Le scénario qui suit est on ne peut plus courant — et il reste sans solution depuis des décennies. Beaucoup de data engineers, d'analystes métier et de dirigeants pilotés par la donnée le reconnaîtront sans peine :

La confusion est un passage obligé pour toute carrière centrée sur la donnée
Votre organisation se compose de plusieurs équipes/groupes/départements, chacun avec sa propre équipe data qui traite, stocke et produit des rapports sur ses propres jeux de données. La communication entre groupes est minimale. Lorsqu'un accès aux données inter-équipes devient nécessaire, les ingénieurs propriétaires du jeu de données peuvent l'accorder, mais participent rarement aux revues de code pour vérifier que le demandeur interroge correctement les données, ou du moins de manière cohérente avec les requêtes de l'équipe hôte. Même des idées simples peuvent s'avérer délicates à exprimer en SQL. À mesure qu'une organisation grandit et que ses questions gagnent en complexité, valider les requêtes d'une autre équipe devient un goulot d'étranglement chronophage pour la validation du code de traitement de données entre équipes.
Conséquence directe de ce manque de collaboration : les dirigeants qui compilent données et graphiques pour la prise de décision et leurs présentations remarquent parfois que, lorsqu'ils rassemblent des chiffres produits sur des sujets similaires par différents groupes, les graphiques d'un groupe affichent des chiffres très différents de ceux générés par un autre groupe à partir des mêmes données brutes. Les dirigeants constatent alors que les conclusions tirées par un groupe contredisent celles d'un autre.
Lorsqu'ils sollicitent leurs équipes d'ingénierie pour résoudre ces incohérences, les dirigeants trouvent rarement de solutions satisfaisantes. Plusieurs raisons l'expliquent :
- L'ampleur du problème au regard de la taille des équipes. Un seul groupe peut produire des centaines de requêtes, chacune nécessitant validation et correction éventuelle par d'autres groupes. Les ressources humaines et le temps manquent tout simplement pour consacrer autant d'énergie à des revues de code de pipelines de données entre équipes.
- Les jeux de données sous-jacents aux requêtes d'un groupe peuvent être si étrangers à un autre groupe qu'il serait peu rentable, pour ses ingénieurs, d'investir le temps nécessaire à leur compréhension afin de mener un travail de validation inter-équipes. Une seule requête peut être complexe, comporter des centaines de lignes de code et inclure des jointures vers des jeux de données que l'ingénieur en revue n'a pas vraiment besoin de maîtriser hors du contexte de cette revue. Comprendre un tel SQL prend énormément de temps, sauf pour le ou les développeurs d'origine.
Face à ces obstacles, la direction peut choisir d'embaucher un analyste data dédié pour traiter ses requêtes, en lui faisant confiance pour produire des rapports fiables. Mais cette stratégie esquive le problème de fond : différents groupes obtiennent des résultats variés à partir des mêmes données brutes lorsqu'ils explorent des questions similaires ou connexes. Cette incohérence peut conduire à des décisions divergentes au sein d'une même organisation, alors même que les groupes puisent dans les mêmes données brutes. De plus, comme cet analyste de direction doit échanger avec plusieurs groupes pour obtenir leurs jeux de données, il risque de perpétuer les écarts de traitement existants entre les groupes.

Vous connaissez tous l'adage
Dans un monde piloté par la donnée, pouvoir faire pleinement confiance aux données qui guident les décisions est essentiel. Comme le dit le célèbre adage du machine learning :
Garbage (data) in, garbage (predictions) out.
Connecter toutes vos sources de données brutes à un data warehouse de pointe — BigQuery, Snowflake, Redshift, etc. — et y donner accès au cas par cas ne résout pas les problèmes de fond : la cohérence du traitement des données à l'échelle de l'entreprise, le manque général de collaboration inter-équipes et la confiance globale dans les résultats de chaque département.
