
Uma visão pessoal sobre como usar o Google Cloud Run em funções que demoram mais de 10 a 15 minutos

O Google Cloud Run é uma plataforma gerenciada de computação que permite rodar contêineres stateless acionáveis por requisições web ou eventos do Cloud Pub/Sub. O Cloud Run é serverless: abstrai todo o gerenciamento de infraestrutura para você focar no que realmente importa — criar ótimas aplicações. Ele é baseado no Knative e deixa você escolher entre rodar seus contêineres no modo totalmente gerenciado ou no seu próprio cluster do Google Kubernetes Engine.
Como cloud architect na DoiT International, trabalho com muitas empresas que querem migrar parte dos seus workloads para computação serverless, e acredito que, num futuro próximo, mais workloads vão para serviços como o Google Cloud Run.
Só que usar o Google Cloud Run traz uma limitação importante — suas tarefas podem rodar por até 15 minutos no serviço totalmente gerenciado, ou 10 minutos se você usar o Google Cloud Run no seu próprio cluster GKE. Em geral, isso não chega a ser um problema, já que a maioria dos workloads não exige tanto tempo de processamento, mas, para alguns casos, pode ser bem restritivo.
Lak Lakshmanan publicou recentemente uma solução [1] para rodar tarefas em segundo plano usando o Google AI Platform, que pode ser uma alternativa às ideias deste artigo.
Passei um tempo explorando como usar o Google Cloud Run para rodar tarefas longas em segundo plano, e foi isso que descobri.
Aviso — esta solução se apoia em algumas suposições e observações que não têm garantia de se manterem sempre. O código não tem qualidade de produção, mas pode servir de ponto de partida para construir um serviço que rode tarefas longas em segundo plano.
Minhas premissas são as seguintes:
- Enquanto houver requisições chegando, o Cloud Run não vai desligar o contêiner.
- O load balancer vai distribuir as requisições de entrada de forma equilibrada entre as instâncias do serviço.
Aproveitei um padrão bem conhecido para tratar requisições longas usando polling do lado do cliente. Quando o cliente solicita uma operação, o servidor cria um worker em segundo plano e responde com o código HTTP 202 (accepted)
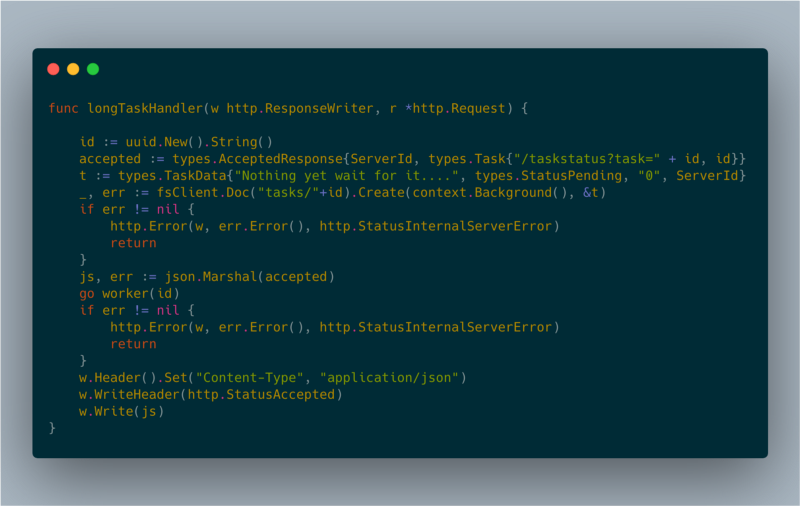 longTaskHandler
longTaskHandler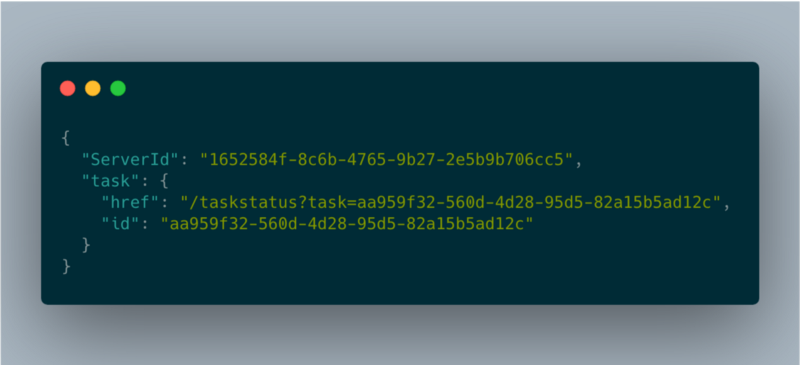 json response
json response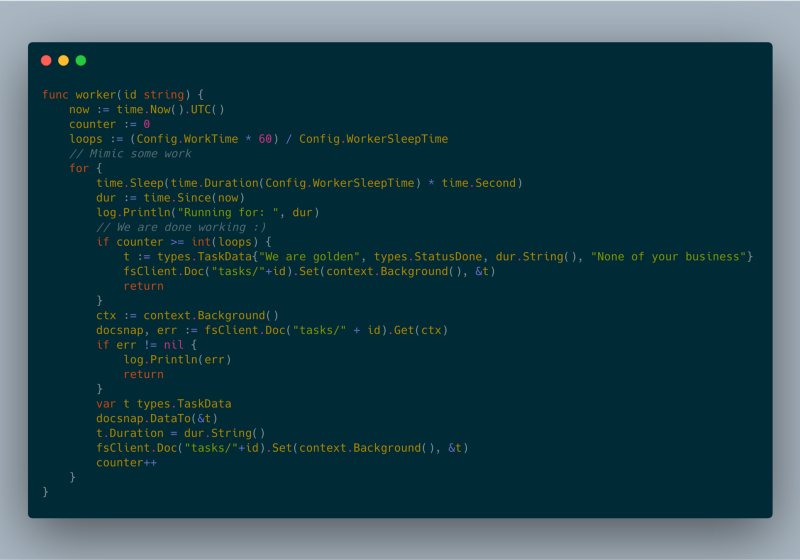 worker code
worker code
O campo "href" é o que o cliente deve consultar via polling para obter o status da operação. O cliente precisa chamar esse endpoint a cada poucos segundos para verificar o status do job. Isso também garante que a instância siga ativa.
