Quello che segue è uno scenario fin troppo comune — e da decenni privo di una vera soluzione — in cui molti data engineer, business analyst e dirigenti data-driven si riconosceranno facilmente:

La confusione è una tappa inevitabile in qualsiasi carriera incentrata sui dati
La sua organizzazione conta più team, gruppi o dipartimenti, ognuno con il proprio team dati che elabora, archivia e produce report sui propri dataset. La comunicazione tra i gruppi è ridotta al minimo. Quando serve accedere ai dati di un altro team, gli engineer responsabili del dataset possono concedere l'accesso, ma raramente partecipano alle code review per verificare che chi richiede i dati li interroghi correttamente, o quanto meno in modo coerente con le query del team proprietario. Anche le idee più semplici possono risultare complesse da esprimere in SQL: man mano che un'organizzazione cresce e le sue domande si fanno più articolate, validare le query di un altro team diventa un collo di bottiglia che assorbe enormi quantità di tempo.
Conseguenza diretta di questa scarsa collaborazione: i dirigenti che raccolgono dati e grafici per decisioni e presentazioni notano talvolta che, confrontando dati su temi simili prodotti da gruppi diversi, i grafici di un gruppo riportano numeri sostanzialmente differenti rispetto a quelli generati da un altro gruppo a partire dagli stessi dati grezzi. Risultato: le conclusioni di un gruppo si ritrovano in contrasto con quelle di un altro.
Quando i dirigenti chiedono ai team di engineering di sanare queste incongruenze, raramente trovano soluzioni efficaci. Le ragioni sono diverse:
- La portata del problema rispetto alle dimensioni del gruppo. Da un singolo gruppo possono arrivare centinaia di query, ciascuna da validare ed eventualmente correggere insieme agli altri gruppi. Semplicemente, non ci sono né le persone né il tempo per dedicarsi a code review trasversali sulle pipeline dati.
- I dataset alla base delle query di un gruppo possono essere talmente irrilevanti per un altro gruppo che, per gli engineer di quest'ultimo, studiarli a fondo per condurre una validazione accurata diventa un investimento di tempo poco proficuo. Una singola query può essere complessa, contare centinaia di righe di codice e includere join verso dataset che chi rivede il codice non ha alcun reale motivo di conoscere al di fuori della code review stessa. Comprendere SQL di questo tipo richiede tempo a chiunque non sia lo sviluppatore originale.
Davanti a questi ostacoli, la leadership può decidere di affidarsi a un data analyst dedicato, riponendo in lui la fiducia di ottenere report affidabili. Ma è una strategia che aggira il problema di fondo: gruppi diversi ottengono risultati differenti dagli stessi dati grezzi quando affrontano domande simili o correlate. Questa incoerenza si traduce in decisioni data-driven divergenti all'interno della stessa organizzazione, anche quando i gruppi attingono dagli stessi dati grezzi. Inoltre, dovendo dialogare con più gruppi per ottenere i loro dataset, l'analyst di leadership finisce per perpetuare le discrepanze già esistenti nell'elaborazione dei dati tra i gruppi.

Il detto lo conosciamo tutti
In un mondo data-driven, poter contare con fiducia sui dati che guidano le decisioni è tutto. Come recita un noto adagio del machine learning:
Garbage (data) in, garbage (predictions) out.
Limitarsi a collegare tutte le proprie fonti di dati grezzi a un data warehouse di ultima generazione — BigQuery, Snowflake, Redshift e così via — concedendo l'accesso a chi serve, non risolve i problemi alla radice: la coerenza dell'elaborazione dei dati a livello aziendale, la collaborazione tra team e l'affidabilità complessiva dei risultati nei vari dipartimenti.
L'approccio classico, basato su team segmentati, al data warehousing e all'analytics fa sì che ben poche query e fonti dati di un team — se non nessuna — siano davvero riutilizzabili da un altro team. La generazione di report a silos finisce per radicarsi e i gruppi si fidano solo di ciò che produce il proprio team dati. Alla leadership manca così una visione coerente e affidabile dell'organizzazione.

Il logo ufficiale di Malloy, un linguaggio di query che le semplificherà notevolmente la vita
Entra in scena Malloy, un linguaggio analitico nato dagli ex fondatori e sviluppatori di Looker / LookML, oggi parte di Google.
