
Una visión personal sobre cómo usar Google Cloud Run para funciones que duran más de 10 a 15 minutos

Google Cloud Run es una plataforma de cómputo administrada que te permite ejecutar contenedores sin estado, invocables mediante solicitudes web o eventos de Cloud Pub/Sub. Cloud Run es serverless: abstrae toda la gestión de la infraestructura para que puedas concentrarte en lo que de verdad importa: crear grandes aplicaciones. Está basado en Knative y te deja elegir entre ejecutar tus contenedores de forma totalmente administrada o en tu propio cluster de Google Kubernetes Engine.
Como cloud architect en DoiT International, trabajo con muchas empresas que buscan migrar parte de sus workloads al cómputo serverless, y creo que en el futuro cercano cada vez más workloads se irán a servicios como Google Cloud Run.
Sin embargo, usar Google Cloud Run impone una limitación importante: tus tareas pueden ejecutarse hasta 15 minutos en el servicio totalmente administrado, o 10 minutos si usas Google Cloud Run sobre tu propio cluster de GKE. En general, esto no debería suponer un problema, ya que la mayoría de los workloads no requieren tiempos de procesamiento tan largos; sin embargo, para algunos workloads puede resultar muy limitante.
Lak Lakshmanan publicó hace poco una solución [1] para ejecutar tareas en segundo plano con Google AI Platform, que puede ser una alternativa a las ideas que describo en este artículo.
Dediqué un tiempo a explorar cómo aprovechar Google Cloud Run para ejecutar tareas largas en segundo plano, y esto es lo que descubrí.
Aviso — esta solución parte de algunos supuestos y observaciones que no siempre tienen por qué cumplirse. El código no tiene calidad de producción, pero puede servir como base para construir un servicio que ejecute tareas largas en segundo plano.
Estos son mis supuestos:
- Mientras haya solicitudes entrantes, Cloud Run no apagará el contenedor.
- El balanceador de carga repartirá las solicitudes entrantes de forma equitativa entre las instancias del servicio.
Aproveché un patrón muy conocido para gestionar solicitudes largas mediante polling del lado del cliente. Cuando el cliente pide una operación, el servidor crea un worker en segundo plano y responde con un código HTTP 202 (accepted).
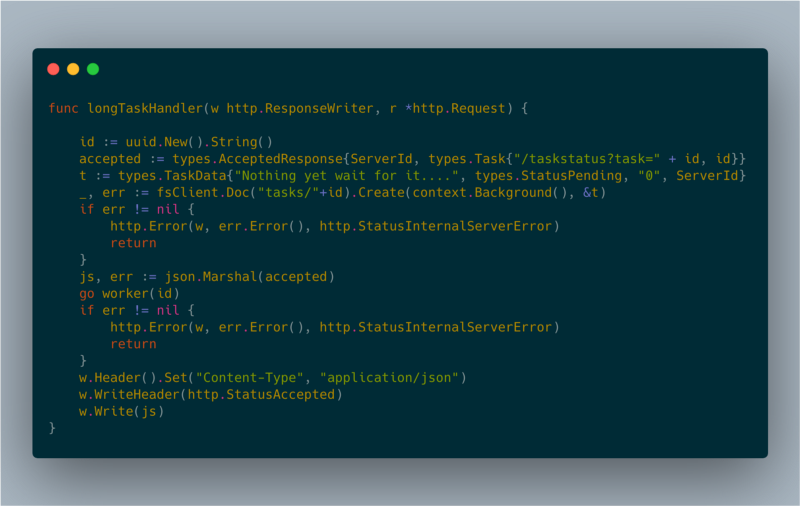 longTaskHandler
longTaskHandler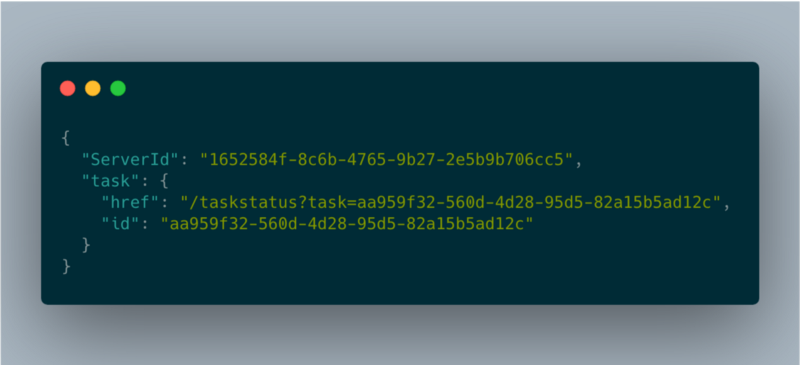 json response
json response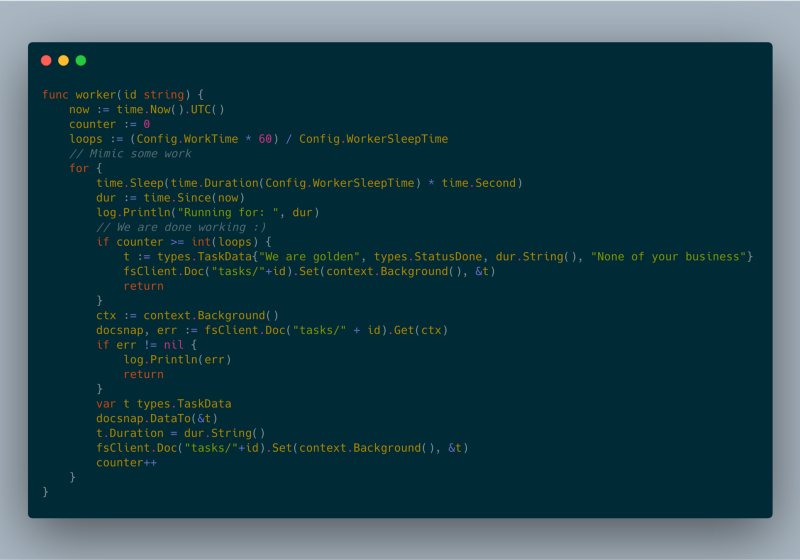 worker code
worker code
El campo "href" es el que el cliente debe consultar para obtener el estado de la operación. El cliente tendrá que llamar a este endpoint cada pocos segundos para conocer el estado del trabajo. Eso también sirve para confirmar que la instancia sigue activa.
