
Eine pointierte Sicht darauf, wie sich Google Cloud Run für Funktionen nutzen lässt, die länger als 10–15 Minuten laufen

Google Cloud Run ist eine Managed-Compute-Plattform, auf der sich zustandslose Container ausführen lassen, die per Web-Request oder Cloud-Pub/Sub-Event aufgerufen werden. Cloud Run ist serverless: Das gesamte Infrastrukturmanagement läuft im Hintergrund, sodass Sie sich auf das Wesentliche konzentrieren können — auf großartige Anwendungen. Die Plattform basiert auf Knative und Sie entscheiden selbst, ob Sie Ihre Container vollständig gemanagt oder im eigenen Google Kubernetes Engine Cluster betreiben.
Als Cloud Architect bei DoiT International arbeite ich mit zahlreichen Unternehmen zusammen, die Teile ihrer workloads auf Serverless Computing umstellen wollen. Ich bin überzeugt: In naher Zukunft werden immer mehr workloads auf Diensten wie Google Cloud Run laufen.
Google Cloud Run hat allerdings eine ernstzunehmende Einschränkung: Tasks dürfen im vollständig gemanagten Service maximal 15 Minuten laufen, auf einem eigenen GKE-Cluster sogar nur 10 Minuten. Für die meisten workloads ist das kein Problem, denn sie brauchen solche langen Verarbeitungszeiten gar nicht — in bestimmten Szenarien kann das aber sehr hinderlich werden.
Lak Lakshmanan hat kürzlich eine Lösung [1] für Hintergrund-Tasks mit der Google AI Platform vorgestellt — eine mögliche Alternative zu den hier beschriebenen Ansätzen.
Ich habe mir etwas Zeit genommen, um auszuloten, wie sich Google Cloud Run für lang laufende Hintergrund-Tasks einsetzen lässt — und das hier sind meine Erkenntnisse.
Disclaimer — Diese Lösung beruht auf Annahmen und Beobachtungen, für deren dauerhafte Gültigkeit es keine Garantie gibt. Der Code ist nicht produktionsreif, eignet sich aber als Gerüst für einen Service, der lang laufende Hintergrund-Tasks abarbeitet.
Meine Annahmen lauten:
- Solange Requests eingehen, fährt Cloud Run den Container nicht herunter.
- Der Load Balancer verteilt eingehende Requests gleichmäßig auf die Service-Instanzen.
Ich habe ein bewährtes Pattern für lang laufende Requests genutzt: clientseitiges Polling. Fordert ein Client eine Operation an, startet der Server einen Background Worker und antwortet mit HTTP-Status 202 (Accepted).
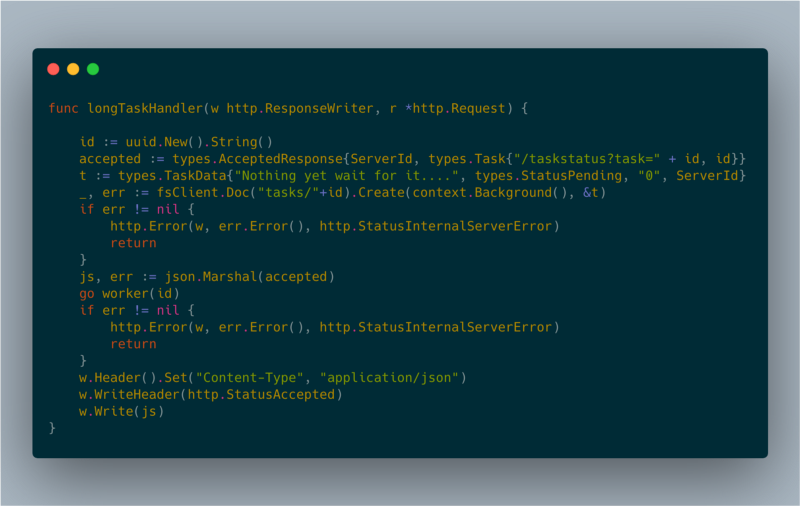 longTaskHandler
longTaskHandler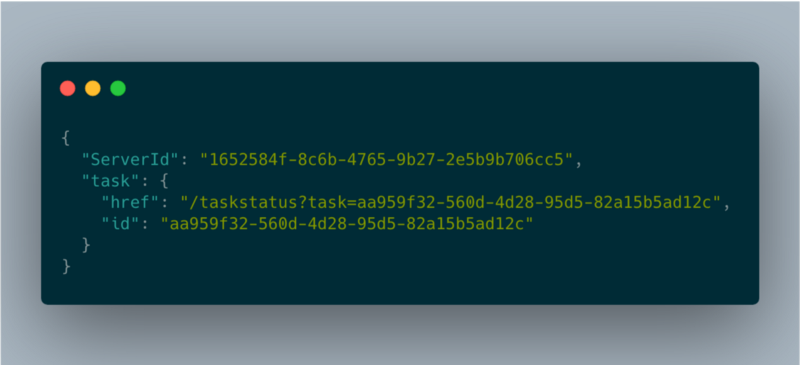 json response
json response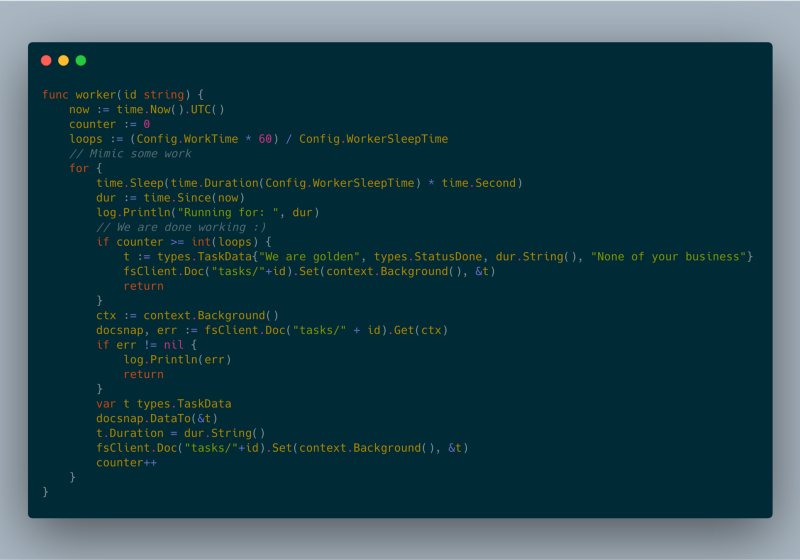 worker code
worker code
Das Feld "href" enthält die URL, die der Client pollen muss, um den Status der Operation abzufragen. Der Client ruft diesen Endpoint alle paar Sekunden auf, um den Job-Status zu erhalten — und hält damit zugleich die Instanz aktiv.
