El siguiente es un escenario demasiado común —uno que lleva décadas sin solución— y que probablemente le resulte familiar a muchos data engineers, analistas de negocio y ejecutivos orientados a los datos:

La confusión es un momento inevitable en cualquier carrera centrada en datos
Tu organización tiene varios equipos/grupos/departamentos, y cada uno cuenta con su propio equipo de datos que procesa, almacena y genera reportes sobre sus propios datasets. La comunicación entre grupos es mínima. Cuando se necesita acceso cruzado a datos, los engineers responsables del dataset pueden otorgar acceso bajo demanda, pero rara vez participan en revisiones de código para verificar que quien solicita esté consultando los datos correctamente, o al menos de una manera consistente con las consultas del equipo dueño. Incluso ideas simples pueden ser difíciles de expresar en SQL, así que, a medida que la organización crece y sus preguntas se vuelven más complejas, validar consultas de otro equipo se convierte en un cuello de botella que consume mucho tiempo en la validación de código de procesamiento de datos entre equipos.
Como resultado de esta colaboración mínima, los ejecutivos que recopilan datos y gráficos para tomar decisiones y armar presentaciones a veces notan que, al consultar cifras sobre temas similares en distintos grupos, los gráficos de un grupo pueden mostrar números sustancialmente diferentes a los de otro grupo, aun usando los mismos datos crudos como base. Así, los ejecutivos pueden notar que las conclusiones de un grupo contradicen las de otro.
Cuando los ejecutivos buscan soluciones a esta inconsistencia con sus equipos de Engineering, suelen encontrar pocas alternativas. Las razones pueden incluir:
- La magnitud del problema en relación con el tamaño del grupo. Cientos de consultas pueden venir de un solo grupo, y cada una requiere validación y posibles correcciones por parte de otros grupos. Simplemente no hay suficiente personal ni tiempo para dedicarse a revisiones de código de pipelines de datos entre equipos.
- Los datasets que sustentan las consultas de un grupo pueden ser tan irrelevantes para otro grupo que no valdría la pena que los engineers de ese otro grupo los aprendieran solo para participar correctamente en validaciones cruzadas. Una sola consulta puede ser compleja, tener cientos de líneas de código e incluir joins con datasets que el engineer revisor no necesita comprender más allá del contexto de la revisión. Entender ese SQL consume mucho tiempo a cualquiera que no sea el desarrollador original.
Frente a estos obstáculos, los líderes pueden optar por contratar a un analista de datos que se encargue de sus consultas, depositando su confianza en esta persona para entregar reportes confiables. Sin embargo, esta estrategia esquiva el problema de fondo: distintos grupos llegan a resultados distintos a partir de los mismos datos crudos cuando exploran preguntas similares o conectadas. Esta inconsistencia puede llevar a decisiones basadas en datos divergentes dentro de una misma organización, incluso cuando los grupos parten del mismo origen. Más aún, como ese analista de liderazgo debe comunicarse con varios grupos para obtener sus datasets, lo más probable es que termine perpetuando las discrepancias existentes en el procesamiento de datos entre grupos.

Todos hemos escuchado el dicho antes
En un mundo basado en datos, poder confiar plenamente en los datos que guían la toma de decisiones lo es todo. Como dice el refrán del machine learning:
Basura (datos) entra, basura (predicciones) sale.
Conectar todas tus fuentes de datos crudos a un data warehouse de última generación —BigQuery, Snowflake, Redshift, etc.— y otorgar acceso a esos datos según se necesite no resuelve los problemas de fondo: el procesamiento consistente de datos a nivel de toda la empresa, la falta general de colaboración entre equipos y la confiabilidad colectiva de los resultados en cada departamento.
Adoptar el enfoque típico de equipos segmentados para data warehousing y analítica significa que pocas —si acaso alguna— de las consultas y fuentes de datos de un equipo serán fácilmente reutilizables por otro. La generación de reportes en silos termina por arraigarse, y los grupos acaban confiando solo en lo que produce su propio equipo de datos. El liderazgo se queda sin una visión confiable y consistente de su organización.

