アイデアから本番運用までの道のり — 画像はAWSコミュニティより
workloadへのLLM導入を始める方に向けた簡単なロードマップをご紹介します。アイデアから本番運用までの道のりは決して一直線ではなく、刺激に満ちた旅路です。本記事で解説する各ステージを把握すれば、いま自分がどの段階にいて、本番環境に到達するために次に何をすべきかが見えてきます。
本記事では6つのステージを定義し、それらすべてをつなぐ共通要素としてモニタリングとセキュリティを取り上げます。

各ステージ
アイデア創出
LLMを活用すれば、カスタマイズや個別化されたユーザー体験の可能性を大きく広げられます。LLMのユースケースを考える際は、一人ひとりの顧客体験を理解するために必要な具体的なデータポイントから発想を始めるのがよいでしょう。
いくつか例を見てみましょう。
- 監視カメラ画像からレンタカーの傷を認識できれば、貸出・返却プロセスを改善できる。
- どのサービスが顧客の継続利用に最も寄与するかが分かれば、パーソナライズされた継続施策を提供できる。
- 個々の履歴データから顧客ペルソナを特定できれば、専門的なアドバイスを提供できる。
このように、一般的な発想から出発し、個別の体験に基づく独自のアドバイス提供へと落とし込んでいきます。まずは以下のテンプレートを起点にアイデアを膨らませ、テンプレートの枠を超えた多様なユースケースへと広げてみてください。
- もし ____ の中の ______ を認識/解釈/特定できれば、____ ができる
- もし個々の _______ ごとに、どの ________ が __________ する可能性が高いか分かれば、____ ができる
- もし _______ をもとに ________ を特定できれば、_________ ができる
評価対象となるユースケースをいくつか作成しておきましょう。最初は実現が難しそうに見えるものでも、捨てずに残しておくことをおすすめします。技術の進展により、将来的に十分実現可能になる可能性があるためです。
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
データ評価
挙げたユースケースの中から、ROIが最も高そうなものを一つ選び、着手に必要なデータを洗い出していきましょう。必要なデータポイントが初回のイテレーションですべて出そろうとは限らず、後の段階に進んでから追加データの必要性に気づくこともあります。重要なのは、得られた知見をすべてドキュメント化し、今後の取り組みに活かすことです。
前のステージで挙げた例の一つを取り上げてみます。
- どのサービスが顧客の継続利用に最も寄与するかが分かれば、パーソナライズされた継続施策を提供できる。
予測を始めるには、どのデータが必要かを特定しなければなりません。ここで力を発揮するのがドメイン知識です。
この例であれば、サービスへのフィードバックやコメント、過去の購入履歴、サービスの閲覧・クリックといった顧客のインタラクションを洗い出すところから始めます。カスタマーサポートとのやり取りも有用ですし、顧客プロファイルの情報も活用できます。
この段階では、データを絞り込みすぎるよりも、むしろ多めに集めておく方が望ましいでしょう。テストを進める中で、削除可能なデータや、目的の結果を得るために追加で必要なデータが見えてきます。
バイアスの種類
データには、さまざまな種類のバイアスが入り込む可能性があります。代表的なものを挙げておきましょう。
Reporting Bias(報告バイアス) — データセット内のレコード頻度が現実世界の分布を正確に反映していないために、結果が偏ってしまう現象です。特定の事象や行動が学習データ内で過剰または過少に表現されると発生します。
Selection Bias(選択バイアス) — このバイアスを避けるには、データが対象母集団を適切に代表していることを確認しましょう。さまざまなデモグラフィック、コンテキスト、シナリオを網羅できるよう、多様なソースから幅広くデータを収集することが重要です。
Group Attribution Bias(集団帰属バイアス) — このバイアスを避けるには、学習データがすべての集団を多様かつバランスよく含んでいることを確認します。モデル出力にバイアスのあるパターンがないかを定期的に監査し、公平性指標を用いて集団間のパフォーマンスを評価しましょう。
