O cenário a seguir é mais comum do que parece — e segue sem solução há décadas. Provavelmente vai soar familiar para muitos data engineers, analistas de negócios e executivos orientados por dados:

A confusão é um momento inevitável em qualquer carreira voltada para dados
Sua empresa tem várias equipes/grupos/departamentos, cada um com seu próprio time de dados processando, armazenando e gerando relatórios sobre seus próprios datasets. A comunicação entre os grupos é mínima. Quando alguém precisa acessar dados de outra equipe, os engenheiros donos do dataset até liberam o acesso, mas raramente participam dos code reviews para garantir que quem solicitou está consultando os dados corretamente — ou pelo menos de forma alinhada com as queries da equipe dona. Mesmo ideias simples às vezes são difíceis de expressar em SQL e, conforme a empresa cresce e as perguntas ficam mais complexas, validar queries de outra equipe vira um gargalo demorado para revisar código de processamento de dados entre times.
Como resultado dessa colaboração mínima, executivos que reúnem dados e gráficos para tomar decisões e fazer apresentações às vezes percebem que, ao puxar números sobre temas parecidos em diferentes grupos, os gráficos de um grupo mostram valores bem diferentes dos gerados por outro grupo a partir dos mesmos dados brutos. Aí os executivos notam que as conclusões de um grupo contradizem as de outro.
Quando os executivos pedem soluções para essa inconsistência aos times de engenharia, costumam encontrar poucas saídas. Os motivos são vários:
- O tamanho do problema em relação ao tamanho do time. Centenas de queries podem vir de um único grupo, cada uma exigindo validação e possível correção por outros grupos. Simplesmente não há gente nem tempo suficiente para code reviews de pipelines de dados entre times.
- Os datasets por trás das queries de um grupo podem ser tão irrelevantes para outro grupo que não compensa os engenheiros do outro time investirem tempo aprendendo aquilo só para participar da validação cruzada. Uma única query pode ser complexa, ter centenas de linhas de código e incluir joins com datasets que o engenheiro revisor não tem motivo para entender fora do contexto do code review. Compreender esse SQL é demorado para qualquer pessoa que não seja a desenvolvedora original.
Diante desses obstáculos, a liderança pode optar por contratar um analista de dados que cuide das suas queries, depositando nele a confiança de entregar relatórios confiáveis. Mas essa estratégia desvia do problema de fundo: grupos diferentes chegam a resultados diferentes a partir dos mesmos dados brutos quando exploram perguntas parecidas ou conectadas. Essa inconsistência leva a decisões orientadas por dados divergentes dentro da própria empresa, mesmo quando os grupos partem da mesma base bruta. Além disso, como esse analista da liderança precisa conversar com vários grupos para acessar os datasets, ele tende a perpetuar as discrepâncias que já existem no processamento de dados entre os grupos.

Todo mundo já ouviu o ditado
Em um mundo orientado por dados, confiar com segurança nos dados que guiam a tomada de decisão é tudo. Como diz o ditado do machine learning:
Lixo (de dados) entra, lixo (de previsões) sai.
Conectar todas as suas fontes de dados brutos a um data warehouse de ponta — BigQuery, Snowflake, Redshift, etc. — e dar acesso conforme a necessidade não resolve os problemas de fundo: processamento de dados consistente em toda a empresa, falta generalizada de colaboração entre times e a confiabilidade coletiva dos resultados em todos os departamentos.
Adotar a típica abordagem segmentada para data warehousing e analytics significa que poucas — se houver — queries e fontes de dados de uma equipe são facilmente reaproveitáveis por outra. A geração de relatórios em silos acaba se enraizando, e cada grupo passa a confiar apenas no que o próprio time de dados produz. A liderança fica sem uma visão segura e consistente da organização.

O logo oficial do Malloy, uma linguagem de query que vai facilitar muito a sua vida
Conheça o Malloy, uma linguagem analítica criada pelos antigos fundadores e desenvolvedores do Looker / LookML, hoje atuando dentro do Google.