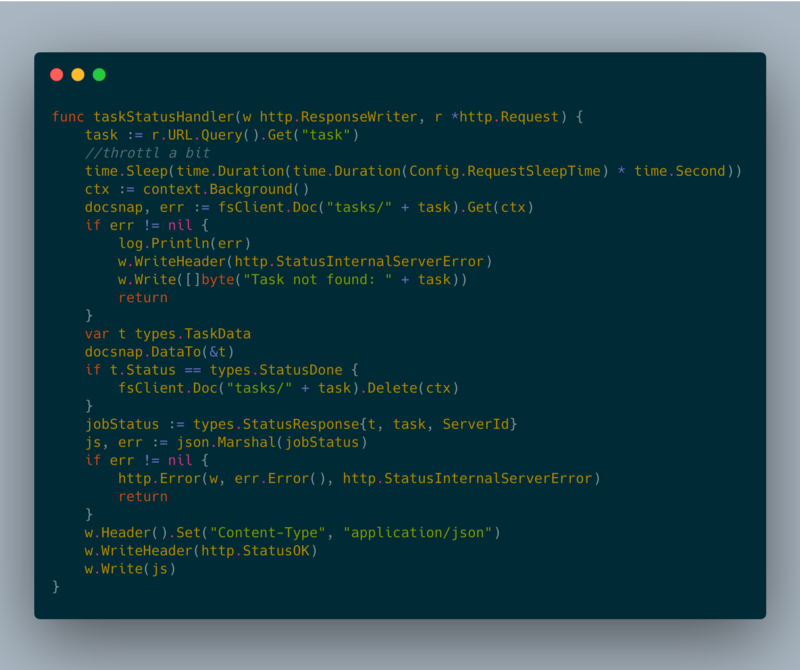 taskStatusHandler
taskStatusHandler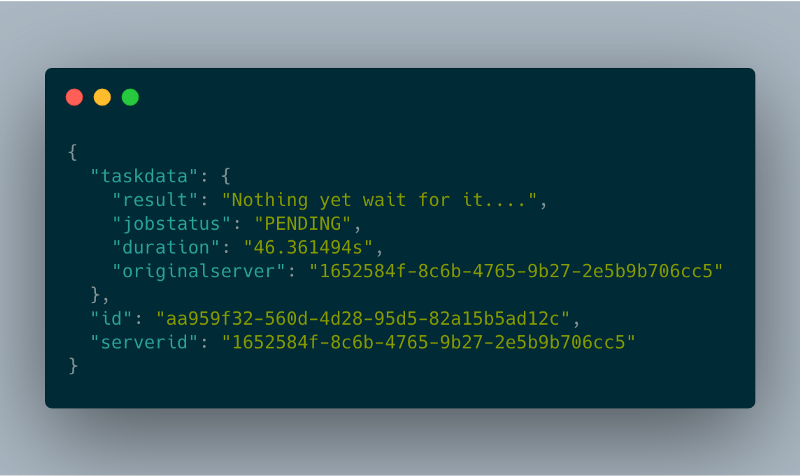 task status response
task status response
Para dar suporte a mais de uma instância do Google Cloud Run, eu precisava de algum tipo de camada persistente para compartilhar os status das tarefas. A ideia inicial era usar o Google Cloud Memorystore [2], mas ele ainda não está acessível a partir do Google Cloud Run. Por isso, estou usando o Google Cloud Firestore [3] como camada persistente.
Nos meus experimentos, consegui rodar várias tarefas em segundo plano por bem mais de uma hora. Todos os testes foram feitos na versão totalmente gerenciada do Google Cloud Run.
O código-fonte completo está aqui.
[1] https://medium.com/google-cloud/how-to-run-serverless-batch-jobs-on-google-cloud-ca45a4e33cb1 por Lak Lakshmanan.
[2] https://cloud.google.com/memorystore
[3] https://cloud.google.com/firestore
Quer mais conteúdos? Confira nosso blog ou siga o Aviv no Twitter.