モニタリングとセキュリティ
プロセスの早い段階から、workloadにセキュリティとモニタリングを組み込んでいきましょう。データパイプラインでセキュリティ統制を確実に満たすことが重要です。最小権限の原則に従い、データソースに対する監査統制も実施しましょう。
あわせて、データパイプラインのモニタリングを行うことで、データ整合性の問題や、機械学習出力の品質低下リスクを軽減できます。
最後に、バイアスのテストも忘れずに。データの代表性を測る指標の重要度を評価するテストを用意してください。本番環境で受け取るデータをきちんと代表できているか? PIIデータが含まれていないか? バイアスを生み得る他のデータが混入していないか? — これらを確認しましょう。
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
アーキテクチャ設計
適切な基盤モデルを選定するために、まずユースケースから出発しましょう。
Amazon Bedrockは、主要なAIプロバイダーが提供するさまざまな基盤モデルへのアクセスを提供しており、多様な生成AIユースケースに活用できます。
テキスト生成・要約、画像生成・識別、音声書き起こし・翻訳、エンベディングといった用途別に活用できるモデルを以下に紹介します。
1. テキスト生成・要約
テキストの生成や要約には、自然言語の理解と生成に対応したモデルを使用します。例えば次のとおりです。
- Anthropic Claude:要約、質問応答、対話など、高度なテキスト生成能力で知られています。
- Mistral Models: 汎用性が高く設計されており、生成や要約をはじめ、多様なテキストベースのタスクに対応します。
2. 画像生成・識別
画像の生成や識別には、コンピュータビジョンに特化したモデルが必要です。
- Stability AI Stable Diffusion:画像生成に最適で、テキストプロンプトから詳細かつ高品質な画像を生成できます。
- Amazon Rekognition(Bedrockには含まれませんが画像識別に関連):堅牢な画像識別、物体検出、顔分析機能を提供します。
3. 音声書き起こし・翻訳
音声をテキストに変換したり言語を翻訳したりするには、音声データの扱いに長けたモデルを使います。
- Amazon Transcribe(Bedrockには含まれませんが音声書き起こしに関連):音声を高精度にテキスト化します。
- Amazon Translate(Bedrockには含まれません):テキストをある言語から別の言語へ翻訳するサービスで、Amazon Transcribeと組み合わせればエンドツーエンドの音声翻訳が可能です。
- OpenAI Whisper foundation model:SageMaker JumpStartで利用可能。多言語の音声を非常に効率よくテキスト化する基盤モデルです。
4. エンベディング
エンベディング生成には次のモデルが活用できます。
- Amazon Titan Embeddings:テキストの密ベクトル表現(エンベディング)生成に特化しており、セマンティック検索、クラスタリング、レコメンデーションシステムなどに有用です。
BedrockではHugging Faceで提供されているような独自モデルやその他のモデルをSagemaker上で実行することも可能です。Bedrockがサポートするモデル一覧もあわせてご参照ください。
適切な基盤モデルを選定したら、次は適切なシステム設計を選びます。一つだけを選んでもよいですし、複数を組み合わせてシナリオに最適な結果を得ることもできます。
1. ダイレクト生成AIモデル
生成AIモデルが、入力から目的の出力を直接生成するように学習されたものです。国の首都名のような一般的な情報を求めるタスクでよく使われます。
2. RAG(Retrieval-Augmented Generation)アーキテクチャ
RAGは、検索ベースモデルと生成モデルの利点を組み合わせたアプローチです。まず知識ベースから関連ドキュメントを取得し、その情報を取り込みながら生成モデルが応答を作成します。
3. エージェントアーキテクチャ
この設計では、複数のAIモデル(エージェント)が相互にやり取りして最終的な出力を生成します。各エージェントはタスクの異なる側面に特化し、協調することでより複雑な出力を生み出します。
