De la idea a producción — Imagen de la comunidad de AWS
Aquí tienes un mapa breve para arrancar tu camino al implementar LLM en tu workload. Ir de la idea a producción es un recorrido apasionante y todo menos lineal. Las etapas que vamos a desglosar te van a permitir ubicar en qué punto del camino estás y cómo avanzar de una etapa a la siguiente hasta llegar a un entorno productivo.
Vamos a definir 6 etapas, conectadas todas entre sí por el monitoreo y la seguridad.

Etapas
Ideación
Las capacidades de los LLM nos permiten explorar a fondo el mundo de la personalización y de la experiencia individual del usuario. Al pensar en los casos de uso donde podemos aplicar LLM, empezamos a considerar los puntos de datos específicos que nos ayudan a entender el recorrido de cada cliente.
Veamos algunos ejemplos:
- Si pudiera reconocer rayones en autos a partir de imágenes de cámaras de vigilancia, podría mejorar el check-in y check-out de nuestros autos de alquiler.
- Si supiera qué servicios tienen mayor probabilidad de retener a un cliente, podría ofrecer promociones personalizadas para retenerlo.
- Si pudiera identificar el perfil del cliente con datos históricos individuales, podría brindar asesoría experta.
Como ves, partimos de un nivel general con el objetivo de ofrecer recomendaciones únicas basadas en experiencias individuales. Te invito a empezar con la siguiente plantilla para destrabar las ideas y luego ampliarlas a más casos de uso por fuera de estos moldes.
- Si pudiera reconocer/interpretar/identificar ______ en ____, podría ____
- Si supiera qué ________ tienen mayor probabilidad de __________ por cada ________ individual, podría ____
- Si pudiera identificar ________ con _______, podría _________
Crea unos cuantos casos de uso para evaluarlos más adelante. Aunque parezcan difíciles de abordar al inicio, consérvalos. Esos mismos casos pueden volverse viables en el futuro.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Evaluación de datos
Elige uno de los primeros casos de uso, quizá el que crees que tendrá el mejor ROI, e identifiquemos qué datos se requieren para empezar. No todos los puntos de datos necesarios se identifican en la primera iteración; puede que avances a etapas posteriores y descubras que hacen falta datos adicionales. Lo importante es documentar todos los hallazgos para que nos sirvan en iniciativas futuras.
Tomemos uno de los ejemplos de la etapa anterior.
- Si supiera qué servicios tienen mayor probabilidad de retener a un cliente, podría ofrecer promociones de retención personalizadas.
Necesitamos identificar qué datos se requieren para empezar a hacer una predicción. Aquí es donde entra en juego el conocimiento del dominio para ayudarnos a identificar los puntos de datos.
Para este ejemplo en particular, comenzamos identificando interacciones del cliente, como feedback o comentarios sobre el servicio, compras anteriores, vistas de servicios o clics. Cualquier interacción con soporte al cliente también suma. También podemos aprovechar la información del perfil del cliente.
En esta etapa es mejor tener datos de sobra que tratar de mantenerlos escasos y al mínimo. El proceso de pruebas nos permitirá identificar qué datos pueden eliminarse o si hace falta sumar otros para alcanzar los resultados deseados.
Tipos de sesgo
Hay varios tipos de sesgo que pueden colarse en tus datos. Estos son algunos a los que conviene estar atento.
Sesgo de reporte — Ocurre cuando la frecuencia de los registros en un dataset no refleja con precisión las distribuciones del mundo real, lo que genera resultados desviados o sesgados. Esta discrepancia surge cuando ciertos eventos o comportamientos están sobre o subrepresentados en los datos de entrenamiento.
Sesgo de selección — Para evitarlo, asegúrate de que los datos sean representativos de la población objetivo. Esto implica recopilar datos diversos y completos de distintas fuentes para cubrir diferentes perfiles demográficos, contextos y escenarios.
Sesgo de atribución grupal — Para evitarlo, asegúrate de que tus datos de entrenamiento incluyan representaciones diversas y equilibradas de todos los grupos. Audita con regularidad las salidas del modelo en busca de patrones sesgados y usa métricas de equidad para evaluar el desempeño en distintos grupos.