Projetado para superar as limitações do SQL — uma linguagem lançada há 44 anos, em 1979, muito antes de existirem data warehouses —, o Malloy é, ironicamente, um compilador de SQL, mas é muito mais que isso. Construir sua infraestrutura de dados pensando em SQL gerado pelo Malloy, em vez de pedir aos times de engenharia um SQL artesanal feito à mão, traz várias vantagens importantes. Antes de mergulhar nelas, porém, vamos ouvir direto do time do Malloy por que precisamos de um substituto para o SQL:
Por Ben Porterfield, cofundador do Looker e do Malloy
O SQL é uma linguagem poderosa, capaz de expressar qualquer query, mas tem suas desvantagens:
Tudo é expressável, mas nada é reutilizável
Ideias simples são complicadas de expressar
A linguagem é prolixa e não tem defaults inteligentes
O Malloy é imediatamente compreensível para quem já usa SQL e muito mais fácil de usar e aprender [1]
[1] https://malloydata.github.io/documentation/about/features.html
Por Carlin Eng, Product Manager do Malloy
A linguagem é uma ferramenta de pensamento, e melhorar a sintaxe de uma linguagem tem implicações profundas no que conseguimos imaginar e expressar. O SQL foi inventado nos anos 1970, antes da existência dos data warehouses, e portanto não poderia ter sido projetado pensando nos casos de uso de hoje.
Já o Malloy foi feito sob medida para analisar datasets complexos.
Com isso em mente, desenvolver com Malloy em vez de SQL traz as seguintes vantagens:
- Uma sintaxe simples e enxuta para escrever até as queries mais complexas. Acabou a era de escrever linha após linha de SQL boilerplate e batalhar para coletar dados difíceis de forma eficaz e eficiente sem abusar de tabelas temporárias. A simplicidade da linguagem melhora muito:
- O desenvolvimento colaborativo
- A velocidade de desenvolvimento
- A confiabilidade dos resultados
2. Uma base de código modular e reutilizável! Por exemplo:
- Fontes de dados complexas podem ser definidas e, em seguida, usadas como base para outras fontes e queries. Dá para reduzir a complexidade quebrando uma fonte complexa em várias fontes mais simples com relação pai-filho.
- Encadeamento (pipeline) de operações. A saída de uma query pode ser a entrada de outra.
3. Geração de SQL otimizada para performance de dashboard
- O compilador de SQL é bem otimizado e supera todas as queries complexas escritas à mão com as quais comparei seu desempenho. Isso é importante porque tempo é dinheiro — literalmente. Dê uma olhada nos modelos de preço do BigQuery Editions, do Snowflake e do Redshift serverless.
4. (Em breve) Recriação automatizada de tabelas/views após atualizações nas fontes e queries do Malloy
- Imagine que você tem uma fonte do Malloy definida, 100 queries consultam essa fonte e o SQL gerado por cada query é responsável por criar uma tabela no BigQuery. Suponha agora que você descobriu um bug no filtro da fonte do Malloy e precisa fazer uma mudança crucial nesse filtro. Depois de atualizar o filtro, dá para automatizar a recriação das 100 tabelas do BigQuery fazendo com que o motor do Malloy reexecute todas as queries downstream que dependem daquela fonte upstream. Os metadados associados a cada query informam ao motor do Malloy qual tabela do BigQuery aquela query deve recriar.
5. …e muito mais!
Vamos a um exemplo prático para entender como esses recursos se combinam para beneficiar uma organização e permitir que ela opere em escala de forma mais eficaz.
Malloy na prática: um caso de uso real em produção
Imagine que você trabalha em uma empresa com um sistema de tickets de atendimento ao cliente. Por esse sistema entram tickets sobre temas que envolvem vários grupos: tickets técnicos, tickets de relacionamento comercial e tickets financeiros. Assim, os times de engenharia, vendas e finanças querem capturar várias métricas sobre como os tickets são tratados, mas cada grupo geralmente só se interessa pelas métricas relacionadas ao próprio grupo.
Sem o Malloy, esse cenário normalmente significa que um engenheiro de cada grupo recebe acesso ao dataset bruto do sistema de tickets e manipula os dados como achar melhor para gerar as métricas e relatórios necessários. Pode até haver vários data engineers dentro de um mesmo grupo trabalhando de forma quase independente, filtrando, fazendo joins e agregando dados de jeitos um pouco diferentes uns dos outros.