L'approche segmentée par équipes, classique en matière de data warehousing et d'analytics, fait que peu de requêtes ou de sources de données — voire aucune — sont aisément réutilisables d'une équipe à l'autre. La production de rapports en silo finit par s'enraciner, et chaque groupe ne fait plus confiance qu'à ce que produit sa propre équipe data. La direction se retrouve sans vision cohérente ni assurée de son organisation.

Le logo officiel de Malloy, un langage de requête qui va vous simplifier la vie
Voici Malloy, un langage analytique conçu par les anciens fondateurs et développeurs de Looker / LookML, désormais chez Google.
Pensé pour dépasser les limites de SQL — un langage apparu il y a 44 ans, en 1979, bien avant l'ère des data warehouses — Malloy est, ironie du sort, un compilateur SQL, mais bien plus encore. Construire votre infrastructure de données autour du SQL généré par Malloy plutôt que de demander à vos équipes d'ingénierie un SQL artisanal, écrit à la main, présente plusieurs avantages clés. Avant de les détailler, écoutons directement l'équipe Malloy expliquer pourquoi nous avons besoin d'un successeur à SQL :
Ben Porterfield, cofondateur de Looker et Malloy
SQL est un langage puissant capable d'exprimer n'importe quelle requête, mais il a ses inconvénients :
Tout est exprimable, mais rien n'est réutilisable
Les idées simples sont complexes à exprimer
Le langage est verbeux et manque de valeurs par défaut intelligentes
Malloy est immédiatement compréhensible pour les utilisateurs SQL, et bien plus simple à utiliser et à apprendre [1]
[1] https://malloydata.github.io/documentation/about/features.html
Carlin Eng, Product Manager Malloy
Le langage est un outil de pensée, et améliorer la syntaxe d'un langage a des implications profondes sur ce que nous pouvons imaginer et exprimer. SQL a été inventé dans les années 1970, avant l'existence des data warehouses, et n'a donc pas pu être conçu en tenant compte des cas d'usage actuels.
À l'inverse, Malloy a été pensé spécifiquement pour analyser des jeux de données complexes.
Forts de ces constats, voici les avantages que vous offre le développement avec Malloy plutôt qu'avec SQL :
- Une syntaxe simple et concise pour écrire même les requêtes les plus complexes. Fini d'aligner ligne après ligne de SQL standardisé et de batailler pour collecter, efficacement, des points de données ardus sans recourir massivement à des tables temporaires. La simplicité du langage améliore considérablement :
- Le développement collaboratif
- La vitesse de développement
- La fiabilité des résultats
2. Une base de code modulaire et réutilisable ! Quelques exemples :
- Des sources de données complexes peuvent être définies, puis servir de base à d'autres sources et requêtes. La complexité d'une source peut être réduite en la décomposant en plusieurs sources plus simples organisées en relations parent/enfant.
- Le pipelining des opérations. La sortie d'une requête peut servir d'entrée à une autre.
3. Génération de SQL optimisée pour les performances de dashboard
- Le compilateur SQL est très bien optimisé et surpasse toutes les requêtes complexes écrites à la main auxquelles je l'ai comparé. C'est essentiel, car le temps, c'est de l'argent — au sens littéral. Renseignez-vous sur les grilles tarifaires de BigQuery Editions, Snowflake et Redshift serverless.
4. (Bientôt disponible) Recréation automatisée des tables/vues après mise à jour des sources et requêtes Malloy
- Imaginons que vous disposiez d'une source Malloy définie, que 100 requêtes la sollicitent, et que le SQL généré par chacune crée une table BigQuery. Supposons ensuite que vous découvriez un bug dans le filtrage de la source Malloy et deviez modifier un filtre essentiel. Une fois ce filtre mis à jour, vous pouvez automatiser la recréation des 100 tables BigQuery en demandant au moteur Malloy de relancer toutes les requêtes en aval qui dépendent de cette source amont. Les métadonnées associées à chaque requête indiquent au moteur Malloy quelle table BigQuery doit être recréée.