4. マルチモデルアーキテクチャ
複数のタスクを処理できる単一モデルを学習させるアプローチです。
タスク同士が関連していたり、情報が重なり合っていたりするシナリオで特に有効です。
アーキテクチャの選択は、プロジェクト固有の要件と制約によって決まります。
プロジェクトで活用できるAWSサービスは複数あります。
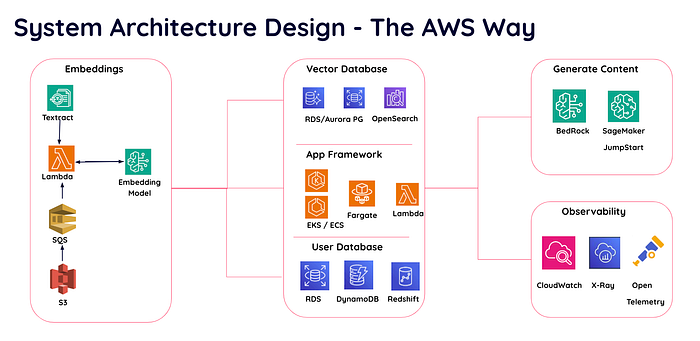
AWSサービスを用いたシステムアーキテクチャ設計
プロンプト設計
プロンプト設計は、AIモデルの出力品質と関連性を大きく左右する重要な工程です。よく練られたプロンプトは、モデルがより正確で文脈に即した有用な応答を生成できるよう導きます。重要な理由は次のとおりです。
1. 精度
プロンプトが明確で具体的であれば、モデルは何を求められているかを正確に理解でき、より精度の高い応答が得られます。
2. コンテキスト
よく設計されたプロンプトは必要なコンテキストを与え、モデルがより関連性が高く意味のある応答を生成できるようにします。ただしコンテキストサイズには上限があり、入力パラメータのトークン量に応じて課金されるモデルもあるため、追加コストが発生する場合があります。コンテキストトークンに対応していないモデルもあるので、選定時にサポート状況を必ず確認してください。
3. コントロール
モデルに特定のガイドラインを守らせたい場合、丁寧なプロンプト設計がモデルの挙動と出力をコントロールする鍵となります。
4. 効率性
優れたプロンプトは、何度も問い直す必要を減らし、モデルとのやり取りを効率化します。
5. ユーザー体験
練り込まれたプロンプトは、モデルから満足度の高い応答を引き出し、より良いユーザー体験につながります。
プロンプトの重要性が分かったところで、次のステップに進みましょう。
まずは、望ましい出力を定義することから始めます。たとえば「サンフランシスコでおすすめのイタリアンレストランを教えてください」というプロンプトに対しては、「もちろんです。サンフランシスコの『Trattoria Contadina』はイタリア料理の名店として高く評価されています。本格的な料理と居心地の良い雰囲気が特徴です。
看板メニューのパスタもぜひお試しください!」のような出力が考えられます。
望ましい出力に必要なコンテキストを特定する: AIモデルが正確で関連性のある応答を生成するために、どのような情報が必要かを把握する作業です。次のステップが参考になります。
1. タスクの理解:モデルに何をさせたいのか? 質問に答えるのか、テキストを生成するのか、それとも別のタスクを実行するのか? タスクの性質によって必要なコンテキストが決まります。
2. 重要な情報の特定:モデルがタスクを正しく実行するために、どのような情報が必要か? プロンプト内で提供する詳細、トピックに関する背景知識、ユーザーの好みや状況に関する情報などが該当します。
3. 依存関係の考慮:タスクの構成要素同士に依存関係はあるか? たとえば一連の質問への応答が求められるなら、モデルは過去の質問と回答を保持しておく必要があるかもしれません。
4. テストと反復:さまざまなプロンプトでモデルをテストし、どのような出力が得られるか確認します。出力が期待どおりでなければ、コンテキストを追加するか、プロンプトを明確にする必要があるかもしれません。
5. 異なるモデルでのテスト:最終結果に満足できない場合は、別のモデルもいくつか試して最適なものを選びましょう。
最終的なゴールは、モデルが望ましい出力を生成するのに十分なコンテキストを与えることです。ただし、与えすぎるとモデルが情報過多に陥り混乱しかねません。これは繊細なバランスであり、実験と反復を重ねて見つけていくものです。
望ましい出力を得るために、few-shot、Chain of Thought、マルチプロンプトなどの手法を使って2〜3パターンの優れたプロンプトを作成し、要件に最も合うものを選びましょう。
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
セキュリティ
プロンプト設計フェーズが完了したら、次はプロンプトインジェクションを抑えるためのセキュリティ対策に注力しましょう。ご存知の通り、プロンプトインジェクションは、攻撃者がモデルへの入力を操作し、制限された情報へのアクセスなど有害な出力を引き出すセキュリティリスクです。プロンプトインジェクションを軽減するための対策をいくつか紹介します。