Essa abordagem de geração de relatórios é problemática, porque há muitos filtros e edge cases desafiadores a considerar, e é improvável que todos os data engineers que trabalham com esse dataset descubram cada um deles de forma independente. Alguns exemplos de questões que precisam ser tratadas antes do cálculo das métricas-chave:
- Excluir tickets parecidos com 'spam'
- Excluir tickets 'scrubbed', removidos por motivos diversos — por exemplo, por conterem dados PII
- Excluir tickets gerados internamente, como em testes de aplicação
- Reprodutibilidade entre grupos para cálculos complicados, como tempo até a atribuição do ticket, tempo de primeira resposta, tempo de resposta a escalonamentos, tempo de resolução do ticket, tempo de violação de SLO, etc.
- Diferenciação clara entre dimensões parecidas. Por exemplo: nível de prioridade original vs. atual vs. mais alto vs. mais baixo atribuído ao longo do histórico de um ticket. Quando um relatório fala em prioridade do ticket, qual delas está sendo referenciada?
- Capacidade de capturar dimensões valiosas extraídas de certos tickets via expressões regulares complexas, em que o texto extraído pode aparecer em vários formatos diferentes.
Com o Malloy, todas essas preocupações começam a ficar triviais.
Os engenheiros que tratam desse problema com foco em uma funcionalidade interdepartamental podem começar escrevendo uma fonte Malloy fundamental que todos os grupos vão usar — vamos chamá-la de tickets. Lidando com todos os problemas destacados acima, a fonte tickets poderia ficar parecida com este pseudocódigo:
source: tickets is table('bigquery_project.dataset_name.table_name'){ primary_key: id where: spam_ticket = false, scrubbed_ticket = false, internal_test_ticket = false join_one: priority_history on priority_history.ticket_id = id join_one: agents is users on agents.id = assignee_id dimension: priority_original is priority_history.priority_original dimension: priority_highest is priority_history.priority_highest dimension: priority_highest_chartable is priority? pick '1_urgent' when 'urgent' pick '2_high' when 'high' pick '3_normal' when 'normal' pick '4_low' when 'low' else null dimension: priority_current is priority dimension: agent_is_engineer is agents.agent_is_engineer dimension: agent_is_sales is agents.agent_is_sales dimension: agent_is_finance is agents.agent_is_finance dimension: special_request_requester_email is pick coalesce(lower(regexp_extract(description, r'Requested by: (\S+@doit(?:-intl)?\.com)\n')), lower(regexp_extract(subject, r'^(\S+@doit(?:-intl)?\.com) ', 1))) when is_special_request = true else null dimension: time_to_solve_hours is seconds(created_at to solved_at) / 3600 measure: avg_solve_time_hours is round(avg(time_to_solve_hours), 1) measure: ticket_count is count(distinct id)}O código que define as fontes do Malloy às quais fazemos join em tickets — users e priority_history — não está mostrado, mas não precisamos vê-lo para entender como essas fontes estão sendo usadas. O papel delas em definir dimensões relacionadas à função do agente e ao histórico de prioridade do ticket é claro. Como essas dimensões puxadas para a fonte tickets são definidas é praticamente irrelevante. Essa é a beleza de uma base de código que aproveita a natureza modular do Malloy.
Com essa fonte fundamental no lugar (que, por sua vez, depende de joins com duas outras fontes), você pode criar várias fontes filhas dependentes da fonte tickets, cada uma específica para um grupo departamental:
source: engineering_tickets is tickets { where: agent_is_engineer = true}source: sales_tickets is tickets { where: agent_is_sales = true}source: finance_tickets is tickets { where: agent_is_finance = true}Agora que temos uma fonte Malloy feita sob medida para cada departamento, com vários filtros complexos, dimensões e edge cases tratados nos bastidores, os engenheiros de cada grupo podem fazer queries sobre os tickets confiando que a forma como suas métricas são calculadas (por exemplo, quais tickets entram no cálculo e a matemática por trás dele) será igual entre os grupos. Note que o algoritmo por trás da métrica avg_solve_time_hours está definido na fonte tickets, mas é invocado pelo comando aggregate nas fontes filhas:
query: avg_solve_time_engineering is engineering_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_sales is sales_tickets -> { aggregate: avg_solve_time_hours}query: avg_solve_time_finance is finance_tickets -> { aggregate: avg_solve_time_hours}Suponha que cada time também queira saber quantos tickets foram gerados em seu departamento nos últimos três meses em que, em algum momento do histórico do ticket, ele foi um problema urgente/P1:
query: tickets_past_3_months_engineering is engineering_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_sales is sales_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}query: tickets_past_3_months_finance is finance_tickets -> { where: priority_highest_chartable = '1_urgent', created_at >= now - 3 months aggregate: ticket_count}Queries Malloy como essas — surpreendentemente fáceis de ler graças à natureza modular da linguagem — podem compilar em centenas de linhas de SQL, dependendo de quantas dependências de fontes pai, joins, filtros e agregações existem em cada uma das fontes que sua query usa.
