THEN 'urgent' WHEN priority_high_present_0.priority_high_present=true THEN 'high' WHEN priority_normal_present_0.priority_normal_present=true THEN 'normal' WHEN priority_low_present_0.priority_low_present=true THEN 'low' ELSE NULL END as priority_highest FROM __stage1 as base LEFT JOIN UNNEST(base.priority_urgent_present) as priority_urgent_present_0 LEFT JOIN UNNEST(base.priority_high_present) as priority_high_present_0 LEFT JOIN UNNEST(base.priority_normal_present) as priority_normal_present_0 LEFT JOIN UNNEST(base.priority_low_present) as priority_low_present_0 LEFT JOIN UNNEST(base.priority_original) as priority_original_0 LEFT JOIN UNNEST(base.priority_final) as priority_final_0 ORDER BY 1 desc)SELECT priority_history.ticket_id as ticket_id, priority_history.priority_original as priority_original, priority_history.priority_final as priority_final, priority_history.priority_highest as priority_highestFROM __stage2 as priority_historyWelches dieser Beispiele würden Sie lieber debuggen?
Bedenken Sie: tickets_history ist nur eine von vielen Malloy-Quellen, die in tickets gejoint wurden, damit ihre Dimensionen in der Ticket-Analytik genutzt werden können – also nur ein kleiner Ausschnitt der Komplexität, die im SQL der tickets-Quelle steckt. Stellen Sie sich vor, Sie müssten dieses SQL schreiben und debuggen, wenn Sie – wie ich es getan habe – 20 Malloy-Quellen an tickets joinen und Dimensionen/Measures aus jedem dieser Joins nutzen.
Malloy + Looker: effizient, skalierbar, kollaborativ. Vertrauenswürdiges Data Engineering, endlich realisiert.

"Das Ganze ist mehr als die Summe seiner Teile" – Aristoteles
Die oben beschriebenen Beispiele sind keine Fiktion, sondern spiegeln die kollaborative Datenreise wider, die ich hier bei DoiT International angestoßen habe. Ich wollte die Auswertung mehrerer Datensysteme (Daten aus Tickets, Vertrieb, Nutzern, Mitarbeitern usw.) in einem Rahmen zusammenführen, der das Vertrauen der Führung in die darauf basierende Analytik maximiert und gleichzeitig die Einstiegshürde für mitwirkende Data Engineers minimiert.
Malloy ist ein hervorragendes Werkzeug, das diese Reise zu kollaborativer Analytik enorm erleichtert. Allerdings ermöglicht die Sprache allein noch keine einfache Nutzung durch Endanwender, die schnell Berichte erzeugen wollen, statt eine neue Sprache zu lernen (also typischerweise Führungskräfte). Hier kommt Malloy erst in Verbindung mit modernen Dashboard-Tools wie Looker richtig zur Geltung.
Im Vergleich zu anderen BI-Tools ist Looker gezielt als zentrale Single Source of Truth konzipiert. Sauber aufgesetzt – über Dimensions- und Measure-Definitionen in der proprietären Sprache LookML – lässt sich die intuitive Diagrammerstellung selbst Nicht-Technikern in wenigen Minuten beibringen. Anwender klicken einfach auf die gewünschten Dimensionen und Measures (die durchaus mehrere Tabellen umfassen können), ergänzen optional ein paar Filter oder einen Pivot und drücken auf "Run". Wer sich einmal in Lookers Explore-UI eingearbeitet hat, erstellt Diagramme über mehrere Datenquellen hinweg in Sekunden.