1. 入力バリデーション:ユーザー入力に厳格な検証ルールを実装します。文字数制限、フォーマットチェック、特殊文字や有害となり得るキーワードのフィルタリングなどが含まれます。
2. サニタイゼーション:インジェクション攻撃に使われ得る文字を削除またはエスケープし、ユーザー入力をサニタイズします。これにより、入力の一部がコマンドや指示としてモデルに解釈されるのを防げます。
3. レート制限:同一ユーザーやIPアドレスからの高速・反復的なリクエストを抑えるため、レート制限を実装します。プロンプトインジェクションのブルートフォース試行への対策として有効です。
4. モニタリングとロギング:システムのアクティビティを監視し、ユーザー入力とモデル出力をログに残します。異常なパターンや攻撃の兆候の検出に役立ちます。
5. ユーザー教育:プロンプトインジェクションのリスクをユーザーに周知し、不審な挙動の報告を促しましょう。セキュリティ意識の文化を育むことにもつながります。
6. モデルの学習:有害となり得る入力を認識して拒否するようモデルを学習させます。言語の複雑さや誤検知のリスクから難易度は高いものの、防御の追加レイヤーとして有効です。
POC(概念実証)
プロジェクトで使えるマネージドサービスの情報がそろい、アーキテクチャへの理解も深まったところで、いよいよ実際のものづくりに移りましょう。
ここで活用したいのがAWS Amazon Bedrockです。基盤モデルを使った生成AIアプリケーションの構築・スケールを最も手軽に実現できる手段で、AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AIといった高性能モデルを揃えています。さらに、Knowledge Bases、Agents、Guardrailsなどのツールも提供されています。
Knowledge Bases for Amazon Bedrock: データソースへのカスタム連携を構築したりデータフローを管理したりすることなく、取り込みから検索、プロンプト拡張までRAGワークフロー全体を実装できる、フルマネージド機能です。
Agents for Amazon Bedrock: エージェントは、基盤モデル(FM)の推論能力を使ってタスクをオーケストレーション・分析し、適切な論理的シーケンスへ分解します。必要なAPIを自動的に呼び出して企業のシステムやプロセスとやり取りし、リクエストを実行。途中で先に進めるか、追加情報が必要かも判断します。
Guardrails for Amazon Bedrock: ユースケースとAIポリシーに基づき、アプリケーション固有の安全策を実装するためのツールです。
これらのツールがあれば、構築予定のシステムのプロトタイプを手軽に組み立てられます。アーキテクチャを試す絶好の出発点です。テストシナリオをいくつか用意して結果を確認し、さまざまなデータセットで試したり、複数のユーザーに使ってもらったりしましょう。この段階は楽しいフェーズで、賞賛や提案、建設的なフィードバックが集まります。必要なら原点に立ち戻り、モデルを修正したり、別のアーキテクチャやサービスを試して最適なものを選び直したりしましょう。なにしろ、これは直線的なプロセスではないのですから。
この段階で、オブザーバビリティとセキュリティ対策が一通り整っていることを確認しましょう。セキュリティは技術的な対策と人的要因の両方が絡む多層的なプロセスです。進化する脅威に追従するため、運用ルールを定期的に見直し、更新していくことが欠かせません。
そこで、オブザーバビリティとセキュリティの話題に移ります。
オブザーバビリティ
テキスト生成にLLMを使う場合は、次の指標で評価しましょう。
パープレキシティ(Perplexity)
確率モデルがサンプルをどれだけうまく予測できるかを測る指標です。言語モデルの文脈では、パープレキシティが低いほど次の単語の予測精度が高いことを意味します。学習プロセスでモデルの進捗を測るのによく使われます。
BLEU(Bilingual Evaluation Understudy)
機械生成された翻訳の品質を評価するための指標です。