E esse SQL vai rodar muito mais rápido — e de forma mais econômica — do que qualquer equivalente escrito à mão.
Essa alternativa modular ao SQL também significa que, se um bug for encontrado em uma query, basta percorrer uma série de fontes upstream, fáceis de ler e de baixa complexidade, até descobrir e corrigir o problema. Depois disso, todas as queries — e as tabelas/views do banco que elas alimentam — que dependem da fonte atualizada podem ser rapidamente reexecutadas e reconstruídas.
Assim, correções de bugs feitas por um grupo são integradas de forma fluida e rápida ao trabalho de outros grupos que se apoiam nas mesmas fontes de dados Malloy.
Quão claro e conciso o código Malloy realmente consegue ser?
Os exemplos de fontes e queries Malloy acima mostram bem a natureza modular da linguagem, mas não fazem jus à clareza dela quando se trata de fazer perguntas complexas.
Vamos olhar a fonte priority_history que, como vimos, faz join com a fonte tickets para fornecer dimensões que destacam o histórico de prioridade de um ticket: original, atual e a maior prioridade já registrada.
Determinar essas prioridades exige percorrer o histórico de mudanças feitas em um ticket, o que demanda uma query com várias subqueries aninhadas. Subqueries aninhadas em SQL são feias; em Malloy ficam limpas e fáceis de ler. Vamos comparar como priority_history é definida em cada linguagem, começando pelo Malloy:
source: priority_history is from(field_history{where: field_name = 'priority'} -> { group_by: ticket_id nest: priority_original is { group_by: priority_original is value, updated order_by: updated asc limit: 1 } nest: priority_final is { group_by: priority_final is value, updated order_by: updated desc limit: 1 } nest: priority_urgent_present is { group_by: priority_urgent_present is true where: value = 'urgent' limit: 1 } nest: priority_high_present is { group_by: priority_high_present is true where: value = 'high' limit: 1 } nest: priority_normal_present is { group_by: priority_normal_present is true where: value = 'normal' limit: 1 } nest: priority_low_present is { group_by: priority_low_present is true where: value = 'low' limit: 1 }} -> { project: ticket_id, priority_original.priority_original, priority_final.priority_final, priority_highest is pick 'urgent' when priority_urgent_present.priority_urgent_present = true pick 'high' when priority_high_present.priority_high_present = true pick 'normal' when priority_normal_present.priority_normal_present = true pick 'low' when priority_low_present.priority_low_present = true else null order_by: ticket_id desc})Compare com o SQL otimizado para dashboard que ele gera:
WITH __stage0 AS ( SELECT group_set, CASE WHEN group_set IN (0,1,2,3,4,5,6) THEN field_history.ticket_id END as ticket_id__0, CASE WHEN group_set=1 THEN field_history.value END as priority_original__1, CASE WHEN group_set=1 THEN field_history.updated END as updated__1, CASE WHEN group_set=2 THEN field_history.value END as priority_final__2, CASE WHEN group_set=2 THEN field_history.updated END as updated__2, CASE WHEN group_set=3 THEN true END as priority_urgent_present__3, CASE WHEN group_set=4 THEN true END as priority_high_present__4, CASE WHEN group_set=5 THEN true END as priority_normal_present__5, CASE WHEN group_set=6 THEN true END as priority_low_present__6 FROM `project-name.dataset-name.table-name` as field_history CROSS JOIN (SELECT row_number() OVER() -1 group_set FROM UNNEST(GENERATE_ARRAY(0,6,1))) WHERE (field_history.field_name='priority') AND ((group_set NOT IN (3) OR (group_set IN (3) AND field_history.value='urgent'))) AND ((group_set NOT IN (4) OR (group_set IN (4) AND field_history.value='high'))) AND ((group_set