
Una visione personale su come sfruttare Google Cloud Run per funzioni che superano i 10–15 minuti

Google Cloud Run è una piattaforma di calcolo gestita che consente di eseguire container stateless richiamabili tramite richieste web o eventi Cloud Pub/Sub. Cloud Run è serverless: astrae completamente la gestione dell'infrastruttura, lasciandoti libero di concentrarti su ciò che conta davvero, ovvero costruire applicazioni di qualità. Si basa su Knative e permette di scegliere se eseguire i container in modalità completamente gestita oppure all'interno del proprio cluster Google Kubernetes Engine.
In qualità di cloud architect in DoiT International, mi capita spesso di collaborare con aziende che vogliono spostare parte dei propri workloads verso il serverless computing, e sono convinto che nel prossimo futuro sempre più workloads approderanno su servizi come Google Cloud Run.
L'uso di Google Cloud Run comporta però una limitazione non trascurabile: i task possono essere eseguiti per un massimo di 15 minuti sul servizio completamente gestito, oppure 10 minuti se si utilizza Google Cloud Run sul proprio cluster GKE. In linea generale non è un problema, dato che la maggior parte dei workloads non richiede tempi di elaborazione così lunghi; per alcuni workloads, però, può risultare davvero penalizzante.
Lak Lakshmanan ha pubblicato di recente una soluzione [1] per eseguire task in background tramite Google AI Platform, che rappresenta un'alternativa alle idee descritte in questo articolo.
Ho dedicato un po' di tempo a capire come usare Google Cloud Run per eseguire task in background di lunga durata, ed ecco cosa ne è venuto fuori.
Disclaimer — questa soluzione si basa su alcune ipotesi e osservazioni la cui validità non è garantita in ogni circostanza. Il codice non ha qualità production-grade, ma può fungere da framework per costruire un servizio in grado di eseguire task in background di lunga durata.
Ecco le mie ipotesi di partenza:
- Finché arrivano richieste, Cloud Run non spegnerà il container.
- Il load balancer distribuirà le richieste in arrivo in modo equo tra le istanze del servizio.
Ho sfruttato un pattern ben noto per gestire richieste lunghe tramite polling lato client. Quando un client richiede un'operazione, il server crea un worker in background e risponde con il codice HTTP 202 (accepted).
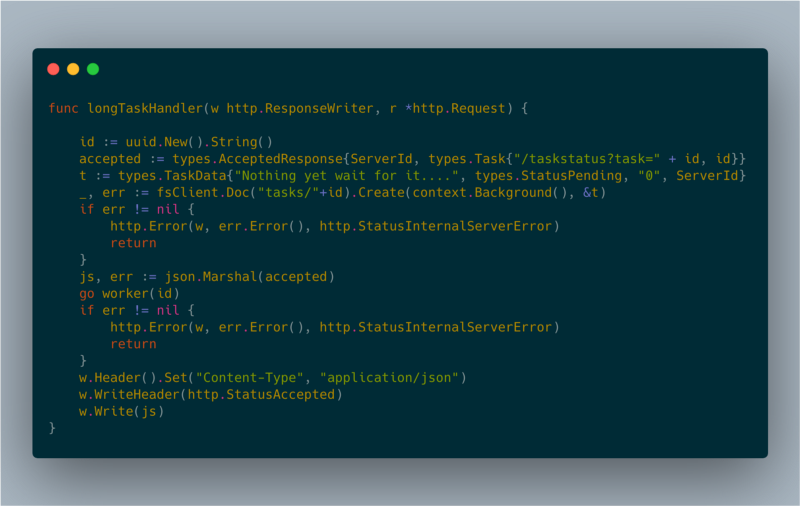 longTaskHandler
longTaskHandler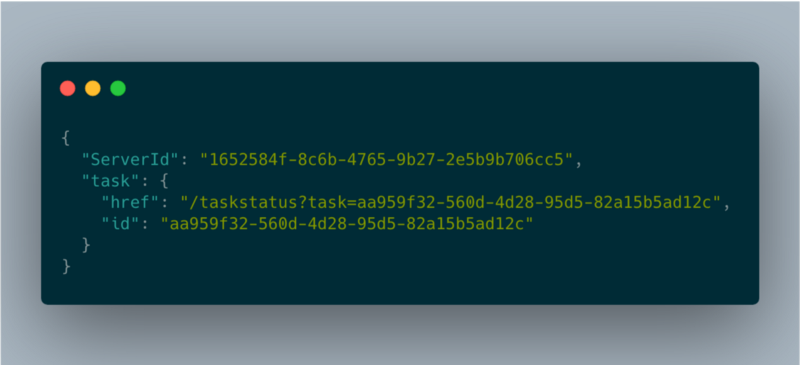 json response
json response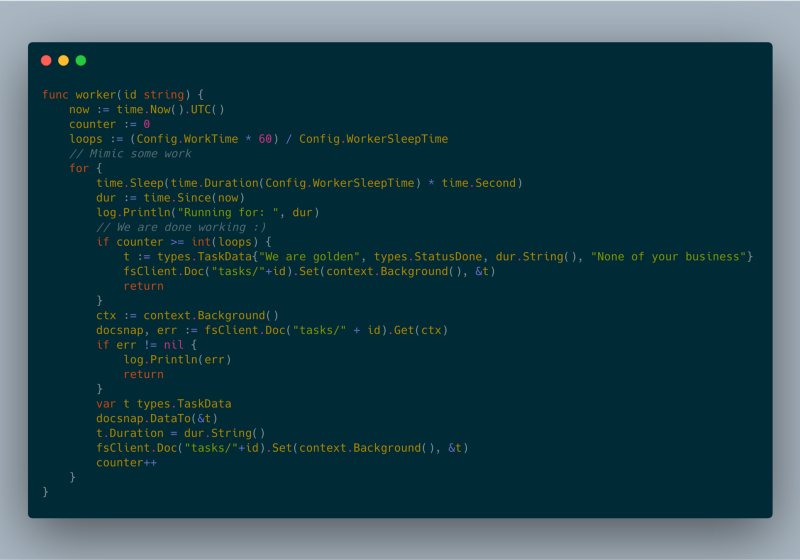 worker code
worker code
Il campo 'href' è quello che il client deve interrogare in polling per conoscere lo stato dell'operazione. Il client dovrà chiamare questo endpoint ogni pochi secondi per ottenere lo stato del job: in questo modo si garantisce anche che l'istanza resti attiva.