Monitoreo y seguridad
Desde el inicio del proceso vamos a incorporar seguridad y monitoreo a nuestro workload. Es clave asegurar que se cumplen los controles de seguridad en el pipeline de datos. Sigue los principios de mínimo privilegio y los controles de auditoría sobre la fuente de datos.
Además, monitorea tus pipelines de datos para reducir la posibilidad de problemas de integridad y el riesgo de que se deteriore la calidad de la salida del machine learning.
Por último, haz una prueba de sesgo. Crea una prueba para evaluar la importancia de las métricas en la representación de los datos. ¿Tus datos representan los datos productivos que vas a recibir? ¿Estás incluyendo datos PII? ¿Estás incluyendo cualquier otro dato que pueda introducir un sesgo?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Diseño de la arquitectura
Empecemos por tu caso de uso para seleccionar el foundation model adecuado.
Amazon Bedrock brinda acceso a varios foundation models de los principales proveedores de IA, útiles para distintos casos de uso de IA generativa.
Estos son los modelos que pueden usarse para casos específicos como generación/resumen de texto, generación/identificación de imágenes, transcripción/traducción de audio y embeddings:
1. Generación/resumen de texto
Para tareas como generar o resumir texto, puedes usar modelos capaces de entender y generar lenguaje natural. Algunos ejemplos:
- Anthropic Claude: reconocido por sus capacidades avanzadas de generación de texto, incluyendo resumen, respuesta a preguntas y diálogo.
- Mistral Models: diseñados para ser versátiles y manejar diversas tareas basadas en texto, incluyendo generación, resumen y más.
2. Generación/identificación de imágenes
Para generar o identificar imágenes, necesitas modelos especializados en visión por computadora:
- Stability AI Stable Diffusion: ideal para la generación de imágenes; capaz de crear imágenes detalladas y de alta calidad a partir de prompts de texto.
- Amazon Rekognition (no forma parte de Bedrock, pero es relevante para la identificación de imágenes): ofrece capacidades robustas de identificación de imágenes, detección de objetos y análisis facial.
3. Transcripción/traducción de audio
Para convertir audio a texto o traducir idiomas, conviene usar modelos especializados en audio:
- Amazon Transcribe (no forma parte de Bedrock, pero es relevante para la transcripción de audio): convierte voz a texto con precisión.
- Amazon Translate: (no forma parte de Bedrock) para traducir texto de un idioma a otro; puede combinarse con Amazon Transcribe para una traducción de audio de extremo a extremo.
- Foundation model OpenAI Whisper: disponible en SageMaker JumpStart. Un foundation model que transcribe audio a texto de forma muy eficiente en varios idiomas.
4. Embeddings
Para generar embeddings:
- Amazon Titan Embeddings: especializado en crear representaciones vectoriales densas (embeddings) de texto, útiles para búsqueda semántica, clustering y sistemas de recomendación.
Con Bedrock es posible ejecutar tu propio modelo o cualquier otro modelo en SageMaker, como todos los disponibles en Huggingface. Aquí está la referencia a los modelos soportados en Bedrock.
Una vez que hayas seleccionado el foundation model adecuado, el siguiente paso es elegir el diseño de sistema apropiado. Puedes elegir uno o combinar varios para obtener los resultados que necesitas en tu escenario.
1. Modelo GenAI directo
Aquí, el modelo de IA generativa se entrena para generar directamente la salida deseada a partir de la entrada. Suele usarse en tareas que requieren información general, como la capital de un país.
2. Arquitectura RAG (Retrieval-Augmented Generation)
RAG combina los beneficios de los modelos basados en recuperación y los generativos. Primero recupera documentos relevantes de una base de conocimiento y luego usa un modelo generativo para crear una respuesta que incorpora la información recuperada.
3. Arquitectura de agentes
En este diseño, varios modelos de IA (agentes) interactúan entre sí para generar la salida final. Cada agente se especializa en un aspecto distinto de la tarea y colaboran para producir un resultado más complejo.
4. Arquitectura multi-modelo
Implica entrenar un único modelo capaz de manejar múltiples tareas.