機械翻訳に含まれる単語やフレーズが参照訳とどれだけ一致しているかを、適合率(機械翻訳の単語のうち参照訳に含まれる割合)と再現率(参照訳の単語のうち機械翻訳に含まれる割合)の両面から測ります。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
テキストの自動要約や機械翻訳を評価するための指標群です。
ROUGEには、システム生成の要約と参照要約の間でn-gram、単語列、単語ペアの重複を比較する指標が含まれます。
単語誤り率(Word Error Rate, WER)
音声認識や機械翻訳のタスクで一般的な指標です。システム出力を参照出力に変換するために必要な最小編集回数(挿入、削除、置換)を測ります。WERが低いほどシステムの精度が高いことを示します。
これらの指標はいずれもモデルのパフォーマンスを異なる角度から捉えるものなので、組み合わせて用いることでモデルの状態をより包括的に把握できます。
オブザーバビリティ — ユーザーアクション
出力への満足度
ユーザーから 👍 または 👎 のフィードバックを取得します。
ユーザーがモデル出力をコピーする
ユーザーがモデルの出力を頻繁にコピーしているかを観察しましょう。コピーが多いほど、出力が役立っていると感じている証拠です。
ユーザーが出力を再生成する
プロンプトを変えて何度も出力を再生成している場合は、出力に問題がある可能性があります。プロンプトを見直し、有用な出力が得られるよう調整しましょう。
ユーザーがモデルとやり取りする時間の長さ
多くのユーザーが短時間で会話を切り上げて離脱しているなら、モデルのパフォーマンスに満足していない可能性があります。その場合はモデルのパフォーマンスを改めて確認する必要があります。
さらなるセキュリティ対策
有害性評価(Toxicity Evaluation)
Comprehendを使えばテキストを分析し、その感情がポジティブ・ネガティブ・ニュートラル・混合のいずれに属するかを把握できます。これを有害性評価の一環として活用すれば、テキストに有害または否定的な内容が含まれているかを確認できます。より具体的な要件があれば、Amazon Comprehendのカスタム分類機能を使ってカスタムモデルを学習させる方法もあります。有害なテキストと無害なテキストの例を含むデータセットでモデルを学習させ、新しいテキストを有害性に基づいて分類できます。AWSの別サービスであるAmazon Transcribeにも、Toxicity Detectionという機能が用意されています。
GuardRail
Guardrailは、生成AIアプリケーションの安全性とプライバシー保護を構築・カスタマイズするためにAmazon Bedrockに用意されたツールです。Amazon Bedrock内のすべての大規模言語モデル(LLM)に加え、ファインチューニング済みモデルでも動作します。Guardrailにはルールを設定でき、複数のガードレールを並行して運用することも可能です。アプリケーションとモデルの間に位置し、アプリケーションからモデルへ送られる内容と、モデルからアプリケーションへ返される内容の両方を自動評価し、制限カテゴリーに該当するコンテンツを検出・抑止します。
カスタムエンティティ認識(Custom Entity Recognition)
Amazon Comprehendの機能の一つで、テキスト内のドメイン固有の用語を識別できます。
たとえば、製品名、金融エンティティ、ビジネスに関連する任意の用語など、特定の種類の情報を非構造化テキストドキュメントから抽出する用途に活用できます。
このサービスを使って特定のエンティティをフィルタリングし、データを保護できます。
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
ソリューションのスケール
モデルの量子化
量子化は、機械学習モデルのメモリと計算リソースを削減するためのプロセスです。モデルのメモリフットプリントを大幅に減らし、計算を高速化できますが、多くの場合、精度の大きな低下を伴いません。ただし精度の低下が完全にゼロというわけではないため、評価指標(ROUGE、BLEU、独自テストなど)を満たし続ける範囲で許容する、という考え方になります。
モデルのファインチューニング