El logo oficial de Malloy, un lenguaje de consulta que te hará la vida mucho más fácil
Aquí entra Malloy, un lenguaje analítico creado por los ex fundadores y desarrolladores de Looker / LookML, hoy trabajando dentro de Google.
Diseñado para superar las limitaciones de SQL —un lenguaje que se lanzó hace 44 años, en 1979, mucho antes de que existieran los data warehouses—, Malloy es, en esencia irónica, un compilador de SQL, pero es mucho más que eso. Hay varias ventajas clave en construir tu infraestructura de datos pensando en SQL generado por Malloy en lugar de pedirle a tus equipos de Engineering SQL artesanal hecho a mano. Antes de entrar en esas ventajas, escuchemos directamente al equipo de Malloy explicar por qué necesitamos siquiera un reemplazo para SQL:
Por Ben Porterfield, cofundador de Looker y Malloy
SQL es un lenguaje poderoso, capaz de expresar cualquier consulta posible, pero tiene sus desventajas:
Todo se puede expresar, pero nada se puede reutilizar
Las ideas simples son complejas de expresar
El lenguaje es verboso y carece de defaults inteligentes
Malloy es comprensible de inmediato para usuarios de SQL, y mucho más fácil de usar y aprender [1]
[1] https://malloydata.github.io/documentation/about/features.html
Por Carlin Eng, Product Manager de Malloy
El lenguaje es una herramienta para el pensamiento, y mejorar la sintaxis de un lenguaje tiene implicaciones profundas en lo que podemos imaginar y expresar. SQL fue inventado en los años 70, antes de que existieran los data warehouses, así que no pudo haberse diseñado pensando en los casos de uso actuales.
En contraste, Malloy fue creado específicamente para analizar datasets complejos.
Con esto en mente, desarrollar con Malloy en lugar de SQL te ofrece las siguientes ventajas:
- Una sintaxis simple y concisa para escribir incluso las consultas más complejas. Quedaron atrás los días de escribir línea tras línea de SQL repetitivo y de luchar para reunir puntos de datos difíciles sin un uso excesivo de tablas temporales. La simplicidad del lenguaje mejora notablemente:
- El desarrollo colaborativo
- La velocidad de desarrollo
- La confiabilidad de los resultados
2. ¡Una base de código modular y reutilizable! Algunos ejemplos:
- Las fuentes de datos complejas se pueden definir y luego usar como base para otras fuentes y consultas. La complejidad de una fuente de datos se puede minimizar dividiéndola en varias fuentes más simples con relaciones de tipo padre-hijo.
- Encadenamiento (pipelining) de operaciones. La salida de una consulta puede ser la entrada de otra.
3. Generación de SQL optimizado para el rendimiento del dashboard
- El compilador de SQL está bien optimizado y supera a todas las consultas complejas escritas a mano contra las que he comparado su rendimiento. Esto importa porque el tiempo es dinero, literalmente. Mira los esquemas de precios de BigQuery Editions, Snowflake y Redshift serverless.
4. (Próximamente) Recreación automatizada de tablas / vistas tras actualizar las fuentes y consultas de Malloy
- Supongamos que tienes una fuente de Malloy definida, 100 consultas la golpean y el SQL generado por cada consulta crea una tabla de BigQuery. Imagina ahora que descubres un bug en cómo se filtra la fuente de Malloy y necesitas hacer un cambio crucial en su filtro. Tras actualizar el filtro de la fuente, puedes automatizar la recreación de las 100 tablas de BigQuery haciendo que el motor de Malloy vuelva a ejecutar todas las consultas dependientes de esa fuente. Los metadatos asociados a cada consulta le indican al motor de Malloy qué tabla de BigQuery debe recrear cada consulta.