Es particularmente útil en escenarios donde las tareas están relacionadas o tienen información en común.
La elección de la arquitectura depende de los requisitos y limitaciones específicos de tu proyecto.
Hay varios servicios de AWS que puedes usar en tu proyecto.
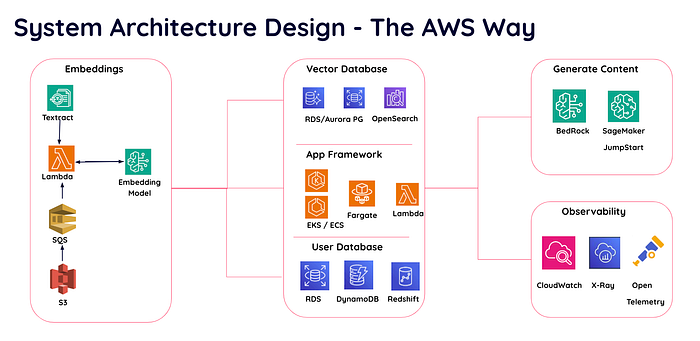
Diseño de arquitectura del sistema con servicios de AWS
Diseño de prompts
El diseño de prompts es importante porque influye en la calidad y relevancia de la salida del modelo de IA. Un prompt bien diseñado puede guiar al modelo para que entregue respuestas más precisas, contextualmente apropiadas y útiles. Es esencial por las siguientes razones:
1. Precisión:
Si tu prompt es claro y específico, le ayuda al modelo a entender exactamente qué se le pide, lo que se traduce en respuestas más precisas.
2. Contexto:
Un prompt bien diseñado aporta el contexto necesario para que el modelo genere respuestas más relevantes y significativas. Ten en cuenta que el tamaño del contexto es limitado y, con algunos modelos, también implica costos extra, ya que se aplican al tamaño de tokens de los parámetros de entrada. Cuando elijas un modelo, asegúrate de que soporte el contexto, ya que no todos admiten tokens de contexto.
3. Control:
Cuando necesitas que el modelo siga ciertos lineamientos, un diseño cuidadoso del prompt ayudará a guiar su comportamiento y su salida.
4. Eficiencia:
Un buen prompt puede reducir la necesidad de aclaraciones de ida y vuelta, haciendo más eficiente la interacción con el modelo.
5. Experiencia del usuario:
Por último, los prompts bien diseñados contribuyen a una mejor experiencia del usuario, ya que permiten al modelo entregar respuestas satisfactorias.
Ahora que conocemos la importancia de un prompt bien diseñado, es momento de enfocarnos en los siguientes pasos.
Empieza por definir la salida deseada. Por ejemplo, ante un prompt como "¿Puedes recomendarme un buen restaurante italiano en San Francisco?", una salida adecuada podría ser: "Claro, 'Trattoria Contadina' en San Francisco es altamente recomendable para cocina italiana. Es conocido por sus platillos auténticos y su ambiente acogedor.
¡No dejes de probar su pasta estrella!"
Identificar el contexto requerido para una salida deseada: esto implica entender qué información necesita el modelo de IA para generar una respuesta precisa y relevante. Estos son algunos pasos para ayudarte a identificar el contexto requerido:
1. Comprende la tarea: ¿qué se supone que debe hacer el modelo? ¿Responder una pregunta, generar un texto o ejecutar otra tarea? La naturaleza de la tarea determinará qué contexto se necesita.
2. Identifica la información clave: ¿qué información necesita conocer el modelo para realizar la tarea correctamente? Pueden ser detalles incluidos en el prompt, conocimiento de fondo sobre el tema o información sobre las preferencias o la situación del usuario.
3. Considera las dependencias: ¿hay dependencias entre distintas partes de la tarea? Por ejemplo, si la tarea es responder a una serie de preguntas, el modelo podría necesitar recordar preguntas y respuestas previas.
4. Prueba e itera: por último, pon a prueba el modelo con distintos prompts y observa qué tipo de salida genera. Si no es la deseada, quizá debas aportar más contexto o aclarar el prompt.