ファインチューニングは、事前学習済みモデル(大規模データセットで学習済みのモデル)を、特定タスクの実行に向けて再学習させるプロセスです。事前学習で獲得した特徴を活かしつつ新しいタスクに合わせて調整するため、より少ないデータと計算リソースで済みます。効率向上、データ転送コストの削減、リソースのより良い活用に寄与します。
複数デプロイメント
オーケストレーションフレームワーク(LangChainなど)はシンプルに保ち、複雑なパイプラインは複数のデプロイメントに分けて処理しましょう。
大規模運用時のホスト型モデル vs APIモデルのコスト評価
必要な計算リソース:両オプションで必要な計算リソースを確認しましょう。ホスト型モデルではモデルを実行するサーバー(CPU/GPU)のコストが、APIモデルではAPI呼び出しごと、または計算時間単位ごとのコストが発生します。多くの場合トークン単位で課金され、トークン量は入力やコンテキストのサイズ、モデルによって異なります。
データ転送:ホスト型モデルではサーバーへのデータ送受信コストが、APIモデルではAPIへ送受信するデータのコストが発生します。
ストレージ:ホスト型モデルではモデルとデータを保存するコストが、APIモデルではAPI呼び出し前後のデータ保存コストが発生する場合があります。
メンテナンス:ホスト型モデルではサーバー管理、モデル更新、トラブルシューティングなど、相応のメンテナンスが求められる傾向があります。APIモデルではこれらをプロバイダーが担うため、メンテナンスコストを抑えられる可能性があります。
スケーリング:より多くのリクエストを捌くためにスケールアップが必要な場合、ホスト型モデルでは追加サーバーが必要となりコストが増えがちです。APIモデルはスケールしやすいものの、API呼び出し数に応じてコストが増加します。
レイテンシ:アプリケーションがリアルタイム応答を必要とする場合、ホスト型モデルの方が低レイテンシを実現しやすい傾向にあります。ただし、APIプロバイダーがユーザーに近いサーバーを持っていれば、APIモデルでも遜色のないレイテンシを実現できる場合もあります。
これらの要素を踏まえれば、両オプションの総所有コスト(TCO)を見積もれます。これにより、自社のユースケースにとってどちらがコスト効率に優れるかを明確に判断できます。
ただし、考慮すべきはコストだけではありません。パフォーマンス、柔軟性、既存システムとの統合のしやすさといった要素も忘れずに検討してください。
まとめ
本ブログでは、大規模言語モデル(LLM)をアイデアから本番運用へと進めるための6段階のプロセスを概説しました。
- アイデア創出 — LLMの能力を活用するためのユースケースとアイデアをブレインストーミングします。発想を促すテンプレートも紹介しました。
- データ評価 — 選択したユースケースを支えるために必要なデータを特定し、データに含まれ得るバイアスにも注意します。
- アーキテクチャ設計 — Amazon Bedrockから適切なAWSサービスと基盤モデルを選び、必要な機能を構築します。選択肢には、直接生成、検索拡張生成、エージェントベース、マルチモデルアーキテクチャなどがあります。
- プロンプト設計 — モデルを導いて望ましい出力品質を確保するため、プロンプトを丁寧に作り込みます。同時にプロンプトインジェクションのリスクを抑えるセキュリティ対策も検討します。
- 概念実証(POC) — Amazon BedrockのKnowledge Bases、Agents、Guardrailsといったツールを使ってプロトタイプを構築し、徹底的に検証します。
- オブザーバビリティとセキュリティ — モデルパフォーマンス(パープレキシティ、BLEU、ROUGEなど)とユーザーインタラクションを監視する仕組みを実装します。あわせて、有害性評価やカスタムエンティティ認識といったセキュリティ統制も組み込みましょう。プロセス全体を通じてモニタリングとセキュリティの観点を組み込むことの重要性を強調しています。さらに、モデルの量子化やファインチューニングといった技術、ホスト型モデルとAPIベースのアプローチのトレードオフ評価など、ソリューションをスケールさせるためのガイダンスも提供しています。
本ブログは、Eduardo Motaと私がDoiT Internationalのお客様向けに開催したウェビナーの内容を簡潔にまとめたものです。同氏は本記事の共著者です。
LLM活用への一歩を踏み出したい方は、ぜひお気軽にご相談ください!