5. …y mucho más.
Veamos un ejemplo práctico para entender cómo todas estas funcionalidades se combinan para beneficiar a una organización y permitirle operar a gran escala con mayor eficacia.
Malloy en acción: un caso de uso real en producción
Supongamos que trabajas para una empresa con un sistema de tickets de soporte al cliente. A través de este sistema se registran tickets sobre temas que abarcan varios grupos: tickets técnicos, tickets de interacción comercial y tickets financieros. Así, los equipos de Engineering, ventas y finanzas se interesan por capturar diversas métricas relacionadas con cómo se manejan los tickets, pero cada grupo en general solo se preocupa por las métricas de su propio grupo.
Sin Malloy, este escenario suele significar que un engineer de cada grupo obtiene acceso al dataset crudo del sistema de tickets y manipula los datos a su criterio para generar las métricas y reportes requeridos. Incluso pueden coexistir varios data engineers dentro de un mismo grupo trabajando de forma mayormente independiente, filtrando, haciendo joins y agregando datos de maneras ligeramente distintas a las de sus propios compañeros.
Este enfoque al reporting es desafortunado, ya que hay muchos filtros y casos límite difíciles de tener en cuenta, y es poco probable que todos los data engineers que trabajan con este dataset los descubran de forma independiente. Algunos ejemplos de cuestiones que deben resolverse antes de calcular métricas clave:
- La necesidad de excluir tickets tipo "spam" del análisis
- La necesidad de excluir tickets "depurados" eliminados por diversas razones, p. ej. por contener datos PII
- La necesidad de excluir tickets generados internamente, p. ej. por pruebas de la app
- La necesidad de reproducibilidad entre grupos para cálculos complejos, como: tiempo hasta la asignación del ticket, tiempo de primera respuesta, tiempo de respuesta de escalamiento, tiempo de resolución, tiempo de incumplimiento de SLO, etc.
- La necesidad de diferenciar claramente dimensiones similares. Por ejemplo: nivel de prioridad original vs. actual vs. más alto vs. más bajo asignado a lo largo de la historia del ticket. Cuando un reporte habla de "prioridad del ticket", ¿a cuál de estas se refiere?
- La capacidad de capturar dimensiones valiosas extraídas de ciertos tickets mediante expresiones regulares complejas, donde el texto extraído puede tener varios formatos distintos.
Con Malloy, todas estas preocupaciones empiezan a volverse triviales.
Los engineers que aborden este problema pensando en una funcionalidad transversal entre departamentos podrían comenzar escribiendo una fuente fundacional de Malloy que todos los grupos usarán; la llamaremos tickets. Para resolver todos los problemas mencionados, la fuente tickets podría parecerse al siguiente pseudocódigo:
source: tickets is table('bigquery_project.dataset_name.table_name'){ primary_key: id where: spam_ticket = false, scrubbed_ticket = false, internal_test_ticket = false join_one: priority_history on priority_history.ticket_id = id join_one: agents is users on agents.id = assignee_id dimension: priority_original is priority_history.priority_original dimension: priority_highest is priority_history.priority_highest dimension: priority_highest_chartable is priority? pick '1_urgent' when 'urgent' pick '2_high' when 'high' pick '3_normal' when 'normal' pick '4_low' when 'low' else null dimension: priority_current is priority dimension: agent_is_engineer is agents.agent_is_engineer dimension: agent_is_sales is agents.agent_is_sales dimension: agent_is_finance is agents.agent_is_finance dimension: special_request_requester_email is pick coalesce(lower(regexp_extract(description, r'Requested by: (\S+@doit(?:-intl)?\.com)\n')), lower(regexp_extract(subject, r'^(\S+@doit(?:-intl)?\.com) ', 1))) when is_special_request = true else null dimension: time_to_solve_hours is seconds(created_at to solved_at) / 3600 measure: avg_solve_time_hours is round(avg(time_to_solve_hours), 1) measure: ticket_count is count(distinct id)}El código que define las fuentes de Malloy a las que hacemos join con tickets —users y priority_history— no se muestra, pero no necesitamos verlo para entender cómo se usan esas fuentes. Su uso para definir dimensiones relacionadas con el rol del agente y la historia de prioridad del ticket es claro. Cómo se definen esas dimensiones que se incorporan a la fuente tickets es, en gran medida, irrelevante. Esa es la belleza de una base de código que aprovecha la naturaleza modular de Malloy.