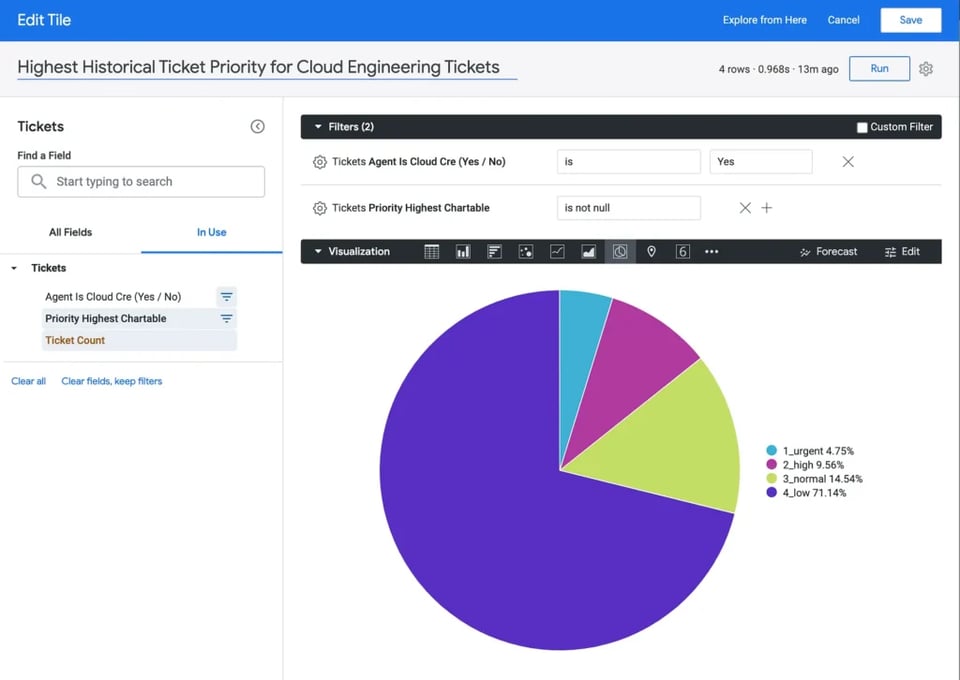
Springen wir direkt in ein weiteres Beispiel. Eine Führungskraft möchte wissen, welchen Anteil die einzelnen Ticketprioritäten an den Tickets ausmachen, die dem Engineering-Team zugewiesen wurden. Genauer: Sie interessiert sich für die höchste Prioritätsstufe, die ein Ticket während einer Phase erreicht hat, in der es von Engineers bearbeitet wurde.
Angenommen, das SQL der tickets-Quelle wurde in Looker bereitgestellt. Ein Endanwender bräuchte in Looker dann lediglich Folgendes zu tun, um diese Frage zu beantworten:
- Den Datensatz "Tickets" in Looker auswählen
- Auf die Dimension "Priority Highest Chartable" klicken
- Auf das Measure "Ticket Count" klicken
- Einen Filter auf der Dimension "Agent is Cloud Cre Is Yes" ergänzen
- Die Visualisierung "Pie Chart" wählen und auf "Run" klicken
Beachten Sie die Laufzeit oben rechts. Da die Abfrage auf eine Tabelle zugreift, die aus Malloy-generiertem SQL erstellt wurde, war sie in unter einer Sekunde fertig:
Kombinieren Sie Lookers Endanwenderfreundlichkeit mit weiteren modernen Funktionen – etwa der Versionsverwaltung für Dev-/Prod-Deployment von Dashboards und den fein granulierbaren IAM-Berechtigungen auf Dashboards und Dashboard-Ordnern – wird klar, warum es ein hervorragendes Werkzeug ist, um per Malloy definierte Datenquellen zu visualisieren.
Datenkonsistenz ist der Schlüssel
Wenn Sie Malloy-generiertes SQL in Looker oder ein anderes Dashboarding-Tool integrieren, dürfen Sie eines nicht vergessen. Die zentrale Regel für ein verlässliches, zugängliches Data Warehouse lautet:
Geben Sie Ihren reportbauenden Endanwendern keinen Zugriff auf Rohdaten!
Rohdatenzugriff ist die eigentliche Ursache für divergierende und widersprüchliche Daten in Berichten unterschiedlicher Gruppen und Abteilungen. Denn Engineers jeder Gruppe – und oft mehrere Engineers innerhalb derselben Gruppe – verfolgen unweigerlich ihre eigenen, individuellen Wege beim Filtern, Joinen und Aggregieren.
