
10〜15分を超える長時間処理にGoogle Cloud Runを使いこなすための実践的アプローチを解説します

Google Cloud Run は、Web リクエストや Cloud Pub/Sub イベントから呼び出せるステートレスコンテナを実行できる、マネージド型のコンピューティングプラットフォームです。Cloud Run はサーバーレスのため、インフラ管理はすべて隠蔽され、開発者は本来注力すべきこと——優れたアプリケーションづくり——に専念できます。Knative をベースにしており、フルマネージドで動かすか、自社の Google Kubernetes Engine クラスター上で動かすかを選べます。
DoiT International のクラウドアーキテクトとして、私は workloads の一部をサーバーレスへ移行したいと考える多くの企業を支援しています。近い将来、より多くの workloads が Google Cloud Run のようなサービスへ移っていくと確信しています。
とはいえ、Google Cloud Run には見過ごせない制約があります。タスクの最大実行時間は、フルマネージド版で15分、自社の GKE クラスター上で動かす場合は10分です。多くの workloads ではこの時間で十分なため通常は問題になりませんが、用途によってはこの制限が大きな壁になります。
Lak Lakshmanan 氏は最近、Google AI Platform を用いてバックグラウンドタスクを実行する解決策 [1] を公開しています。本記事で紹介するアプローチの代替案として参考になるでしょう。
私自身、Google Cloud Run で長時間のバックグラウンドタスクを動かす方法を試行錯誤してみました。その成果をご紹介します。
免責事項 — 本手法は、常に成立すると保証されたわけではない仮定や観察に基づいています。 コード はプロダクション品質ではありませんが、長時間バックグラウンドタスクを実行するサービスを構築する際のひな型として活用できます。
前提は次のとおりです。
- リクエストが届き続けている限り、Cloud Run はコンテナをシャットダウンしない。
- ロードバランサーは受信リクエストをサービスインスタンスに均等に振り分ける。
長時間リクエストを扱う定番パターンとして、クライアント側ポーリングを利用しました。クライアントから処理依頼を受けると、サーバーはバックグラウンドワーカーを起動し、HTTP 202(Accepted)を返します。