Con esta fuente fundacional ya en su lugar (que a su vez depende de joins con otras dos fuentes), puedes crear varias fuentes hijas dependientes de la fuente tickets, cada una específica para un grupo departamental:
source: engineering_tickets is tickets { where: agent_is_engineer = true}source: sales_tickets is tickets { where: agent_is_sales = true}source: finance_tickets is tickets { where: agent_is_finance = true}Ahora que tenemos una fuente de Malloy adaptada específicamente para cada departamento, donde múltiples filtros complejos, dimensiones y casos límite se han manejado bajo el capó, los engineers de cada grupo pueden hacer consultas sobre los tickets y confiar en que la forma en que se calculan sus métricas (por ejemplo, los tickets considerados y la fórmula detrás del cálculo de la métrica) coincidirá entre grupos. Observa que el algoritmo detrás de la métrica avg_solve_time_hours se define en la fuente tickets y, sin embargo, se invoca a través del comando aggregate en las fuentes hijas:
query: avg_solve_time_engineering is engineering_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_sales is sales_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_finance is finance_tickets -> { aggregate: avg_solve_time_hours}Supongamos que cada equipo también quiere saber cuántos tickets se generaron en su departamento durante los últimos tres meses, donde en algún momento de la historia del ticket fue una incidencia urgente/P1:
query: tickets_past_3_months_engineering is engineering_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_sales is sales_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_finance is finance_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}Consultas en Malloy como estas —sorprendentemente fáciles de leer gracias a la naturaleza modular del lenguaje— pueden compilarse en cientos de líneas de SQL dependiendo de cuántas dependencias de fuentes padre, joins, filtros y agregaciones existan dentro de cada una de las fuentes de las que depende tu consulta.
Ese SQL se ejecutará mucho más rápido —y con mejor costo-beneficio— que cualquier equivalente escrito a mano.
Esta alternativa modular a SQL también significa que, si se descubre un bug en una consulta, basta con recorrer una serie de fuentes upstream, fáciles de leer y de complejidad relativamente baja, hasta encontrar y corregir el error. Luego, una vez corregido, todas las consultas —y las tablas/vistas de la base de datos que estas alimentan— dependientes de la fuente actualizada pueden volver a ejecutarse y reconstruirse rápidamente.
Las correcciones de bugs de un grupo se integran así de forma fluida y rápida al trabajo de otros grupos que se apoyan en las mismas fuentes de datos de Malloy.
¿Qué tan claro y conciso puede llegar a ser realmente el código de Malloy?
Los ejemplos anteriores de fuentes y consultas de Malloy ilustran bien la naturaleza modular del lenguaje, pero no le hacen justicia en cuanto a mostrar lo claro que puede ser al plantear preguntas complejas.
Veamos la fuente priority_history que, como vimos arriba, hace join con la fuente tickets para aportar dimensiones que destacan el historial de prioridad de un ticket: original, actual y la prioridad históricamente más alta del ticket.