Progettato per superare i limiti di SQL — un linguaggio nato 44 anni fa, nel 1979, ben prima che esistessero i data warehouse — Malloy è, con una certa ironia, un compilatore SQL, ma è molto di più. Costruire la propria infrastruttura dati pensando a SQL generato da Malloy, anziché chiedere ai team di engineering SQL artigianale scritto a mano, comporta diversi vantaggi chiave. Prima di entrare nel merito, però, lasciamo la parola al team di Malloy sul perché serva un'alternativa a SQL:
Le parole di Ben Porterfield, co-fondatore di Looker e Malloy
SQL è un linguaggio potente, capace di esprimere qualsiasi query, ma ha i suoi limiti:
Tutto è esprimibile, ma nulla è riutilizzabile
Le idee semplici sono complesse da esprimere
Il linguaggio è prolisso e privo di default intelligenti
Malloy è immediatamente comprensibile per chi conosce SQL ed è molto più semplice da usare e imparare [1]
[1] https://malloydata.github.io/documentation/about/features.html
Le parole di Carlin Eng, Product Manager di Malloy
Il linguaggio è uno strumento del pensiero e migliorare la sintassi di un linguaggio ha implicazioni profonde su ciò che possiamo immaginare ed esprimere. SQL è stato inventato negli anni '70, prima che esistessero i data warehouse, e quindi non poteva essere stato progettato pensando ai casi d'uso di oggi.
Malloy, al contrario, è stato concepito appositamente per analizzare dataset complessi.
Tenendo a mente questi punti, sviluppare con Malloy invece che con SQL offre i seguenti vantaggi:
- Una sintassi semplice e concisa per scrivere anche le query più complesse. Niente più righe e righe di SQL boilerplate, né acrobazie per raccogliere in modo efficace ed efficiente dati ostici, magari ricorrendo a un uso massiccio di tabelle temporanee. La semplicità del linguaggio migliora notevolmente:
- Lo sviluppo collaborativo
- La velocità di sviluppo
- L'affidabilità degli output
2. Una base di codice modulare e riutilizzabile. Ad esempio:
- Le fonti dati complesse possono essere definite e poi usate come base per altre fonti e query. La complessità di una fonte dati può essere ridotta scomponendola in più fonti più semplici, legate da relazioni padre-figlio.
- Pipelining delle operazioni. L'output di una query può diventare l'input di un'altra.
3. Generazione di SQL ottimizzato per le performance del dashboard
- Il compilatore SQL è ben ottimizzato e, nei miei confronti, supera qualsiasi query complessa scritta a mano. Un aspetto cruciale, perché il tempo è denaro — letteralmente. Basta dare un'occhiata ai modelli di pricing di BigQuery Editions, Snowflake e serverless Redshift.
4. (In arrivo) Ricreazione automatica di tabelle e viste dopo gli aggiornamenti alle fonti e alle query Malloy
- Immagini di avere una fonte Malloy definita, 100 query che la interrogano e l'SQL generato da ciascuna query incaricato di creare una tabella BigQuery. Ipotizziamo poi che scopra un bug nel modo in cui la fonte Malloy viene filtrata e debba quindi modificare un filtro fondamentale. Una volta aggiornato il filtro della fonte, può automatizzare la ricreazione di tutte le 100 tabelle BigQuery facendo rieseguire al motore Malloy tutte le query downstream dipendenti da quella fonte upstream. I metadati associati a ciascuna query indicano al motore Malloy quale tabella BigQuery deve essere ricreata.
5. …e molto altro ancora!
Vediamo un esempio pratico per capire come queste funzionalità possono combinarsi a vantaggio di un'organizzazione, permettendole di operare su larga scala in modo più efficace.
Malloy in azione: un caso d'uso reale in produzione
Immaginiamo che lavori per un'azienda dotata di un sistema di ticketing per il supporto clienti. Attraverso questo sistema vengono aperti ticket su argomenti che coinvolgono più gruppi: ticket tecnici, di sales engagement e finance. I team engineering, sales e finance sono quindi interessati a tracciare metriche diverse sulla gestione dei ticket, ma in genere ogni gruppo si concentra solo sulle metriche del proprio ambito.
Senza Malloy, in uno scenario di questo tipo un engineer di ciascun gruppo accederà al dataset grezzo del sistema di ticketing e manipolerà i dati come ritiene opportuno per generare le metriche e i report richiesti. All'interno dello stesso gruppo possono perfino esserci più data engineer che operano in modo prevalentemente indipendente, filtrando, unendo e aggregando i dati in modi leggermente diversi gli uni dagli altri.