5. …et bien plus encore !
Passons à un exemple concret pour comprendre comment ces fonctionnalités s'articulent au profit d'une organisation et lui permettent de monter en charge plus efficacement.
Malloy en action : un cas d'usage concret en production
Imaginons que vous travailliez pour une entreprise dotée d'un système de tickets pour le support client. Ce système reçoit des tickets sur des sujets variés, couvrant plusieurs groupes : tickets techniques, tickets commerciaux et tickets financiers. Les équipes ingénierie, commerciale et finance souhaitent donc capturer diverses métriques sur la gestion des tickets, mais chaque groupe ne s'intéresse en général qu'aux métriques liées à son propre périmètre.
Sans Malloy, ce scénario implique typiquement qu'un ingénieur de chaque groupe accède au jeu de données brut du système de tickets et le manipule à sa guise pour produire les métriques et rapports requis. Plusieurs data engineers d'un même groupe peuvent même travailler de manière largement indépendante, en filtrant, joignant et agrégeant les données de façon légèrement différente de leurs collègues.
Cette approche du reporting est regrettable, car de nombreux filtres et cas particuliers sont à prendre en compte, et il est peu probable que tous les data engineers travaillant sur ce jeu de données les découvrent indépendamment. Voici quelques exemples de problèmes à traiter avant de calculer des métriques clés :
- La nécessité d'écarter les tickets de type " spam "
- La nécessité de retirer les tickets " scrubbed " supprimés pour diverses raisons, par exemple parce qu'ils contiennent des données PII
- La nécessité d'exclure les tickets générés en interne, par exemple lors de tests applicatifs
- La nécessité de garantir la reproductibilité entre groupes pour des calculs délicats : temps avant assignation du ticket, temps de première réponse, temps de réponse aux escalades, temps de résolution, temps avant violation de SLO, etc.
- La nécessité de distinguer clairement des dimensions similaires. Par exemple : niveau de priorité initial, actuel, le plus élevé ou le plus bas attribué tout au long de la vie d'un ticket. Lorsqu'un rapport mentionne la priorité d'un ticket, de laquelle parle-t-on ?
- La capacité à extraire, par expressions régulières complexes, des dimensions précieuses depuis certains tickets, sachant que le texte extrait peut prendre plusieurs formats différents.
Avec Malloy, toutes ces préoccupations deviennent presque triviales.
Les ingénieurs travaillant sur ce problème dans une logique transverse pourraient commencer par écrire une source Malloy fondamentale que tous les groupes utiliseront — appelons-la tickets. Pour gérer tous les problèmes mentionnés, la source tickets pourrait ressembler au pseudo-code suivant :
source: tickets is table('bigquery_project.dataset_name.table_name'){ primary_key: id where: spam_ticket = false, scrubbed_ticket = false, internal_test_ticket = false join_one: priority_history on priority_history.ticket_id = id join_one: agents is users on agents.id = assignee_id dimension: priority_original is priority_history.priority_original dimension: priority_highest is priority_history.priority_highest dimension: priority_highest_chartable is priority? pick '1_urgent' when 'urgent' pick '2_high' when 'high' pick '3_normal' when 'normal' pick '4_low' when 'low' else null dimension: priority_current is priority dimension: agent_is_engineer is agents.agent_is_engineer dimension: agent_is_sales is agents.agent_is_sales dimension: agent_is_finance is agents.agent_is_finance dimension: special_request_requester_email is pick coalesce(lower(regexp_extract(description, r'Requested by: (\S+@doit(?:-intl)?\.com)\n')), lower(regexp_extract(subject, r'^(\S+@doit(?:-intl)?\.com) ', 1))) when is_special_request = true else null dimension: time_to_solve_hours is seconds(created_at to solved_at) / 3600 measure: avg_solve_time_hours is round(avg(time_to_solve_hours), 1) measure: ticket_count is count(distinct id)}Le code définissant les sources Malloy que nous joignons à tickets — users et priority_history — n'est pas montré ici, mais il n'est pas nécessaire de le voir pour comprendre comment ces sources sont utilisées. Leur rôle dans la définition de dimensions liées au poste de l'agent et à l'historique de priorité du ticket est limpide. La façon dont ces dimensions, intégrées à la source tickets, sont définies importe peu. C'est toute la beauté d'une base de code qui tire parti de la nature modulaire de Malloy.