Determinar estas prioridades exige rastrear el historial de cambios hechos a un ticket, lo que requiere una consulta con múltiples consultas anidadas. Las consultas anidadas en SQL son feas; en Malloy son limpias y fáciles de leer. Comparemos cómo se define priority_history en cada lenguaje, empezando por Malloy:
source: priority_history is from(field_history{where: field_name = 'priority'} -> { group_by: ticket_id nest: priority_original is { group_by: priority_original is value, updated order_by: updated asc limit: 1 } nest: priority_final is { group_by: priority_final is value, updated order_by: updated desc limit: 1 } nest: priority_urgent_present is { group_by: priority_urgent_present is true where: value = 'urgent' limit: 1 } nest: priority_high_present is { group_by: priority_high_present is true where: value = 'high' limit: 1 } nest: priority_normal_present is { group_by: priority_normal_present is true where: value = 'normal' limit: 1 } nest: priority_low_present is { group_by: priority_low_present is true where: value = 'low' limit: 1 }} -> { project: ticket_id, priority_original.priority_original, priority_final.priority_final, priority_highest is pick 'urgent' when priority_urgent_present.priority_urgent_present = true pick 'high' when priority_high_present.priority_high_present = true pick 'normal' when priority_normal_present.priority_normal_present = true pick 'low' when priority_low_present.priority_low_present = true else null order_by: ticket_id desc})Compáralo con el SQL optimizado para dashboard que genera:
WITH __stage0 AS ( SELECT group_set, CASE WHEN group_set IN (0,1,2,3,4,5,6) THEN field_history.ticket_id END as ticket_id__0, CASE WHEN group_set=1 THEN field_history.value END as priority_original__1, CASE WHEN group_set=1 THEN field_history.updated END as updated__1, CASE WHEN group_set=2 THEN field_history.value END as priority_final__2, CASE WHEN group_set=2 THEN field_history.updated END as updated__2, CASE WHEN group_set=3 THEN true END as priority_urgent_present__3, CASE WHEN group_set=4 THEN true END as priority_high_present__4, CASE WHEN group_set=5 THEN true END as priority_normal_present__5, CASE WHEN group_set=6 THEN true END as priority_low_present__6 FROM `project-name.dataset-name.table-name` as field_history CROSS JOIN (SELECT row_number() OVER() -1 group_set FROM UNNEST(GENERATE_ARRAY(0,6,1))) WHERE (field_history.field_name='priority') AND ((group_set NOT IN (3) OR (group_set IN (3) AND field_history.value='urgent'))) AND ((group_set NOT IN (4) OR (group_set IN (4) AND field_history.value='high'))) AND ((group_set NOT IN (5) OR (group_set IN (5) AND field_history.value='normal'))) AND ((group_set NOT IN (6) OR (group_set IN (6) AND field_history.value='low'))) GROUP BY 1,2,3,4,5,6,7,8,9,10), __stage1 AS ( SELECT ticket_id__0 as ticket_id, ARRAY_AGG(CASE WHEN group_set=1 THEN STRUCT( priority_original__1 as priority_original, updated__1 as updated ) END IGNORE NULLS ORDER BY updated__1 asc LIMIT 1) as priority_original, ARRAY_AGG(CASE WHEN group_set=2 THEN STRUCT( priority_final__2 as priority_final, updated__2 as updated ) END IGNORE NULLS ORDER BY updated__2 desc LIMIT 1) as priority_final, ARRAY_AGG(CASE WHEN group_set=3 THEN STRUCT( priority_urgent_present__3 as priority_urgent_present ) END IGNORE NULLS ORDER BY priority_urgent_present__3 asc LIMIT 1) as priority_urgent_present, ARRAY_AGG(CASE WHEN group_set=4 THEN STRUCT( priority_high_present__4 as priority_high_present ) END IGNORE NULLS ORDER BY priority_high_present__4 asc LIMIT 1) as priority_high_present, ARRAY_AGG(CASE WHEN group_set=5 THEN STRUCT( priority_normal_present__5 as priority_normal_present ) END IGNORE NULLS ORDER BY priority_normal_present__5 asc LIMIT 1) as priority_normal_present, ARRAY_AGG(CASE