NOT IN (5) OR (group_set IN (5) AND field_history.value='normal'))) AND ((group_set NOT IN (6) OR (group_set IN (6) AND field_history.value='low'))) GROUP BY 1,2,3,4,5,6,7,8,9,10), __stage1 AS ( SELECT ticket_id__0 as ticket_id, ARRAY_AGG(CASE WHEN group_set=1 THEN STRUCT( priority_original__1 as priority_original, updated__1 as updated ) END IGNORE NULLS ORDER BY updated__1 asc LIMIT 1) as priority_original, ARRAY_AGG(CASE WHEN group_set=2 THEN STRUCT( priority_final__2 as priority_final, updated__2 as updated ) END IGNORE NULLS ORDER BY updated__2 desc LIMIT 1) as priority_final, ARRAY_AGG(CASE WHEN group_set=3 THEN STRUCT( priority_urgent_present__3 as priority_urgent_present ) END IGNORE NULLS ORDER BY priority_urgent_present__3 asc LIMIT 1) as priority_urgent_present, ARRAY_AGG(CASE WHEN group_set=4 THEN STRUCT( priority_high_present__4 as priority_high_present ) END IGNORE NULLS ORDER BY priority_high_present__4 asc LIMIT 1) as priority_high_present, ARRAY_AGG(CASE WHEN group_set=5 THEN STRUCT( priority_normal_present__5 as priority_normal_present ) END IGNORE NULLS ORDER BY priority_normal_present__5 asc LIMIT 1) as priority_normal_present, ARRAY_AGG(CASE WHEN group_set=6 THEN STRUCT( priority_low_present__6 as priority_low_present ) END IGNORE NULLS ORDER BY priority_low_present__6 asc LIMIT 1) as priority_low_present FROM __stage0 GROUP BY 1 ORDER BY 1 asc), __stage2 AS ( SELECT base.ticket_id as ticket_id, priority_original_0.priority_original as priority_original, priority_final_0.priority_final as priority_final, CASE WHEN priority_urgent_present_0.priority_urgent_present=true THEN 'urgent' WHEN priority_high_present_0.priority_high_present=true THEN 'high' WHEN priority_normal_present_0.priority_normal_present=true THEN 'normal' WHEN priority_low_present_0.priority_low_present=true THEN 'low' ELSE NULL END as priority_highest FROM __stage1 as base LEFT JOIN UNNEST(base.priority_urgent_present) as priority_urgent_present_0 LEFT JOIN UNNEST(base.priority_high_present) as priority_high_present_0 LEFT JOIN UNNEST(base.priority_normal_present) as priority_normal_present_0 LEFT JOIN UNNEST(base.priority_low_present) as priority_low_present_0 LEFT JOIN UNNEST(base.priority_original) as priority_original_0 LEFT JOIN UNNEST(base.priority_final) as priority_final_0 ORDER BY 1 desc)SELECT priority_history.ticket_id as ticket_id, priority_history.priority_original as priority_original, priority_history.priority_final as priority_final, priority_history.priority_highest as priority_highestFROM __stage2 as priority_historyQual desses exemplos você preferiria depurar?
Lembre-se de que tickets_history é só uma das várias fontes Malloy que dão join na fonte tickets para que suas dimensões possam ser usadas em analytics de tickets — ou seja, é apenas uma pequena parcela da complexidade que estaria por trás do SQL da fonte tickets. Imagine a complexidade de escrever e depurar o SQL da fonte tickets se você fizesse join de 20 fontes Malloy em tickets e usasse dimensões/medidas de cada um desses joins, como eu fiz.
Malloy + Looker: eficiente, escalável, colaborativo. Engenharia de dados confiável de verdade.

"O todo é maior do que a soma das partes" — Aristóteles
Os exemplos descritos acima não são fictícios; eles refletem a jornada de dados colaborativa que iniciei aqui na DoiT International. Eu queria ajudar a unificar a exploração de múltiplos sistemas de dados (dados de tickets, vendas, usuários, funcionários e por aí vai) dentro de um framework que maximizasse a confiança que a liderança pode depositar nas análises feitas a partir desses datasets e minimizasse o esforço inicial para que outros data engineers contribuíssem.