Questo approccio al reporting è penalizzante: i filtri da considerare e gli edge case sono numerosi, ed è improbabile che tutti i data engineer che lavorano sul dataset li scoprano in autonomia. Esempi di problemi da gestire prima del calcolo delle metriche chiave:
- Escludere i ticket di tipo "spam"
- Escludere i ticket "scrubbed", rimossi per vari motivi, ad esempio perché contengono dati PII
- Escludere i ticket generati internamente, ad esempio dai test dell'app
- Garantire la riproducibilità tra i gruppi per calcoli ostici come: tempo di assegnazione del ticket, first response time, tempo di risposta in caso di escalation, tempo di risoluzione del ticket, tempo di breach degli SLO, ecc.
- Distinguere chiaramente tra dimensioni simili. Ad esempio: livello di priorità del ticket originale vs. attuale vs. più alto vs. più basso assegnato nel corso della sua storia. Quando un report parla di priorità del ticket, a quale di queste si riferisce?
- La possibilità di estrarre dimensioni di valore da determinati ticket tramite espressioni regolari complesse, dove il testo estratto può presentarsi in formati molto diversi.
Con Malloy, tutte queste preoccupazioni iniziano a diventare banali.
Gli engineer che affrontano il problema con un'ottica cross-dipartimentale potrebbero partire scrivendo una fonte Malloy fondamentale che tutti i gruppi useranno — la chiameremo tickets. Per gestire tutti i problemi sopra elencati, la fonte tickets potrebbe assomigliare al seguente pseudocodice:
source: tickets is table('bigquery_project.dataset_name.table_name'){ primary_key: id where: spam_ticket = false, scrubbed_ticket = false, internal_test_ticket = false join_one: priority_history on priority_history.ticket_id = id join_one: agents is users on agents.id = assignee_id dimension: priority_original is priority_history.priority_original dimension: priority_highest is priority_history.priority_highest dimension: priority_highest_chartable is priority? pick '1_urgent' when 'urgent' pick '2_high' when 'high' pick '3_normal' when 'normal' pick '4_low' when 'low' else null dimension: priority_current is priority dimension: agent_is_engineer is agents.agent_is_engineer dimension: agent_is_sales is agents.agent_is_sales dimension: agent_is_finance is agents.agent_is_finance dimension: special_request_requester_email is pick coalesce(lower(regexp_extract(description, r'Requested by: (\S+@doit(?:-intl)?\.com)\n')), lower(regexp_extract(subject, r'^(\S+@doit(?:-intl)?\.com) ', 1))) when is_special_request = true else null dimension: time_to_solve_hours is seconds(created_at to solved_at) / 3600 measure: avg_solve_time_hours is round(avg(time_to_solve_hours), 1) measure: ticket_count is count(distinct id)}Il codice che definisce le fonti Malloy unite a tickets — users e priority_history — non è mostrato, ma non serve vederlo per capire come vengono utilizzate. Il loro ruolo nel definire dimensioni legate al ruolo dell'agente e alla cronologia delle priorità del ticket è chiaro. Il modo in cui sono definite le dimensioni richiamate nella fonte tickets è in larga parte irrilevante. Sta tutta qui la bellezza di una base di codice che sfrutta la natura modulare di Malloy.
Con questa fonte fondamentale (a sua volta basata su join verso altre due fonti), si possono creare più fonti figlie dipendenti da tickets, ciascuna specifica per un dipartimento:
source: engineering_tickets is tickets { where: agent_is_engineer = true}source: sales_tickets is tickets { where: agent_is_sales = true}source: finance_tickets is tickets { where: agent_is_finance = true}Ora che abbiamo una fonte Malloy ritagliata su misura per ciascun dipartimento, in cui filtri complessi, dimensioni ed edge case sono già stati gestiti dietro le quinte, gli engineer di ogni gruppo possono interrogare i ticket con la certezza che il modo in cui le metriche sono calcolate (ad esempio i ticket considerati e la matematica alla base del calcolo) sarà identico tra i gruppi. Si noti che l'algoritmo della metrica avg_solve_time_hours è definito nella fonte tickets, ma viene invocato tramite il comando aggregate nelle fonti figlie:
query: avg_solve_time_engineering is engineering_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_sales is sales_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_finance is finance_tickets -> { aggregate: avg_solve_time_hours}Supponiamo poi che ogni team voglia sapere quanti ticket sono stati generati nel proprio dipartimento negli ultimi tre mesi e che, in qualche momento della loro storia, siano stati classificati come urgenti/P1:
query: tickets_past_3_months_engineering is engineering_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_sales is sales_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_finance is finance_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}Query Malloy come queste — sorprendentemente leggibili grazie alla natura modulare del linguaggio — possono compilarsi in centinaia di righe di SQL, a seconda di quante dipendenze, join, filtri e aggregazioni esistano nelle fonti da cui dipendono.