5. Prueba con diferentes modelos: si el resultado final no es satisfactorio, conviene probar con algunos modelos más para elegir el mejor.
El objetivo final es ofrecer suficiente contexto para que el modelo genere la salida deseada, pero no tanto que termine abrumado o confundido. Es un equilibrio delicado que suele requerir experimentación e iteración.
Para obtener la salida deseada, crea de 2 a 3 de los mejores prompts con técnicas de few-shot, chain-of-thought o multi-prompt, y elige el que mejor se ajuste a tus requerimientos.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Seguridad
Una vez completada la fase de diseño de prompts, enfócate en las medidas de seguridad para mitigar la inyección de prompts. Como ya sabes, la inyección de prompts es un riesgo de seguridad en el que un atacante manipula la entrada del modelo para producir salidas dañinas, como acceder a información restringida. Aquí algunas medidas para mitigarla.
1. Validación de entradas: implementa reglas estrictas de validación para las entradas del usuario. Esto puede incluir restricciones de longitud, comprobaciones de formato y filtrado de caracteres especiales o palabras clave potencialmente dañinas.
2. Sanitización: sanitiza las entradas del usuario para eliminar o escapar caracteres que podrían usarse en ataques de inyección. Esto ayuda a evitar que el modelo interprete parte de la entrada como un comando o una instrucción.
3. Rate limiting: implementa rate limiting para evitar solicitudes rápidas y repetidas desde un mismo usuario o dirección IP. Esto ayuda a mitigar intentos de fuerza bruta de inyección de prompts.
4. Monitoreo y logging: monitorea la actividad del sistema y registra las entradas del usuario y las salidas del modelo. Esto te ayuda a detectar patrones inusuales o señales de un ataque.
5. Educación del usuario: educa a los usuarios sobre los riesgos de la inyección de prompts y anímalos a reportar cualquier actividad sospechosa. Esto ayuda a crear una cultura de concientización sobre seguridad.
6. Entrenamiento del modelo: entrena tu modelo para reconocer y rechazar entradas potencialmente dañinas. Puede ser desafiante por la complejidad del lenguaje y el riesgo de falsos positivos, pero puede sumar como una capa adicional de defensa muy efectiva.
POC (Prueba de concepto)
Ahora que tenemos información sobre los servicios administrados disponibles para el proyecto y entendemos bien las arquitecturas, es hora de construir algo emocionante.
Podemos aprovechar AWS Amazon Bedrock; es la forma más sencilla de construir y escalar aplicaciones de IA generativa con foundation models. Ofrece varios modelos de alto desempeño como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI y Stability AI. También brinda diversas herramientas como Knowledge Bases, Agents y Guardrails.
Knowledge Bases for Amazon Bedrock: es una capacidad totalmente administrada que te ayuda a implementar todo el flujo RAG, desde la ingesta hasta la recuperación y la ampliación del prompt, sin necesidad de construir integraciones personalizadas con fuentes de datos ni gestionar flujos de datos.
Agents for Amazon Bedrock: los agentes orquestan y analizan la tarea y la descomponen en la secuencia lógica correcta utilizando las capacidades de razonamiento del foundation model. Los agentes llaman automáticamente a las APIs necesarias para interactuar con los sistemas y procesos de la empresa y cumplir la solicitud, determinando sobre la marcha si pueden continuar o si necesitan recopilar más información.
Guardrails for Amazon Bedrock: se usan para implementar salvaguardas específicas de la aplicación con base en tus casos de uso y políticas de IA.
Con estas herramientas es fácil empezar y construir un prototipo del sistema que planeas desarrollar. Es un buen punto de partida para probar nuestra arquitectura. Ten algunos escenarios de prueba para verificar los resultados. Pruébalo con diferentes datasets y pídele a distintos usuarios que lo pongan a prueba. Esta parte es emocionante. Recibirás elogios, sugerencias y feedback constructivo. Si hace falta, vuelve al pizarrón, modifica el modelo, prueba arquitecturas y servicios distintos y selecciona los más apropiados. Después de todo, no es un proceso lineal.