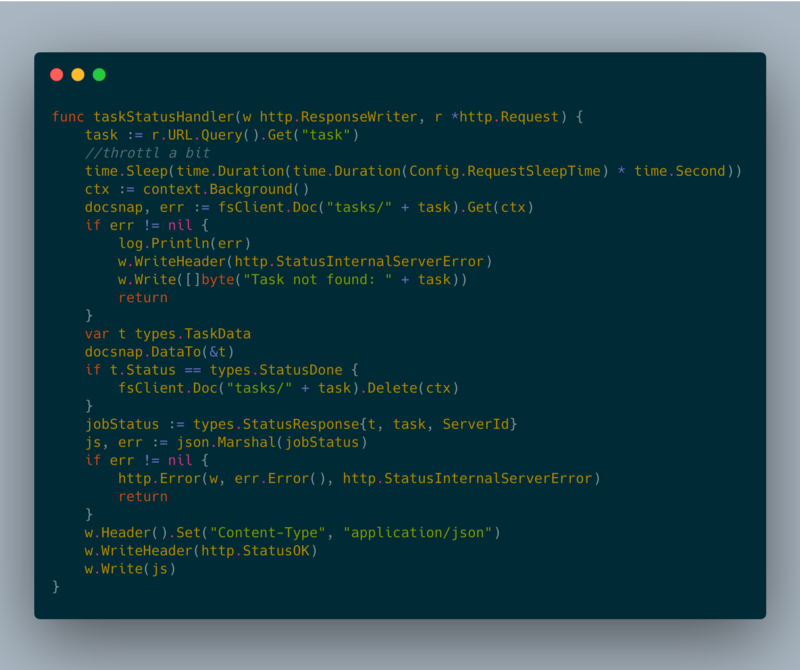 taskStatusHandler
taskStatusHandler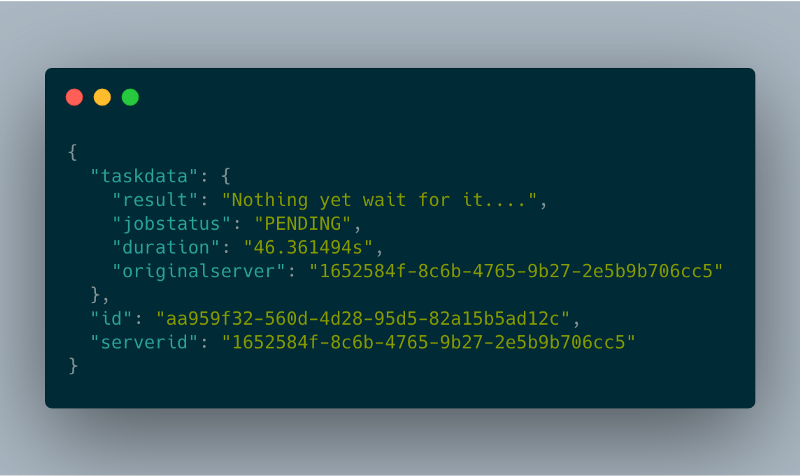 task status response
task status response
Per supportare più di un'istanza di Google Cloud Run serviva un layer persistente in cui condividere gli stati dei task. All'inizio volevo affidarmi a Google Cloud Memorystore [2], che però non è ancora accessibile da Google Cloud Run. Ho quindi optato per Google Cloud Firestore [3] come layer persistente.
Nei miei esperimenti sono riuscito a eseguire più task in background per ben oltre un'ora. Tutti i test sono stati condotti sulla versione completamente gestita di Google Cloud Run.
Il codice sorgente completo è disponibile qui.
[1] https://medium.com/google-cloud/how-to-run-serverless-batch-jobs-on-google-cloud-ca45a4e33cb1 di Lak Lakshmanan.
[2] https://cloud.google.com/memorystore
[3] https://cloud.google.com/firestore
Vuoi leggere altri articoli? Dai un'occhiata al nostro blog oppure segui Aviv su Twitter.