Embora o Malloy seja uma ferramenta fantástica que potencializa essa jornada rumo a um analytics colaborativo, sozinho ele não garante facilidade de uso para usuários finais que estão mais interessados em gerar relatórios rapidamente do que em aprender uma nova linguagem (ou seja, lideranças e alta gestão). Para resolver isso, descobri que o Malloy realmente brilha quando combinado com ferramentas modernas de dashboard, como o Looker.
Em comparação com outras ferramentas de BI, o Looker foi feito sob medida para atuar como uma fonte centralizada da verdade. Se configurado corretamente via definições de dimensions e measures escritas em sua linguagem proprietária LookML, dá para ensinar — até para pessoas não técnicas — em poucos minutos como gerar gráficos intuitivos para praticamente qualquer coisa que você imaginar. Os usuários só precisam clicar nas dimensions e measures que querem ver (que podem cobrir várias tabelas), opcionalmente dar mais alguns cliques para adicionar filtros ou pivotar uma dimension, e clicar em Run. Depois que você se familiariza com a UI Explore do Looker, gerar um gráfico que cruza várias fontes de dados leva segundos.
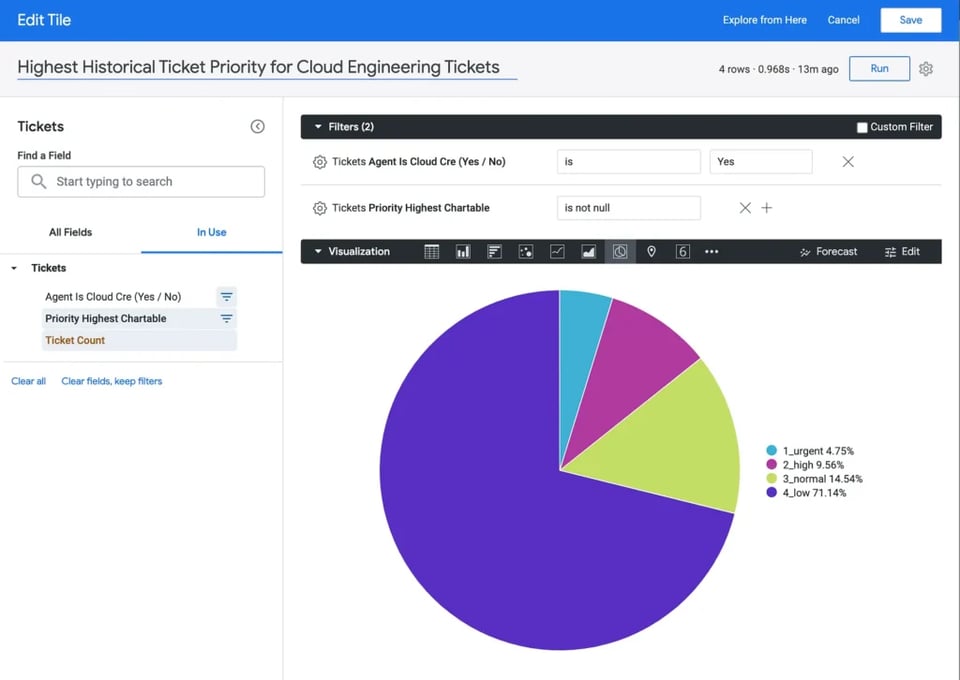
Vamos direto a outro exemplo. Suponha que alguém da liderança queira entender qual a proporção de cada prioridade de ticket no total de tickets atribuídos ao time de engenharia. Mais precisamente, quer identificar o nível de prioridade mais alto que um ticket atingiu em qualquer fase do seu ciclo de vida tratada por engenheiros.
Supondo que o SQL da fonte tickets acima foi disponibilizado dentro do Looker, um usuário final faria simplesmente o seguinte para responder essa pergunta:
- Escolher o dataset 'Tickets' dentro do Looker
- Clicar na dimension 'Priority Highest Chartable'
- Clicar na measure 'Ticket Count'
- Adicionar um filtro na dimension "Agent is Cloud Cre Is Yes"
- Clicar na visualização de gráfico de pizza e em Run
Repare no tempo de execução no canto superior direito. Como bate em uma tabela criada a partir de SQL gerado pelo Malloy, a query levou menos de 1s para executar:
Combine a facilidade de uso do Looker para o usuário final com seus outros recursos modernos — como o sistema de versionamento que viabiliza deploys de dashboards em dev/prod e as configurações avançadas de segurança que permitem permissões IAM granulares para dashboards e pastas de dashboards — e fica claro por que ele é uma ótima ferramenta para visualizar fontes de dados definidas em código Malloy.