Quel codice SQL sarà molto più veloce — ed economico — di qualsiasi equivalente scritto a mano.
Questa alternativa modulare a SQL implica anche che, se si scopre un bug in una query, basta percorrere a ritroso una serie di fonti upstream, leggibili e di complessità contenuta, per individuare e correggere l'errore. Una volta corretto il bug, tutte le query — e le tabelle/viste del database che alimentano — dipendenti da quella fonte aggiornata possono essere rieseguite e ricostruite rapidamente.
Le correzioni di un gruppo possono così essere integrate, in modo fluido e veloce, nel lavoro degli altri gruppi che si appoggiano alle stesse fonti dati Malloy.
Quanto può essere davvero chiaro e conciso il codice Malloy?
Gli esempi di fonti e query Malloy visti finora illustrano bene la natura modulare del linguaggio, ma non gli rendono pienamente giustizia sul fronte della chiarezza nelle domande complesse.
Diamo un'occhiata alla fonte priority_history che, come abbiamo visto, si unisce a tickets per fornire dimensioni che evidenziano la cronologia delle priorità di un ticket: priorità originale, attuale e più alta nel tempo.
Per determinare queste priorità occorre scorrere la cronologia delle modifiche apportate a un ticket, ovvero una query con più query annidate. Le query annidate in SQL sono brutte; in Malloy sono pulite e facili da leggere. Confrontiamo come priority_history viene definita nei due linguaggi, partendo da Malloy:
source: priority_history is from(field_history{where: field_name = 'priority'} -> { group_by: ticket_id nest: priority_original is { group_by: priority_original is value, updated order_by: updated asc limit: 1 } nest: priority_final is { group_by: priority_final is value, updated order_by: updated desc limit: 1 } nest: priority_urgent_present is { group_by: priority_urgent_present is true where: value = 'urgent' limit: 1 } nest: priority_high_present is { group_by: priority_high_present is true where: value = 'high' limit: 1 } nest: priority_normal_present is { group_by: priority_normal_present is true where: value = 'normal' limit: 1 } nest: priority_low_present is { group_by: priority_low_present is true where: value = 'low' limit: 1 }} -> { project: ticket_id, priority_original.priority_original, priority_final.priority_final, priority_highest is pick 'urgent' when priority_urgent_present.priority_urgent_present = true pick 'high' when priority_high_present.priority_high_present = true pick 'normal' when priority_normal_present.priority_normal_present = true pick 'low' when priority_low_present.priority_low_present = true else null order_by: ticket_id desc})Lo confronti con l'SQL ottimizzato per dashboard che genera:
WITH __stage0 AS ( SELECT group_set, CASE WHEN group_set IN (0,1,2,3,4,5,6) THEN field_history.ticket_id END as ticket_id__0, CASE WHEN group_set=1 THEN field_history.value END as priority_original__1, CASE WHEN group_set=1 THEN field_history.updated END as updated__1, CASE WHEN group_set=2 THEN field_history.value END as priority_final__2, CASE WHEN group_set=2 THEN field_history.updated END as updated__2, CASE WHEN group_set=3 THEN true END as priority_urgent_present__3, CASE WHEN group_set=4 THEN true END as priority_high_present__4, CASE WHEN group_set=5 THEN true END as priority_normal_present__5, CASE WHEN group_set=6 THEN true END as priority_low_present__6 FROM `project-name.dataset-name.table-name` as field_history CROSS JOIN (SELECT row_number() OVER() -1 group_set FROM UNNEST(GENERATE_ARRAY(0,6,1))) WHERE (field_history.field_name='priority') AND ((group_set NOT IN (3) OR (group_set IN (3) AND field_history.value='urgent'))) AND ((group_set NOT IN (4) OR (group_set IN (4) AND field_history.value='high'))) AND ((group_set NOT IN (5) OR (group_set IN (5) AND field_history.value='normal'))) AND ((group_set NOT IN (6) OR (group_set IN (6) AND field_history.value='low'))) GROUP BY 1,2,3,4,5,6,7,8,9,10), __stage1 AS ( SELECT ticket_id__0 as ticket_id, ARRAY_AGG(CASE WHEN group_set=1 THEN STRUCT( priority_original__1 as priority_original, updated__1 as updated ) END IGNORE NULLS ORDER BY updated__1 asc LIMIT 1) as priority_original, ARRAY_AGG(CASE WHEN group_set=2 THEN STRUCT( priority_final__2 as priority_final, updated__2 as updated ) END IGNORE NULLS ORDER BY updated__2 desc LIMIT 1) as priority_final, ARRAY_AGG(CASE WHEN group_set=3 THEN STRUCT( priority_urgent_present__3 as priority_urgent_present ) END IGNORE NULLS ORDER BY priority_urgent_present__3 asc LIMIT 1) as priority_urgent_present, ARRAY_AGG(CASE WHEN group_set=4 THEN STRUCT( priority_high_present__4 as priority_high_present ) END IGNORE NULLS ORDER BY priority_high_present__4 asc LIMIT 1) as priority_high_present, ARRAY_AGG(CASE WHEN group_set=5 THEN STRUCT( priority_normal_present__5 as priority_normal_present ) END IGNORE NULLS ORDER BY priority_normal_present__5 asc LIMIT 1) as priority_normal_present, ARRAY_AGG(CASE WHEN group_set=6 THEN STRUCT( priority_low_present__6 as priority_low_present ) END IGNORE NULLS ORDER BY priority_low_present__6 asc LIMIT 1) as priority_low_present FROM __stage0 GROUP BY 1 ORDER BY 1 asc), __stage2 AS ( SELECT base.ticket_id as ticket_id, priority_original_0.priority_original as priority_original, priority_final_0.priority_final as priority_final, CASE WHEN priority_urgent_present_0.priority_urgent_present=true THEN 'urgent' WHEN priority_high_present_0.priority_high_present=true THEN 'high' WHEN priority_normal_present_0.priority_normal_present=true THEN 'normal' WHEN priority_low_present_0.priority_low_present=true THEN 'low' ELSE NULL END as priority_highest FROM __stage1 as base LEFT JOIN UNNEST(base.priority_urgent_present) as priority_urgent_present_0 LEFT JOIN UNNEST(base.priority_high_present) as priority_high_present_0 LEFT JOIN UNNEST(base.priority_normal_present) as priority_normal_present_0 LEFT JOIN UNNEST(base.priority_low_present) as priority_low_present_0 LEFT JOIN UNNEST(base.priority_original) as priority_original_0 LEFT JOIN UNNEST(base.priority_final) as priority_final_0 ORDER BY 1 desc)SELECT priority_history.ticket_id as ticket_id, priority_history.priority_original as priority_original, priority_history.priority_final as priority_final, priority_history.priority_highest as priority_highestFROM __stage2 as priority_historyQuale dei due esempi preferirebbe dover debuggare?
Tenga presente che tickets_history è solo una delle tante fonti Malloy unite alla fonte tickets per portarne le dimensioni nell'analisi dei ticket: rappresenta quindi solo una piccola parte della complessità che si nasconderebbe dietro l'SQL della fonte tickets. Provi a immaginare la complessità di scrivere e debuggare l'SQL della fonte tickets se, come ho fatto io, dovesse unirvi 20 fonti Malloy e usare dimensioni e measure di ciascuna.
Malloy + Looker: efficienti, scalabili, collaborativi. Un data engineering finalmente affidabile.

"Il tutto è più della somma delle parti" — Aristotele
Gli esempi descritti sopra non sono fittizi: rispecchiano il percorso di analisi dati collaborativa che ho avviato qui in DoiT International. Il mio obiettivo era unificare l'esplorazione di più sistemi di dati (ticket, sales, utenti, dipendenti e così via) all'interno di un framework che massimizzasse la fiducia che la leadership può riporre nelle analisi prodotte su quei dataset, riducendo al minimo l'onboarding richiesto ai colleghi data engineer per contribuire.