Avec cette source fondamentale en place (elle-même reposant sur des jointures avec deux autres sources), vous pouvez ensuite créer plusieurs sources enfants dépendantes de la source tickets, chacune dédiée à un groupe départemental :
source: engineering_tickets is tickets { where: agent_is_engineer = true}source: sales_tickets is tickets { where: agent_is_sales = true}source: finance_tickets is tickets { where: agent_is_finance = true}Maintenant que nous disposons d'une source Malloy spécifiquement adaptée à chaque département, dans laquelle filtres complexes, dimensions et cas particuliers sont déjà pris en charge en coulisses, les ingénieurs de chaque groupe peuvent interroger les tickets en toute confiance : leurs métriques (les tickets pris en compte et les calculs sous-jacents) seront cohérentes d'un groupe à l'autre. Notez que l'algorithme derrière la métrique avg_solve_time_hours est défini dans la source tickets, mais invoqué via la commande aggregate dans les sources enfants :
query: avg_solve_time_engineering is engineering_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_sales is sales_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_finance is finance_tickets -> { aggregate: avg_solve_time_hours}Imaginons que chaque équipe veuille aussi savoir combien de tickets ont été générés dans son département au cours des trois derniers mois et qu'à un moment de leur historique, ils aient été classés urgents/P1 :
query: tickets_past_3_months_engineering is engineering_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_sales is sales_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_finance is finance_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}De telles requêtes Malloy — étonnamment lisibles grâce à la nature modulaire du langage — peuvent compiler vers des centaines de lignes de SQL, selon le nombre de dépendances de sources parents, jointures, filtres et agrégations présents dans chacune des sources dont dépend votre requête.
Ce SQL s'exécutera bien plus vite — et de façon bien plus économique — que tout équivalent écrit à la main.
Cette alternative modulaire au SQL implique aussi que, lorsqu'un bug est détecté dans une requête, il suffit de remonter une chaîne de sources amont, lisibles et de complexité raisonnable, pour finir par identifier et corriger le problème. Une fois le correctif apporté, toutes les requêtes — et les tables/vues qu'elles alimentent — dépendant de cette source mise à jour peuvent être rapidement relancées et reconstruites.
Les corrections apportées par un groupe peuvent ainsi être intégrées sans heurt et rapidement aux travaux des autres groupes qui s'appuient sur les mêmes sources Malloy.
Jusqu'où le code Malloy peut-il aller en clarté et en concision ?
Les exemples de sources et de requêtes Malloy ci-dessus illustrent bien sa nature modulaire, mais ne lui rendent pas justice quant à la clarté qu'il offre face à des questions complexes.
Examinons la source priority_history, qui, comme nous l'avons vu, se joint à la source tickets pour fournir les dimensions retraçant l'historique de priorité d'un ticket : priorité initiale, priorité actuelle et priorité historiquement la plus élevée.