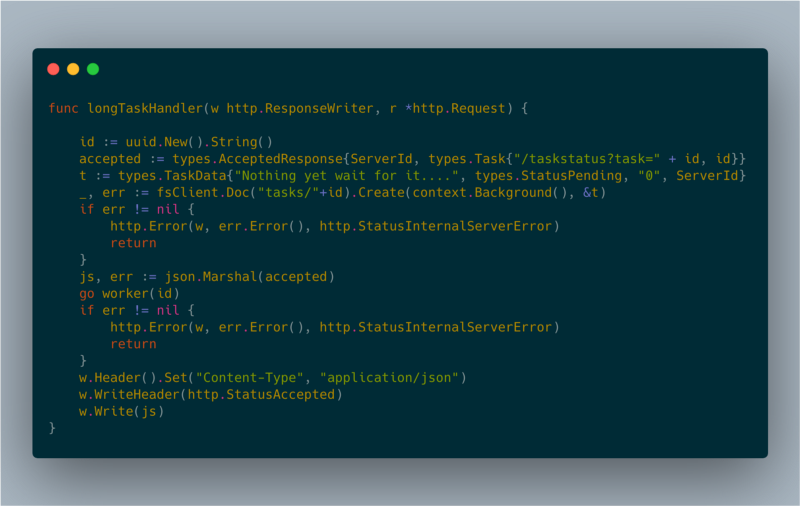 longTaskHandler
longTaskHandler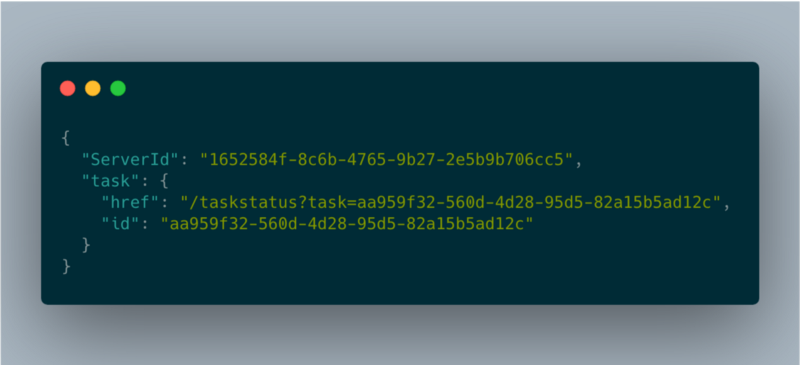 json response
json response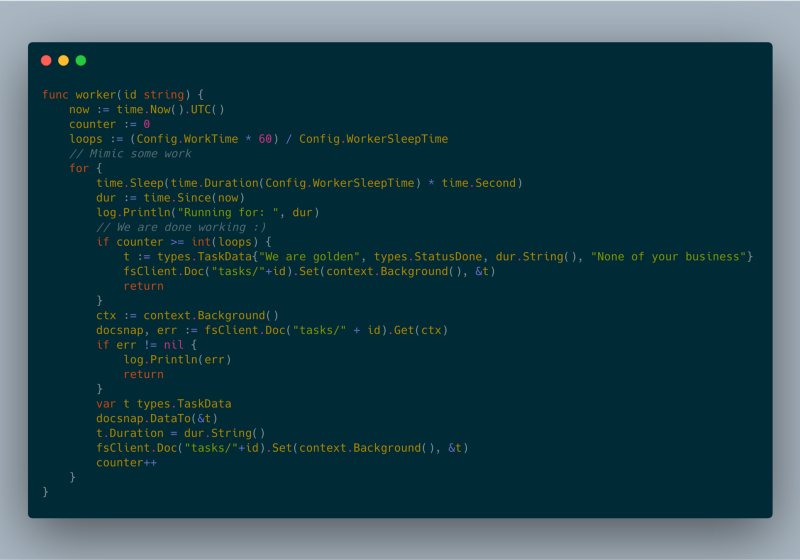 worker code
worker code
「href」フィールドは、処理状況を確認するためにクライアントがポーリングすべき URL です。クライアントはジョブのステータスを取得するために、数秒おきにこのエンドポイントを呼び出します。これによりインスタンスが稼働し続けることも担保されます。
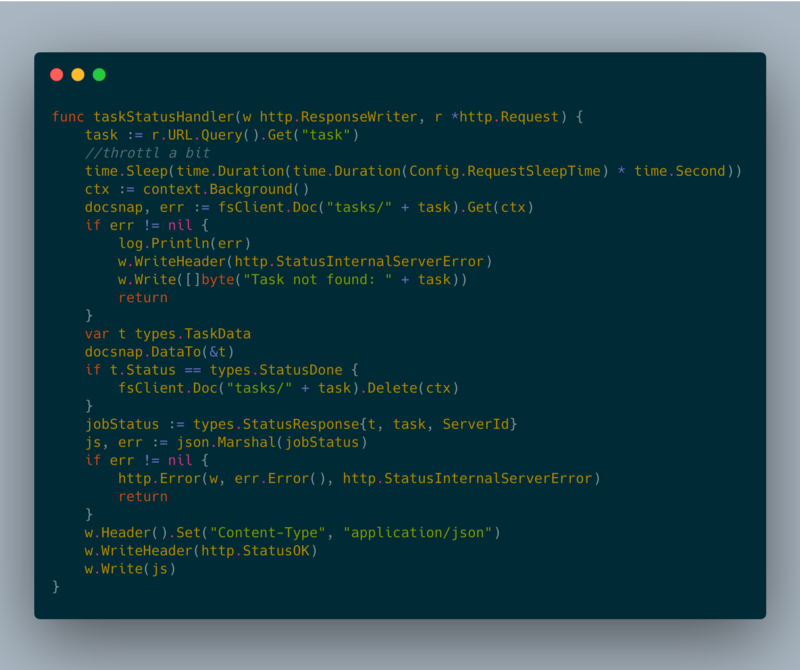 taskStatusHandler
taskStatusHandler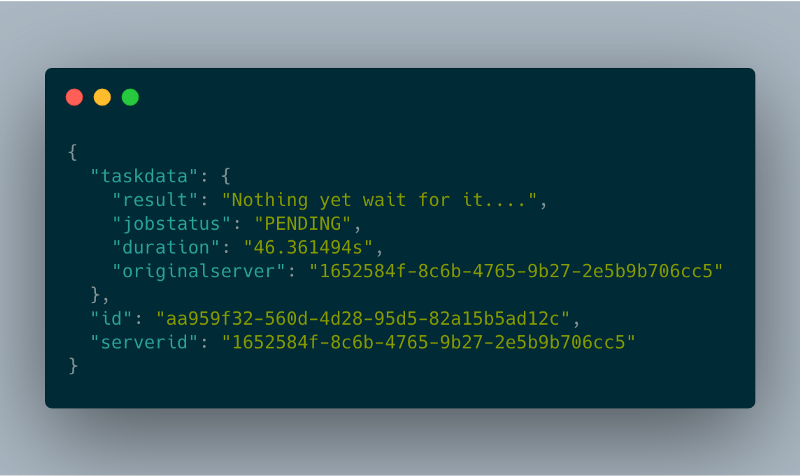 task status response
task status response
複数の Google Cloud Run インスタンスに対応するためには、タスクのステータスを共有する永続化層が必要でした。当初は Google Cloud Memorystore [2] を使うつもりでしたが、現時点では Google Cloud Run からアクセスできません。そこで永続化層には Google Cloud Firestore [3] を採用しました。
検証では、複数のバックグラウンドタスクを1時間以上にわたって安定して実行できました。テストはすべてフルマネージド版の Google Cloud Run で実施しています。
ソースコード一式はこちらで公開しています。
[1] https://medium.com/google-cloud/how-to-run-serverless-batch-jobs-on-google-cloud-ca45a4e33cb1 by Lak Lakshmanan.
[2] https://cloud.google.com/memorystore
[3] https://cloud.google.com/firestore
他の記事もぜひご覧ください。ブログをチェックいただくか、Twitter で Aviv をフォローしてください。