WHEN group_set=6 THEN STRUCT( priority_low_present__6 as priority_low_present ) END IGNORE NULLS ORDER BY priority_low_present__6 asc LIMIT 1) as priority_low_present FROM __stage0 GROUP BY 1 ORDER BY 1 asc), __stage2 AS ( SELECT base.ticket_id as ticket_id, priority_original_0.priority_original as priority_original, priority_final_0.priority_final as priority_final, CASE WHEN priority_urgent_present_0.priority_urgent_present=true THEN 'urgent' WHEN priority_high_present_0.priority_high_present=true THEN 'high' WHEN priority_normal_present_0.priority_normal_present=true THEN 'normal' WHEN priority_low_present_0.priority_low_present=true THEN 'low' ELSE NULL END as priority_highest FROM __stage1 as base LEFT JOIN UNNEST(base.priority_urgent_present) as priority_urgent_present_0 LEFT JOIN UNNEST(base.priority_high_present) as priority_high_present_0 LEFT JOIN UNNEST(base.priority_normal_present) as priority_normal_present_0 LEFT JOIN UNNEST(base.priority_low_present) as priority_low_present_0 LEFT JOIN UNNEST(base.priority_original) as priority_original_0 LEFT JOIN UNNEST(base.priority_final) as priority_final_0 ORDER BY 1 desc)SELECT priority_history.ticket_id as ticket_id, priority_history.priority_original as priority_original, priority_history.priority_final as priority_final, priority_history.priority_highest as priority_highestFROM __stage2 as priority_history¿Cuál de esos ejemplos preferirías depurar?
Recuerda que tickets_history es solo una de las muchas fuentes de Malloy que se unen mediante join a la fuente tickets para que sus dimensiones puedan usarse en la analítica de tickets, y representa apenas una pequeña porción de la complejidad que sustentaría el SQL de la fuente tickets. Imagina la complejidad de escribir y depurar el SQL de la fuente tickets si llegaras a unir 20 fuentes de Malloy a tickets y usaras dimensiones/medidas de cada uno de esos joins, como yo lo he hecho.
Malloy + Looker: eficiente, escalable, colaborativo. Data engineering confiable hecho realidad.

"El todo es más que la suma de sus partes" — Aristóteles
Los ejemplos descritos arriba no son ficticios, sino el reflejo del recorrido colaborativo con datos que inicié aquí en DoiT International. Busqué unificar la exploración de múltiples sistemas de datos (datos de tickets, ventas, usuarios, empleados, y demás) dentro de un marco que maximice la confianza con la que el liderazgo puede apoyarse en la analítica generada sobre esos datasets y minimice el esfuerzo de incorporación que necesitan otros data engineers para contribuir.
Si bien Malloy es una herramienta fantástica que sin duda potencia este recorrido hacia la analítica colaborativa, por sí solo el lenguaje no facilita el uso para usuarios finales que están más interesados en generar reportes rápidamente y menos en aprender un nuevo lenguaje (es decir, liderazgo / alta gerencia). Para resolverlo, descubrí que Malloy realmente brilla cuando se combina con herramientas de dashboard de última generación, como Looker.
Comparado con otras herramientas de BI, Looker está diseñado específicamente para actuar como una fuente única y centralizada de la verdad. Si se configura correctamente mediante definiciones de dimensiones y medidas escritas en su lenguaje propietario LookML, la generación intuitiva de gráficos para casi cualquier cosa que puedas imaginar puede enseñarse —incluso a personas no técnicas— en pocos minutos. Los usuarios solo tienen que hacer clic en las dimensiones y medidas que quieren ver (que pueden abarcar varias tablas), opcionalmente añadir unos clics más para incorporar filtros o pivotar sobre una dimensión, y darle a Run. Una vez que te familiarizas con la UI de Explore de Looker, generar un gráfico que abarca múltiples fuentes de datos puede tomar segundos.