Déterminer ces priorités exige de parcourir l'historique des changements appliqués à un ticket, ce qui requiert une requête comportant plusieurs sous-requêtes imbriquées. Les requêtes imbriquées en SQL sont disgracieuses ; en Malloy, elles sont propres et faciles à lire. Comparons la définition de priority_history dans chaque langage, en commençant par Malloy :
source: priority_history is from(field_history{where: field_name = 'priority'} -> { group_by: ticket_id nest: priority_original is { group_by: priority_original is value, updated order_by: updated asc limit: 1 } nest: priority_final is { group_by: priority_final is value, updated order_by: updated desc limit: 1 } nest: priority_urgent_present is { group_by: priority_urgent_present is true where: value = 'urgent' limit: 1 } nest: priority_high_present is { group_by: priority_high_present is true where: value = 'high' limit: 1 } nest: priority_normal_present is { group_by: priority_normal_present is true where: value = 'normal' limit: 1 } nest: priority_low_present is { group_by: priority_low_present is true where: value = 'low' limit: 1 }} -> { project: ticket_id, priority_original.priority_original, priority_final.priority_final, priority_highest is pick 'urgent' when priority_urgent_present.priority_urgent_present = true pick 'high' when priority_high_present.priority_high_present = true pick 'normal' when priority_normal_present.priority_normal_present = true pick 'low' when priority_low_present.priority_low_present = true else null order_by: ticket_id desc})Comparez cela au SQL optimisé pour le dashboard qu'il génère :
WITH __stage0 AS ( SELECT group_set, CASE WHEN group_set IN (0,1,2,3,4,5,6) THEN field_history.ticket_id END as ticket_id__0, CASE WHEN group_set=1 THEN field_history.value END as priority_original__1, CASE WHEN group_set=1 THEN field_history.updated END as updated__1, CASE WHEN group_set=2 THEN field_history.value END as priority_final__2, CASE WHEN group_set=2 THEN field_history.updated END as updated__2, CASE WHEN group_set=3 THEN true END as priority_urgent_present__3, CASE WHEN group_set=4 THEN true END as priority_high_present__4, CASE WHEN group_set=5 THEN true END as priority_normal_present__5, CASE WHEN group_set=6 THEN true END as priority_low_present__6 FROM `project-name.dataset-name.table-name` as field_history CROSS JOIN (SELECT row_number() OVER() -1 group_set FROM UNNEST(GENERATE_ARRAY(0,6,1))) WHERE (field_history.field_name='priority') AND ((group_set NOT IN (3) OR (group_set IN (3) AND field_history.value='urgent'))) AND ((group_set NOT IN (4) OR (group_set IN (4) AND field_history.value='high'))) AND ((group_set NOT IN (5) OR (group_set IN (5) AND field_history.value='normal'))) AND ((group_set NOT IN (6) OR (group_set IN (6) AND field_history.value='low'))) GROUP BY 1,2,3,4,5,6,7,8,9,10), __stage1 AS ( SELECT ticket_id__0 as ticket_id, ARRAY_AGG(CASE WHEN group_set=1 THEN STRUCT( priority_original__1 as priority_original, updated__1 as updated ) END IGNORE NULLS ORDER BY updated__1 asc LIMIT 1) as priority_original, ARRAY_AGG(CASE WHEN group_set=2 THEN STRUCT( priority_final__2 as priority_final, updated__2 as updated ) END IGNORE NULLS ORDER BY updated__2 desc LIMIT 1) as priority_final, ARRAY_AGG(CASE WHEN group_set=3 THEN STRUCT( priority_urgent_present__3 as priority_urgent_present ) END IGNORE NULLS ORDER BY priority_urgent_present__3 asc LIMIT 1) as priority_urgent_present, ARRAY_AGG(CASE WHEN group_set=4 THEN STRUCT( priority_high_present__4 as priority_high_present ) END IGNORE NULLS ORDER BY priority_high_present__4 asc LIMIT 1) as priority_high_present, ARRAY_AGG(CASE WHEN group_set=5 THEN STRUCT( priority_normal_present__5 as priority_normal_present ) END IGNORE NULLS ORDER BY priority_normal_present__5 asc LIMIT 1) as priority_normal_present, ARRAY_AGG(CASE