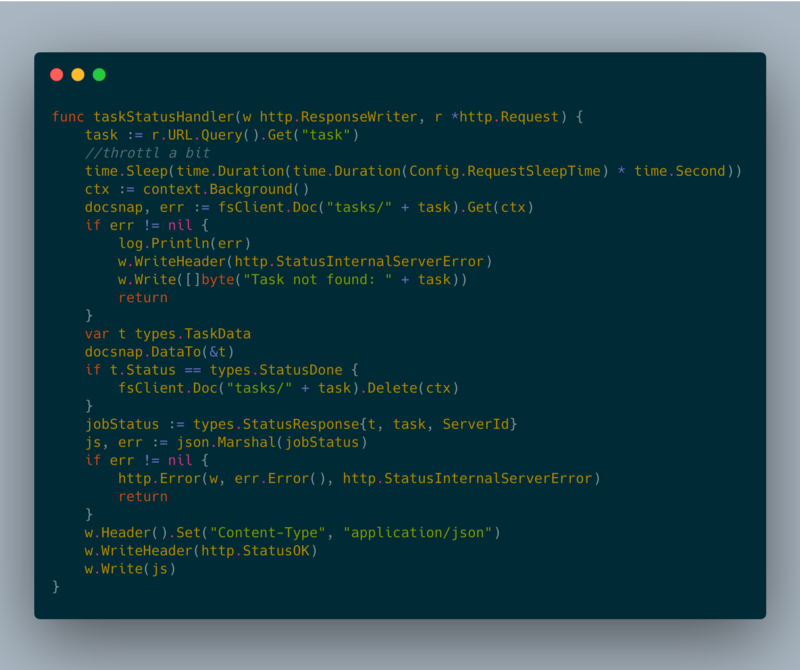 taskStatusHandler
taskStatusHandler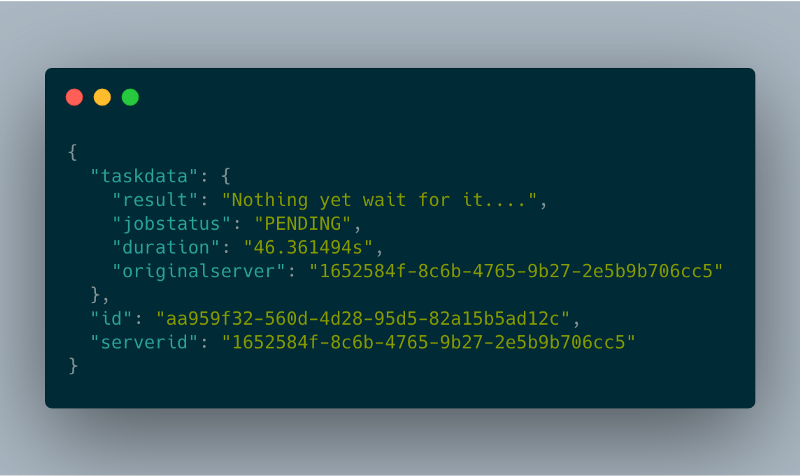 task status response
task status response
Para dar soporte a más de una instancia de Google Cloud Run, necesitaba algún tipo de capa persistente que permitiera compartir el estado de las tareas. En un inicio, mi idea era usar Google Cloud Memorystore [2]; sin embargo, todavía no es accesible desde Google Cloud Run. Por eso, estoy usando Google Cloud Firestore [3] como capa persistente.
En mis pruebas pude ejecutar varias tareas en segundo plano durante bastante más de una hora. Todas las pruebas se hicieron sobre la versión totalmente administrada de Google Cloud Run.
El código fuente completo está disponible aquí.
[1] https://medium.com/google-cloud/how-to-run-serverless-batch-jobs-on-google-cloud-ca45a4e33cb1 por Lak Lakshmanan.
[2] https://cloud.google.com/memorystore
[3] https://cloud.google.com/firestore
¿Quieres más artículos? Pasa por nuestro blog o sigue a Aviv en Twitter.