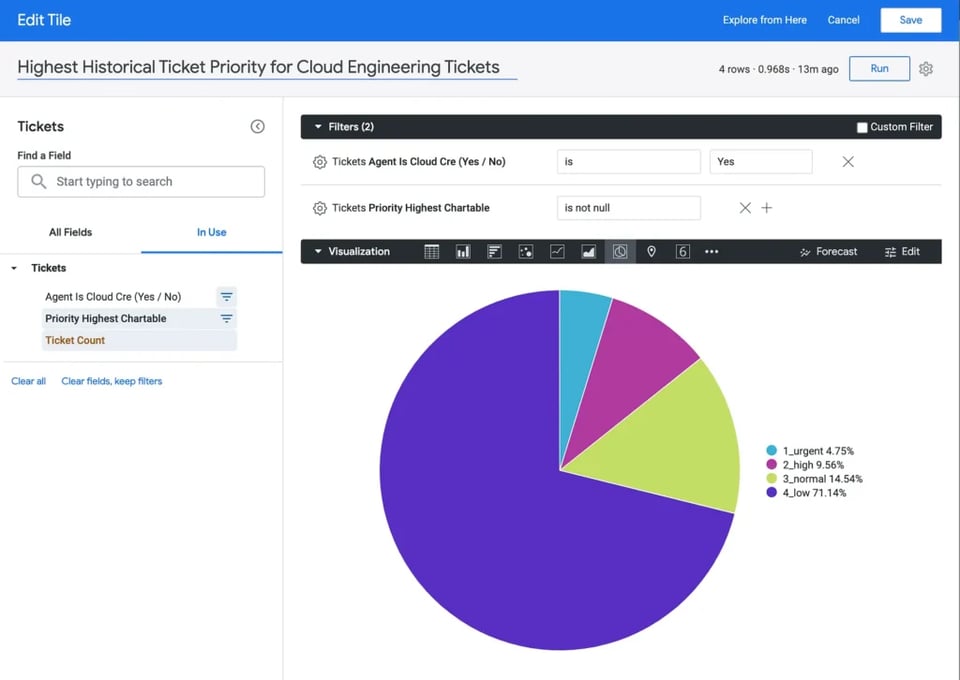
Vamos directamente a otro ejemplo. Supongamos que una persona en un rol de liderazgo está interesada en entender la proporción que cada nivel de prioridad de ticket representa dentro del total de tickets asignados al equipo de Engineering. Más concretamente, le interesa identificar el nivel de prioridad más alto que un ticket alcanzó en cualquier etapa de su ciclo de vida que haya sido atendida por engineers.
Si suponemos que el SQL de la fuente tickets de arriba se hubiera puesto a disposición dentro de Looker, un usuario final simplemente haría lo siguiente para responder esta pregunta:
- Elegir el dataset "Tickets" dentro de Looker
- Hacer clic en la dimensión "Priority Highest Chartable"
- Hacer clic en la medida "Ticket Count"
- Añadir un filtro a la dimensión "Agent is Cloud Cre Is Yes"
- Elegir la visualización Pie Chart y darle a Run
Fíjate en el tiempo de ejecución en la esquina superior derecha. Al consultar una tabla creada a partir de SQL generado por Malloy, la consulta tardó menos de 1s en ejecutarse:
Combina la facilidad de uso de Looker para el usuario final con sus otras funciones modernas, como el sistema de control de versiones que habilita capacidades de despliegue de dashboards en dev/prod, así como su configuración avanzada de seguridad que permite permisos IAM finos sobre dashboards y carpetas de dashboards, y queda claro por qué es una gran herramienta para visualizar fuentes de datos definidas con código de Malloy.
La consistencia de los datos es clave
A medida que integras SQL generado por Malloy en Looker o en la herramienta de dashboarding que prefieras, debes recordar una cosa. La clave para construir un data warehouse confiable y accesible es esta:
¡No le des acceso a los datos crudos a los usuarios finales que generan reportes!