WHEN group_set=6 THEN STRUCT( priority_low_present__6 as priority_low_present ) END IGNORE NULLS ORDER BY priority_low_present__6 asc LIMIT 1) as priority_low_present FROM __stage0 GROUP BY 1 ORDER BY 1 asc), __stage2 AS ( SELECT base.ticket_id as ticket_id, priority_original_0.priority_original as priority_original, priority_final_0.priority_final as priority_final, CASE WHEN priority_urgent_present_0.priority_urgent_present=true THEN 'urgent' WHEN priority_high_present_0.priority_high_present=true THEN 'high' WHEN priority_normal_present_0.priority_normal_present=true THEN 'normal' WHEN priority_low_present_0.priority_low_present=true THEN 'low' ELSE NULL END as priority_highest FROM __stage1 as base LEFT JOIN UNNEST(base.priority_urgent_present) as priority_urgent_present_0 LEFT JOIN UNNEST(base.priority_high_present) as priority_high_present_0 LEFT JOIN UNNEST(base.priority_normal_present) as priority_normal_present_0 LEFT JOIN UNNEST(base.priority_low_present) as priority_low_present_0 LEFT JOIN UNNEST(base.priority_original) as priority_original_0 LEFT JOIN UNNEST(base.priority_final) as priority_final_0 ORDER BY 1 desc)SELECT priority_history.ticket_id as ticket_id, priority_history.priority_original as priority_original, priority_history.priority_final as priority_final, priority_history.priority_highest as priority_highestFROM __stage2 as priority_historyLequel de ces deux exemples préféreriez-vous déboguer ?
N'oubliez pas que tickets_history n'est qu'une parmi de nombreuses sources Malloy jointes à la source tickets pour que ses dimensions puissent servir à l'analyse des tickets ; elle ne représente donc qu'une infime partie de la complexité qui sous-tend le SQL de la source tickets. Imaginez la complexité requise pour écrire et déboguer le SQL de tickets si vous y joigniez 20 sources Malloy en exploitant les dimensions/mesures de chacune, comme je l'ai fait.
Malloy + Looker : efficace, scalable, collaboratif. La data engineering de confiance, enfin une réalité.

" Le tout est plus grand que la somme de ses parties " — Aristote
Les exemples décrits ci-dessus ne sont pas fictifs : ils reflètent la démarche data collaborative que j'ai initiée chez DoiT International. J'ai cherché à unifier l'exploration de plusieurs systèmes de données (tickets, ventes, utilisateurs, employés, etc.) au sein d'un cadre qui maximise la confiance que la direction peut accorder aux analyses produites à partir de ces jeux de données et minimise l'effort d'embarquement nécessaire à mes collègues data engineers pour y contribuer.
Si Malloy est un outil formidable qui enrichit incontestablement ce parcours vers une analytics collaborative, le langage seul ne suffit pas à offrir la simplicité d'usage attendue par les utilisateurs finaux qui veulent générer rapidement des rapports et n'ont pas envie d'apprendre un nouveau langage (à savoir la direction et le top management). Pour y répondre, j'ai découvert que Malloy révèle tout son potentiel quand il est associé à des outils de dashboard de pointe, comme Looker.
Comparé à d'autres outils BI, Looker est conçu pour servir de source de vérité centralisée. Bien paramétré via des définitions de dimensions et de mesures écrites dans son langage propriétaire LookML, il permet d'apprendre — même à des profils non techniques — la création intuitive de graphiques sur à peu près tout ce qu'on peut imaginer, en quelques minutes seulement. Les utilisateurs n'ont qu'à cliquer sur les dimensions et mesures qu'ils souhaitent voir (lesquelles peuvent éventuellement couvrir plusieurs tables), à effectuer quelques clics supplémentaires pour ajouter des filtres ou pivoter sur une dimension, puis à appuyer sur Run. Une fois familiarisé avec l'interface Explore de Looker, générer un graphique couvrant plusieurs sources de données prend quelques secondes.