Per quanto Malloy sia uno strumento eccezionale che certamente accelera questo percorso verso un'analytics collaborativa, di per sé non garantisce semplicità d'uso agli end-user più interessati a generare report rapidamente che a imparare un nuovo linguaggio (cioè la leadership e il top management). Per ovviare a questo, ho scoperto che Malloy dà il meglio di sé quando è abbinato a strumenti di dashboarding di ultima generazione, come Looker.
Rispetto ad altri tool di BI, Looker è progettato per fungere da fonte di verità centralizzata. Se è configurato correttamente con definizioni di dimensioni e measure scritte nel linguaggio proprietario LookML, la generazione intuitiva di grafici per praticamente qualsiasi cosa può essere insegnata — anche a persone non tecniche — in pochi minuti. Gli utenti devono solo cliccare sulle dimensioni e sulle measure che vogliono visualizzare (anche su più tabelle), eventualmente fare qualche clic in più per aggiungere filtri o pivottare su una dimensione, e premere Run. Una volta presa confidenza con la UI Explore di Looker, generare un grafico che spazia su più fonti dati può richiedere pochi secondi.
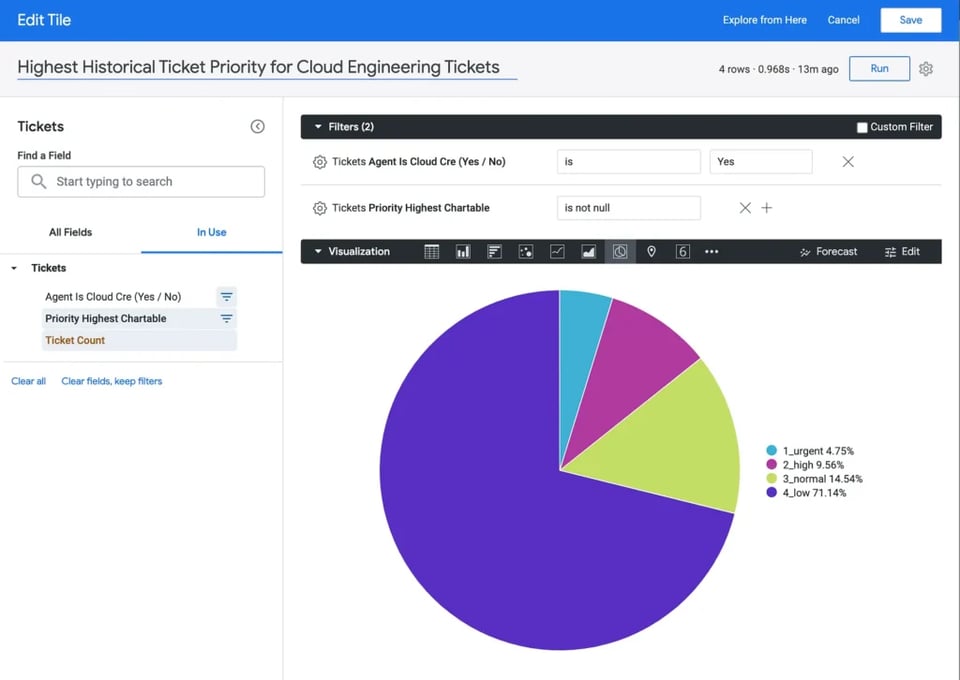
Andiamo dritti a un altro esempio. Supponiamo che una persona in un ruolo di leadership voglia capire la quota di ogni livello di priorità sul totale dei ticket assegnati al team di engineering. Più precisamente, vuole identificare il livello massimo di priorità raggiunto da un ticket in una qualunque fase del suo ciclo di vita gestita dagli engineer.
Se ipotizziamo che l'SQL della fonte tickets sia stato reso disponibile in Looker, l'end-user dovrà semplicemente:
- Selezionare il dataset "Tickets" all'interno di Looker
- Cliccare sulla dimensione "Priority Highest Chartable"
- Cliccare sulla measure "Ticket Count"
- Aggiungere un filtro sulla dimensione "Agent is Cloud Cre Is Yes"
- Cliccare sulla visualizzazione Pie Chart e premere Run
Osservi il runtime in alto a destra. Grazie all'utilizzo di una tabella generata da SQL prodotto da Malloy, la query è stata eseguita in meno di 1 secondo:
Combini la facilità d'uso di Looker per gli end-user con le sue altre funzionalità moderne — come il sistema di version control che abilita il deployment di dashboard dev/prod e le impostazioni di sicurezza avanzate, che consentono permessi IAM granulari su dashboard e cartelle di dashboard — e capirà perché è uno strumento eccellente per visualizzare le fonti dati definite in codice Malloy.