Consistência de dados é fundamental
Ao integrar o SQL gerado pelo Malloy ao Looker ou à sua ferramenta de dashboard preferida, lembre-se de uma coisa. A chave para construir um data warehouse confiável e acessível é esta:
Não dê acesso aos dados brutos para os usuários finais que geram relatórios!
O acesso aos dados brutos é a causa raiz dos dados divergentes e conflitantes que alimentam relatórios criados por diferentes grupos e departamentos. Isso acontece porque engenheiros de cada grupo — e muitas vezes vários engenheiros dentro do mesmo grupo — inevitavelmente seguem suas próprias formas de filtrar, fazer joins e agregar informações.
Em vez disso, ofereça apenas tabelas baseadas em fontes Malloy a quem constrói relatórios, como os usuários finais do Looker. As fontes Malloy (e, em certa medida, o LookML também) idealmente já terão tratado todos os edge cases comuns, filtros, além de joins complexos e definições de dimensions e agregações. Toda essa complexidade junta dificilmente seria tratada corretamente por construtores de relatórios individuais — quanto mais replicada de forma consistente entre vários grupos de analistas.
Com um conjunto de fontes Malloy bem validadas e desenhadas de forma colaborativa apresentadas como as únicas opções para construir gráficos no Looker, você garante não só que dados da mais alta qualidade alimentem seu analytics, mas também que, quando usuários finais de grupos diferentes montam gráficos, os números deles vão coincidir ou ficar muito próximos dos produzidos por gráficos feitos por outros grupos. É importante tratar o máximo de complexidade possível nos bastidores antes que ela impacte os usuários finais.
Limitações atuais
Embora usar Malloy e Looker juntos para projetar um data warehouse e um sistema de relatórios escalável, confiável e desenvolvido de forma colaborativa tenha funcionado bem na DoiT, há algumas limitações (temporárias). A saber:
- O Malloy é uma linguagem de programação nova, ainda em fase inicial de desenvolvimento. Embora eu considere a linguagem estável no meu uso diário, você ainda pode encontrar bugs em casos de uso de borda. Muitas vezes, os recursos mais novos estão no canal de pré-release do plugin do VSCode. Mesmo assim, os desenvolvedores do Malloy no canal do Slack do Malloy são prestativos e costumam responder no mesmo dia a relatos de bugs, pedidos de recursos e dúvidas de depuração.
- Embora o Malloy ofereça suporte a BigQuery, Postgres e DuckDB (e, por extensão, formatos CSV/TSV/Parquet e objetos armazenados em buckets), ele ainda não suporta outras plataformas de data warehousing, como Redshift e Snowflake. Mesmo assim, conforme esse projeto open source amadurece, é difícil imaginar que, em busca da sua missão de ser "feito sob medida para analisar datasets complexos", as soluções de data warehousing mais populares acabem ficando de fora.
- O LookML, a linguagem que move o Looker, é uma linguagem proprietária que cria barreiras consideráveis de adoção, originadas do que eu consideraria documentação ruim, pouco material de aprendizado focado em walkthroughs e o estilo de preço enterprise do tipo "entre em contato com vendas para saber mais". Mesmo sem o Looker, o Malloy pode formar a base poderosa para ferramentas de BI menos voltadas ao usuário final, mas mais econômicas, como o Looker Studio.
Projete com sucesso um data warehouse e um sistema de relatórios escalável e colaborativo
Desejo sucesso a você na integração entre Malloy e Looker para criar uma base de dados que permita a cada nível da organização operar de forma mais eficaz e confiável, e que devolva um pouco da sanidade aos seus data engineers, analistas e ao time da diretoria :)
Ainda tem dúvidas sobre como aplicar a abordagem que descrevi na sua organização para alcançar o sucesso em data warehousing em toda a empresa?
Fale com a gente na DoiT International. Com um time formado exclusivamente por engenheiros sêniores, somos especialistas em consultoria avançada de cloud, design arquitetural e ajuda na depuração — sem custo nenhum.
Se você quiser se aprofundar em outros temas de arquitetura de dados na nuvem, confira meus outros posts no Medium e no nosso blog da DoiT International.