
Retour d'expérience sur l'utilisation de Google Cloud Run pour des fonctions qui dépassent 10 à 15 minutes

Google Cloud Run est une plateforme de calcul managée qui permet d'exécuter des conteneurs sans état, déclenchés par des requêtes web ou des événements Cloud Pub/Sub. Cloud Run est serverless : la plateforme prend en charge toute la gestion de l'infrastructure pour vous laisser vous concentrer sur l'essentiel — concevoir d'excellentes applications. Reposant sur Knative, elle vous laisse le choix d'exécuter vos conteneurs en mode entièrement managé ou dans votre propre cluster Google Kubernetes Engine.
En tant que cloud architect chez DoiT International, j'accompagne de nombreuses entreprises qui souhaitent migrer une partie de leurs workloads vers le calcul serverless, et je suis convaincu que dans un avenir proche, davantage de workloads tourneront sur des services comme Google Cloud Run.
Google Cloud Run impose toutefois une limitation sérieuse : vos tâches peuvent durer jusqu'à 15 minutes sur le service entièrement managé, ou 10 minutes si vous utilisez Google Cloud Run sur votre propre cluster GKE. En règle générale, cela ne pose pas problème, car la plupart des workloads ne demandent pas un traitement aussi long ; pour certains, cela peut néanmoins s'avérer très contraignant.
Lak Lakshmanan a récemment publié une solution [1] pour exécuter des tâches en arrière-plan via Google AI Platform, qui constitue une alternative aux idées décrites dans cet article.
J'ai pris le temps d'explorer comment utiliser Google Cloud Run pour exécuter de longues tâches en arrière-plan, et voici ce que j'ai découvert.
Avertissement — cette solution repose sur des hypothèses et des observations dont la validité n'est pas garantie en permanence. Le code n'est pas d'une qualité production, mais peut servir de base pour bâtir un service capable d'exécuter de longues tâches en arrière-plan.
Voici mes hypothèses :
- Tant que des requêtes entrantes parviennent au service, Cloud Run n'arrête pas le conteneur.
- Le load balancer répartit les requêtes entrantes de façon équitable entre les instances du service.
Je me suis appuyé sur un pattern bien connu pour gérer les requêtes longues via du polling côté client. Lorsqu'un client demande une opération, le serveur crée un worker en arrière-plan et répond avec un code HTTP 202 (accepted).
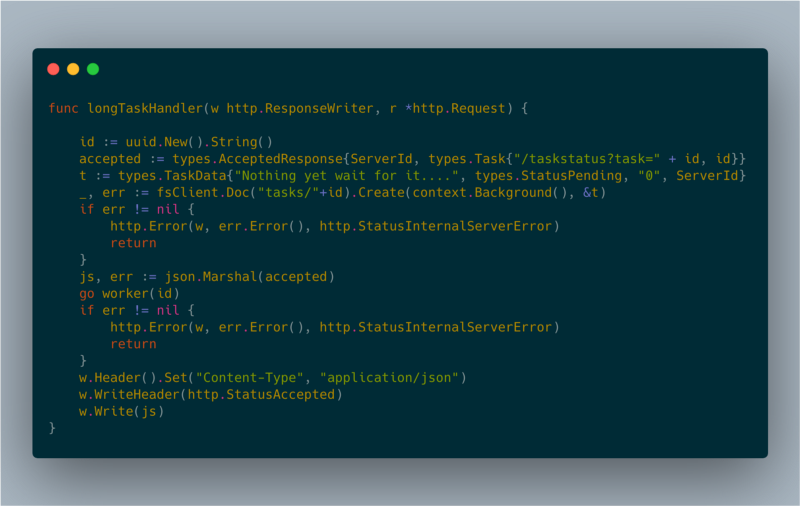 longTaskHandler
longTaskHandler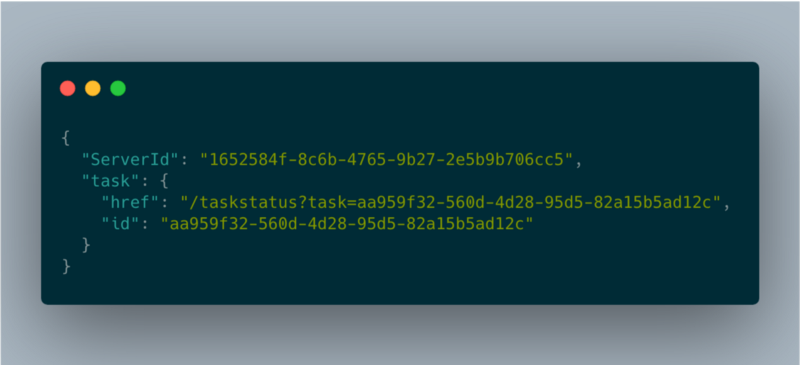 json response
json response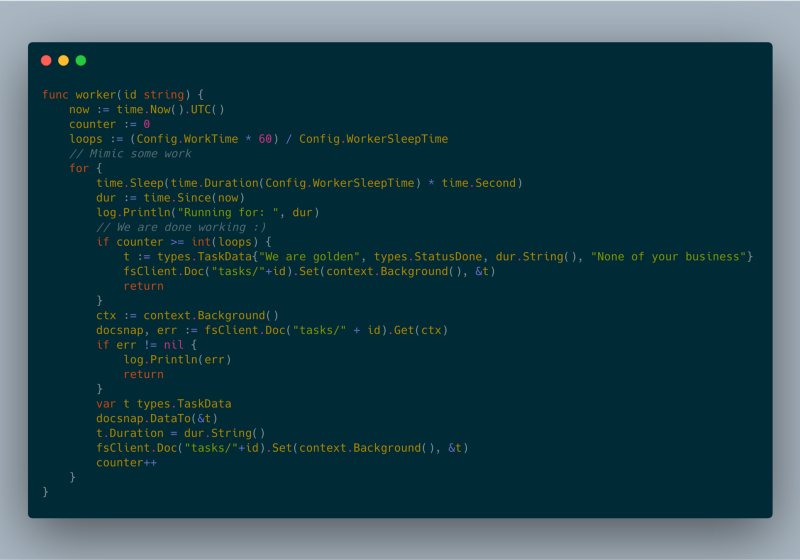 worker code
worker code
Le champ href est celui que le client doit interroger pour récupérer le statut de l'opération. Il devra appeler cet endpoint toutes les quelques secondes pour suivre l'état du job, ce qui garantit aussi que l'instance reste active.