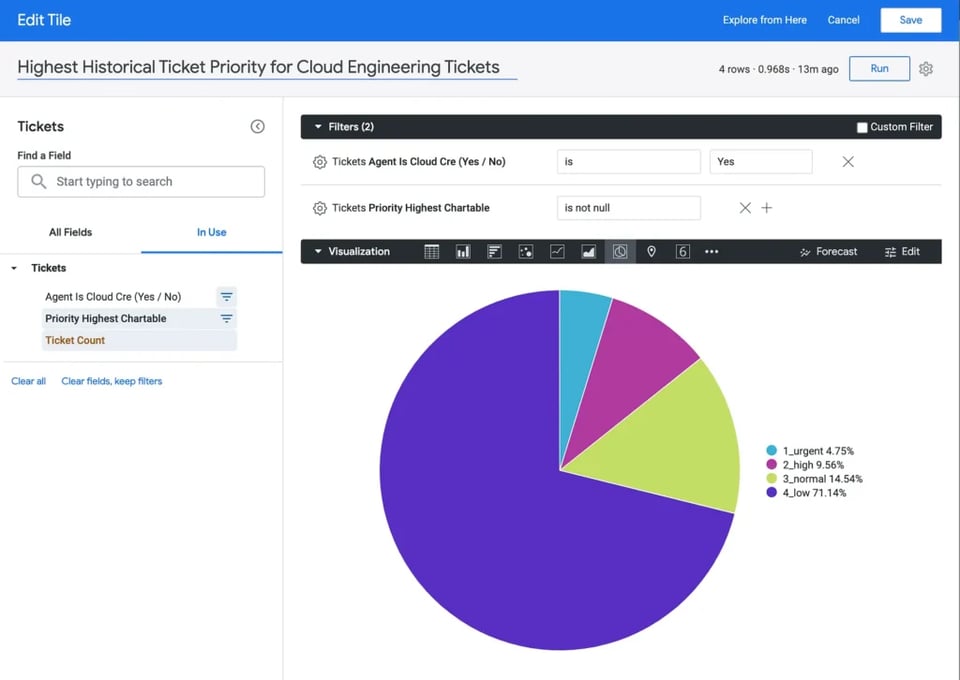
Plongeons directement dans un autre exemple. Supposons qu'un dirigeant souhaite comprendre la part que représente chaque priorité de ticket dans le total des tickets attribués à l'équipe ingénierie. Plus précisément, il veut identifier le niveau de priorité le plus élevé qu'un ticket a atteint à un moment de son cycle de vie pris en charge par les ingénieurs.
En supposant que le SQL issu de la source tickets ci-dessus ait été mis à disposition dans Looker, un utilisateur final n'aurait qu'à effectuer les actions suivantes pour répondre à cette question :
- Choisir le jeu de données " Tickets " dans Looker
- Cliquer sur la dimension " Priority Highest Chartable "
- Cliquer sur la mesure " Ticket Count "
- Ajouter un filtre sur la dimension " Agent is Cloud Cre Is Yes "
- Cliquer sur la visualisation Pie Chart et appuyer sur Run
Notez le temps d'exécution dans le coin supérieur droit. Grâce à l'utilisation d'une table de données créée à partir de SQL généré par Malloy, la requête s'est exécutée en moins d'une seconde :
Combinez la simplicité d'usage de Looker pour les utilisateurs finaux avec ses autres atouts modernes — système de contrôle de version permettant le déploiement de dashboards en dev/prod, paramètres de sécurité avancés autorisant des permissions IAM finement ajustées sur les dashboards et leurs dossiers — et il devient évident que c'est l'outil idéal pour visualiser des sources de données définies en code Malloy.
La cohérence des données est essentielle
Lorsque vous intégrez du SQL généré par Malloy dans Looker ou dans l'outil de dashboard de votre choix, gardez bien une chose en tête. La clé pour bâtir un data warehouse fiable et accessible, c'est :
Ne donnez pas accès aux données brutes à vos utilisateurs finaux qui produisent des rapports !