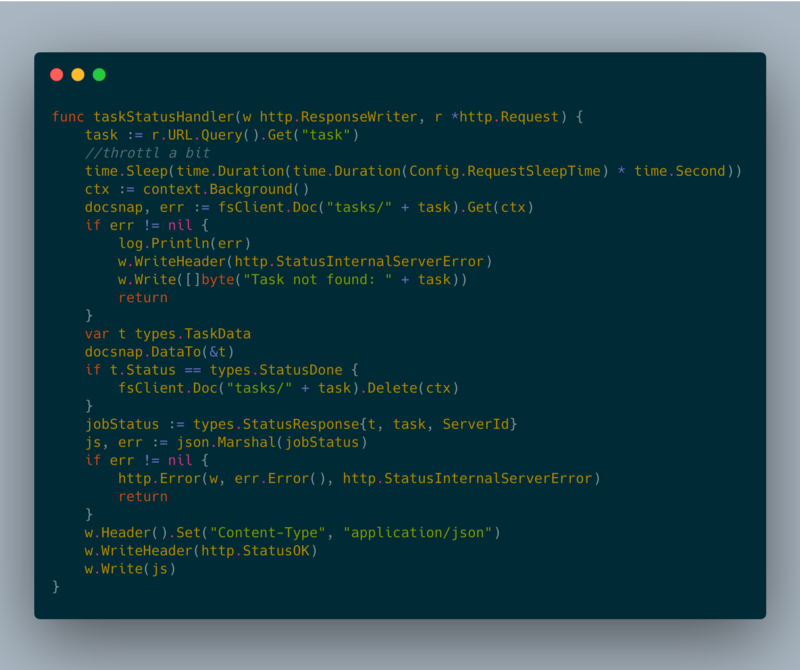 taskStatusHandler
taskStatusHandler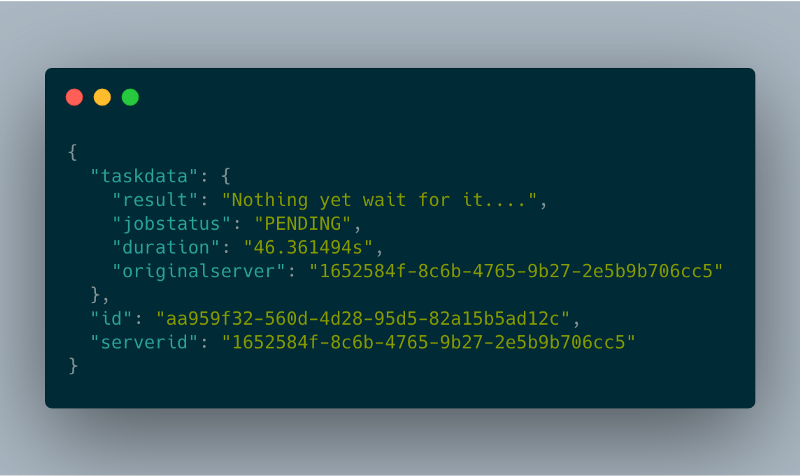 task status response
task status response
Damit mehr als eine Google-Cloud-Run-Instanz unterstützt wird, brauchte ich eine Persistenzschicht, über die sich die Task-Status teilen lassen. Ursprünglich wollte ich Google Cloud Memorystore [2] einsetzen, doch der ist aus Google Cloud Run heraus noch nicht erreichbar. Stattdessen nutze ich Google Cloud Firestore [3] als Persistenzschicht.
In meinen Tests konnte ich mehrere Hintergrund-Tasks deutlich länger als eine Stunde laufen lassen. Sämtliche Tests fanden auf der vollständig gemanagten Variante von Google Cloud Run statt.
Den vollständigen Quellcode finden Sie hier.
[1] https://medium.com/google-cloud/how-to-run-serverless-batch-jobs-on-google-cloud-ca45a4e33cb1 von Lak Lakshmanan.
[2] https://cloud.google.com/memorystore
[3] https://cloud.google.com/firestore
Lust auf mehr Beiträge? Schauen Sie in unseren Blog oder folgen Sie Aviv auf Twitter.