Stellen Sie Reportbauern wie Looker-Endanwendern stattdessen ausschließlich Tabellen bereit, die auf Malloy-Quellen basieren. Malloy-Quellen (und teilweise auch LookML) sollten alle gängigen Edge Cases, Filter sowie komplexen Joins und Definitionen für Dimensionen und Aggregationen idealerweise bereits abgedeckt haben. Diese geballte Komplexität kann ein einzelner Reportbauer kaum vollständig korrekt nachbauen – geschweige denn konsistent über mehrere Gruppen von Analysten replizieren.
Wenn ein gut validiertes, gemeinsam entwickeltes Set von Malloy-Quellen die einzige Grundlage in Looker ist, sorgen Sie nicht nur dafür, dass Ihre Analytik mit hochwertigsten Daten arbeitet – Sie stellen auch sicher, dass Diagramme aus unterschiedlichen Gruppen Zahlen liefern, die übereinstimmen oder zumindest sehr eng beieinanderliegen. Es ist wichtig, möglichst viel Datenkomplexität im Hintergrund zu lösen, bevor sie Endanwender überhaupt erreicht.
Aktuelle Einschränkungen
Der gemeinsame Einsatz von Malloy und Looker für ein skalierbares, verlässliches und kollaborativ entwickeltes Data Warehouse mit Reporting hat sich bei DoiT bewährt – kommt aber mit ein paar (vorübergehenden) Einschränkungen. Konkret:
- Malloy ist eine junge Programmiersprache und befindet sich noch in einer frühen Entwicklungsphase. Im täglichen Einsatz halte ich die Sprache für stabil, aber bei Edge Cases kann es weiterhin Bugs geben. Die neuesten Funktionen finden sich oft im Pre-Release-Channel des VSCode-Plugins. Die Malloy-Entwickler im Malloy Slack-Channel sind hilfsbereit und antworten meist noch am selben Tag auf Bug-Reports, Feature-Requests und Debugging-Anfragen.
- Malloy unterstützt zwar BigQuery, Postgres und DuckDB (und damit indirekt CSV/TSV/Parquet sowie Objekte in Buckets), aber bislang keine weiteren Data-Warehouse-Plattformen wie Redshift und Snowflake. Da das Open-Source-Projekt jedoch zunehmend reift, ist kaum vorstellbar, dass die populärsten Data-Warehouse-Lösungen auf Dauer nicht unterstützt werden – schließlich versteht sich Malloy als "purpose-built for analyzing complex datasets".
- LookML, die Sprache hinter Looker, ist proprietär und stellt durch – meiner Meinung nach – mangelhafte Dokumentation, zu wenige walkthrough-orientierte Lernmaterialien und Enterprise-Pricing nach dem Motto "Contact sales to learn more" eine erhebliche Adoptionshürde dar. Auch ohne Looker kann Malloy aber das starke Fundament für weniger endanwenderfreundliche, dafür kosteneffizientere BI-Tools wie Looker Studio bilden.
Erfolgreich ein skalierbares, kollaborativ entwickeltes Data Warehouse mit Reporting aufbauen
Ich wünsche Ihnen viel Erfolg dabei, Malloy und Looker so zu kombinieren, dass eine Datenbasis entsteht, mit der jede Ebene Ihrer Organisation effektiver und verlässlicher arbeiten kann – und die Ihren Data Engineers, Analysten und C-Level-Teams ein Stück verlorener Gelassenheit zurückgibt :)
Haben Sie noch Fragen, wie Sie den hier beschriebenen Ansatz in Ihrer Organisation einsetzen können, um unternehmensweit erfolgreiches Data Warehousing zu ermöglichen?
Melden Sie sich bei DoiT International. Unser Team besteht ausschließlich aus erfahrenen Senior-Engineers, und wir sind auf fortschrittliche Cloud-Beratung in Architektur und Debugging spezialisiert – komplett kostenfrei.
Wenn Sie tiefer in weitere Themen rund um Cloud-Datenarchitektur einsteigen möchten, schauen Sie sich gerne meine anderen Beiträge auf Medium sowie im Blog von DoiT International an.