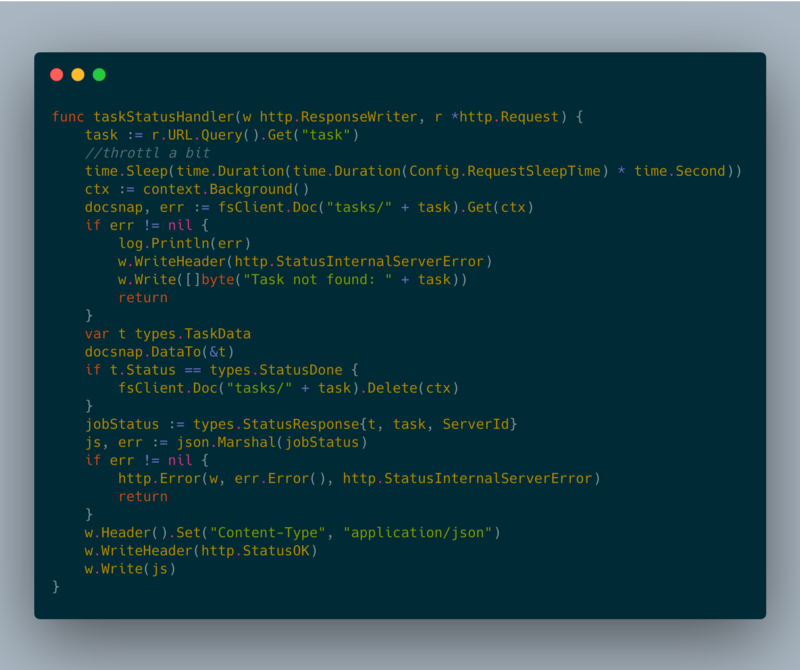 taskStatusHandler
taskStatusHandler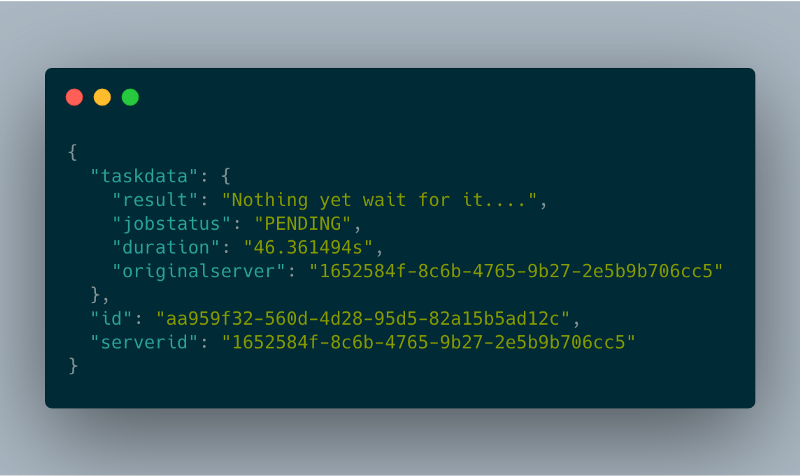 task status response
task status response
Pour prendre en charge plusieurs instances Google Cloud Run, il me fallait une couche de persistance afin de partager le statut des tâches. Au départ, je voulais utiliser Google Cloud Memorystore [2], mais ce service n'est pas encore accessible depuis Google Cloud Run. J'utilise donc Google Cloud Firestore [3] comme couche de persistance.
Lors de mes expérimentations, j'ai pu exécuter plusieurs tâches en arrière-plan pendant bien plus d'une heure. Tous nos tests ont été menés sur la version entièrement managée de Google Cloud Run.
Le code source complet est disponible ici.
[1] https://medium.com/google-cloud/how-to-run-serverless-batch-jobs-on-google-cloud-ca45a4e33cb1 par Lak Lakshmanan.
[2] https://cloud.google.com/memorystore
[3] https://cloud.google.com/firestore
Envie d'autres articles ? Consultez notre blog ou suivez Aviv sur Twitter.