L'accès aux données brutes est la cause profonde des données divergentes et contradictoires qui alimentent les rapports créés par différents groupes et départements. En effet, les ingénieurs de chaque groupe — et souvent plusieurs au sein d'un même groupe — adoptent inévitablement leurs propres méthodes pour filtrer, joindre et agréger l'information.
À la place, ne présentez aux concepteurs de rapports, comme les utilisateurs finaux de Looker, que des tables adossées à des sources Malloy. Idéalement, les sources Malloy (et dans une certaine mesure LookML) auront déjà géré tous les cas particuliers courants, les filtres, ainsi que les jointures complexes et les définitions de dimensions et d'agrégations. Il est peu probable qu'un concepteur de rapports individuel traite correctement toutes ces complexités, et encore moins qu'elles soient répliquées de manière cohérente sur plusieurs groupes d'analystes.
Avec un ensemble de sources Malloy bien validées et conçues collaborativement, présentées comme la seule base disponible dans Looker, vous garantissez non seulement que vos analyses s'appuient sur des données de la plus haute qualité, mais aussi que, lorsque des utilisateurs de différents groupes construisent des graphiques, leurs chiffres correspondront — ou s'aligneront étroitement — sur ceux produits par les graphiques d'autres groupes. Il est essentiel de gérer un maximum de complexité de données en coulisses, avant qu'elle n'atteigne les utilisateurs finaux.
Limitations actuelles
Si l'utilisation conjointe de Malloy et Looker pour concevoir un data warehouse et un système de reporting scalables, fiables et développés collaborativement fonctionne très bien chez DoiT, elle comporte quelques limitations (temporaires). À savoir :
- Malloy est un nouveau langage de programmation encore aux premiers stades de son développement. Bien que je le considère stable dans mon usage quotidien, vous pouvez encore rencontrer des bugs sur des cas particuliers. Les fonctionnalités les plus récentes se trouvent souvent sur le canal de pré-publication du plugin VSCode. Cela dit, les développeurs de Malloy présents sur le canal Slack Malloy sont d'une grande aide et répondent généralement le jour même aux signalements de bugs, demandes de fonctionnalités et sollicitations de débogage.
- Si Malloy prend en charge BigQuery, Postgres et DuckDB (et, par extension, les formats CSV/TSV/Parquet et les objets stockés dans des buckets), il ne prend pas encore en charge d'autres plateformes de data warehousing comme Redshift et Snowflake. Néanmoins, à mesure que ce projet open source mûrira, on imagine difficilement que, fidèle à sa mission de langage " purpose-built for analyzing complex datasets ", il ne finisse pas par couvrir les solutions de data warehousing les plus populaires.
- LookML, le langage qui propulse Looker, est un langage propriétaire qui crée des barrières d'adoption substantielles dues, selon moi, à une documentation médiocre, à un manque de supports d'apprentissage axés sur des tutoriels pas-à-pas, et à une tarification entreprise du type " Contactez le service commercial pour en savoir plus ". Même sans Looker, Malloy peut servir de socle solide à des outils BI moins orientés utilisateurs finaux mais plus économiques, comme Looker Studio.
Concevoir avec succès un data warehouse et un système de reporting scalables et collaboratifs
Bonne chance dans l'intégration réussie de Malloy et Looker pour bâtir une fondation data qui permettra à chaque échelon de votre organisation d'opérer plus efficacement et plus sûrement, et qui rendra un peu de sérénité à vos data engineers, analystes et équipes dirigeantes :)
Vous avez encore des questions sur la mise en œuvre de cette approche dans votre organisation pour réussir votre data warehousing à l'échelle de l'entreprise ?
Contactez-nous chez DoiT International. Composée exclusivement de talents senior en ingénierie, notre équipe est spécialisée dans le conseil cloud avancé, la conception architecturale et l'aide au débogage — sans aucun frais.
Si vous souhaitez approfondir d'autres sujets d'architecture cloud data, jetez un œil à mes autres articles sur Medium ainsi qu'au blog DoiT International.