El acceso a datos crudos es la causa subyacente de los datos divergentes y contradictorios que alimentan los reportes creados por distintos grupos y departamentos. Esto se debe a que los engineers de cada grupo —y a menudo varios engineers dentro del mismo grupo— inevitablemente buscan sus propias formas únicas de filtrar, hacer joins y agregar la información.
En su lugar, presenta únicamente tablas respaldadas por fuentes de Malloy a quienes construyen reportes, como los usuarios finales de Looker. Las fuentes de Malloy (y, hasta cierto punto, también LookML) idealmente ya habrán manejado todos los casos límite comunes, los filtros, así como los joins complejos y las definiciones de dimensiones y agregaciones. Es poco probable que todas estas complejidades combinadas sean abordadas correctamente por quienes construyen reportes individuales, y mucho menos replicadas de forma consistente en varios grupos de analistas.
Con un conjunto de fuentes de Malloy bien validadas y diseñadas de manera colaborativa, presentadas como las únicas opciones para construir dentro de Looker, no solo aseguras que los datos de la más alta calidad alimentan tu analítica, sino también que cuando usuarios finales de distintos grupos construyen gráficos, sus números coincidirán o se alinearán muy estrechamente con los producidos por gráficos hechos por otros grupos. Es importante manejar tanta complejidad de datos como sea posible detrás de escena antes de que pueda impactar a los usuarios finales.
Limitaciones actuales
Aunque combinar Malloy y Looker para diseñar un data warehouse y un sistema de reporting escalables, confiables y desarrollados de forma colaborativa ha funcionado bien en DoiT, tiene algunas limitaciones (temporales). En particular:
- Malloy es un nuevo lenguaje de programación que aún se encuentra en etapas tempranas de desarrollo. Si bien lo considero estable en mi uso diario, todavía puedes encontrarte con bugs en casos de uso límite. A menudo, las funciones más recientes están disponibles en el canal pre-release del plugin de VSCode. Aun así, los desarrolladores de Malloy en el canal de Slack de Malloy son muy serviciales y suelen responder el mismo día a reportes de bugs, solicitudes de funciones y consultas de depuración.
- Aunque Malloy soporta BigQuery, Postgres y DuckDB (y, por extensión, formatos CSV/TSV/Parquet y objetos almacenados en buckets), aún no soporta otras plataformas de data warehousing como Redshift o Snowflake. Aun así, a medida que este proyecto open-source madure, es difícil imaginar que, en cumplimiento de su misión de estar "creado específicamente para analizar datasets complejos", las soluciones de data warehousing más populares no terminen siendo soportadas.
- LookML, el lenguaje que potencia a Looker, es un lenguaje propietario que crea barreras de adopción significativas, derivadas de lo que considero una documentación pobre, materiales de aprendizaje insuficientes orientados a tutoriales paso a paso y precios empresariales del estilo "Contacta a ventas para saber más". Incluso sin Looker, Malloy puede formar la base poderosa de herramientas de BI menos potentes para el usuario final pero más rentables, como Looker Studio.
Diseña con éxito un data warehouse y un sistema de reporting escalable y desarrollado de forma colaborativa
Te deseo mucha suerte integrando Malloy y Looker para crear una base de datos que permita a cada nivel de la organización operar con mayor eficacia y confiabilidad, y que devuelva algo de la cordura perdida a tus data engineers, analistas y al equipo de la C-suite :)
¿Aún tienes preguntas sobre cómo aplicar el enfoque que he descrito en tu organización para alcanzar el éxito en el data warehousing a nivel global?
Contáctanos en DoiT International. Conformados exclusivamente por talento senior de Engineering, nos especializamos en brindar asesoría avanzada de consultoría cloud en diseño arquitectónico y depuración, sin costo alguno.
Si te interesa profundizar en otros temas de arquitectura de datos en la nube, échale un vistazo a mis otras publicaciones de blog en Medium y en el blog de DoiT International.