La coerenza dei dati è cruciale
Mentre integra l'SQL generato da Malloy in Looker o nel suo strumento di dashboarding preferito, deve ricordare una cosa. La chiave per costruire un data warehouse affidabile e accessibile è questa:
Non conceda agli end-user che generano report l'accesso ai dati grezzi!
L'accesso ai dati grezzi è la causa profonda dei dati divergenti e contraddittori che alimentano i report di gruppi e dipartimenti diversi. Questo perché gli engineer di ogni gruppo — e spesso più engineer all'interno dello stesso gruppo — finiscono inevitabilmente per adottare modi propri e differenti di filtrare, unire e aggregare le informazioni.
La soluzione: presentare ai report builder, come gli end-user di Looker, solo tabelle alimentate da fonti Malloy. Le fonti Malloy (e in parte anche LookML) avranno idealmente già gestito tutti gli edge case più comuni, i filtri, i join complessi e le definizioni di dimensioni e aggregazioni. È improbabile che tutta questa complessità venga gestita correttamente dai singoli report builder, men che meno replicata in modo coerente tra più gruppi di analyst.
Con un set di fonti Malloy ben validato e progettato in modo collaborativo, presentato come unica base su cui lavorare in Looker, garantisce non solo che ad alimentare l'analytics siano dati della massima qualità, ma anche che, quando gli end-user di gruppi diversi costruiscono grafici, i loro numeri coincidano o si allineino strettamente a quelli prodotti dai grafici degli altri gruppi. È fondamentale gestire la maggior parte della complessità dei dati dietro le quinte, prima che possa avere un impatto sugli end user.
Limiti attuali
Pur avendo funzionato bene in DoiT, l'uso combinato di Malloy e Looker per progettare un data warehouse e un sistema di reporting scalabili, affidabili e sviluppati in modo collaborativo presenta alcuni limiti (temporanei). In particolare:
- Malloy è un linguaggio di programmazione nuovo, ancora nelle prime fasi di sviluppo. Pur considerandolo stabile nel mio uso quotidiano, può ancora capitare di imbattersi in bug per casi d'uso limite. Spesso le ultime novità si trovano sul canale pre-release del plugin VSCode. Detto questo, gli sviluppatori Malloy sul canale Slack di Malloy sono molto disponibili e in genere rispondono in giornata a segnalazioni di bug, richieste di feature e richieste di assistenza al debugging.
- Pur supportando BigQuery, Postgres e DuckDB (e per estensione i formati CSV/TSV/Parquet e gli oggetti archiviati in bucket), Malloy non supporta ancora altre piattaforme di data warehousing come Redshift e Snowflake. Tuttavia, mano a mano che questo progetto open-source maturerà, è difficile immaginare che, data la sua missione di essere "purpose-built for analyzing complex datasets", le soluzioni di data warehousing più diffuse non vengano alla fine supportate.
- LookML, il linguaggio che alimenta Looker, è proprietario e crea barriere all'adozione consistenti, dovute a quella che ritengo una documentazione carente, materiali didattici poco basati su walkthrough e un pricing enterprise in stile "contatti il commerciale per saperne di più". Anche senza Looker, Malloy può fare da base solida per tool di BI meno orientati all'end-user ma più convenienti, come Looker Studio.
Progetti con successo un data warehouse e un sistema di reporting scalabili e sviluppati in modo collaborativo
Le auguro buon lavoro nell'integrare Malloy e Looker per creare una base dati che permetta a ogni livello di un'organizzazione di operare in modo più efficace e affidabile, restituendo un po' di sanità mentale a data engineer, analyst e team C-suite :)
Ha ancora dubbi su come adottare nella sua organizzazione l'approccio descritto per ottenere un data warehousing di successo a livello aziendale?
Si rivolga a noi di DoiT International. Composto esclusivamente da senior engineer, il nostro team è specializzato nell'offrire consulenza cloud avanzata su architetture e debugging — senza alcun costo.
Se desidera approfondire altri temi di architettura dati nel cloud, dia un'occhiata agli altri miei post su Medium e sul blog di DoiT International.