En este punto puedes asegurarte de que todas las medidas de observabilidad y seguridad estén en su lugar. La seguridad es un proceso multicapa que involucra tanto medidas técnicas como factores humanos. Es importante revisar y actualizar regularmente tus prácticas de seguridad para estar al día con las amenazas en evolución.
Y eso nos lleva a la observabilidad y la seguridad.
Observabilidad
Si estás usando un LLM para generación de texto, evalúa con base en lo siguiente:
Perplejidad:
Es una medida de qué tan bien un modelo probabilístico predice una muestra. En el contexto de los modelos de lenguaje, una menor perplejidad significa que el modelo es mejor para predecir la siguiente palabra en una secuencia. Suele usarse durante el proceso de entrenamiento para medir el progreso del modelo.
BLEU (Bilingual Evaluation Understudy):
Es una métrica utilizada para evaluar la calidad de las traducciones generadas por máquinas.
Mide cuántas palabras o frases de la traducción de la máquina coinciden con una traducción de referencia, considerando tanto la precisión (cuántas palabras de la traducción de la máquina están en la referencia) como el recall (cuántas palabras de la referencia están en la traducción de la máquina).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
Es un conjunto de métricas usadas para evaluar el resumen automático de textos, así como la traducción automática.
ROUGE incluye medidas para comparar la coincidencia de n-gramas, secuencias de palabras y pares de palabras entre el resumen generado por el sistema y un conjunto de resúmenes de referencia.
Word Error Rate (WER):
Es una métrica común para tareas de reconocimiento de voz y traducción automática. Mide el número mínimo de ediciones (inserciones, eliminaciones o sustituciones) necesarias para transformar la salida del sistema en la salida de referencia. Un WER más bajo indica un sistema más preciso.
Cada una de estas métricas ofrece una perspectiva distinta del desempeño del modelo y suelen usarse en conjunto para tener una visión más completa de qué tan bien está funcionando.
Observabilidad — Acciones del usuario
Satisfacción con la salida:
Obtén feedback del usuario 👍 o 👎
El usuario copia la salida del modelo:
Observa si los usuarios copian la salida del modelo con frecuencia. Eso es señal de que la encuentran útil.
El usuario regenera la salida:
Si notas que los usuarios regeneran la salida una y otra vez cambiando el prompt, ese comportamiento puede deberse a salidas defectuosas. Revisa los prompts para asegurarte de que produzcan salidas útiles.
Cuánto tiempo interactúa un usuario con el modelo:
Si varios usuarios pasan poco tiempo conversando con el modelo y se van de forma abrupta, quizá no estén satisfechos con su desempeño. En ese caso, deberás revisar el rendimiento del modelo.
Más medidas de seguridad
Evaluación de toxicidad:
Puedes usar Comprehend para analizar texto y entender su sentimiento, ya sea positivo, negativo, neutral o mixto. Esto puede formar parte de la evaluación de toxicidad para entender si el texto contiene contenido dañino o negativo. Si tus requerimientos son más específicos, podrías necesitar entrenar un modelo personalizado usando la función de clasificación personalizada de Amazon Comprehend. Puedes entrenar el modelo con un dataset que incluya ejemplos de texto tóxico y no tóxico, y luego usarlo para clasificar texto nuevo según su toxicidad. Amazon Transcribe, otro servicio de AWS, ha introducido una función llamada Toxicity Detection.
GuardRail:
Guardrail es una herramienta incluida en Amazon Bedrock para construir y personalizar protecciones de seguridad y privacidad para una aplicación de IA generativa. Funciona con todos los large language models (LLMs) en Amazon Bedrock, así como con modelos afinados (fine-tuned). Puedes configurar reglas en Guardrail y establecer múltiples guardrails. Se ubica entre la aplicación y el modelo, y evalúa automáticamente todo lo que entra al modelo desde la aplicación y todo lo que sale del modelo hacia la aplicación, para detectar y ayudar a prevenir contenido que caiga en categorías restringidas.
Reconocimiento de entidades personalizadas:
Es una función de Amazon Comprehend. Permite identificar términos específicos de tu dominio en el texto.
Por ejemplo, podrías usar Custom Entity Recognition para extraer tipos específicos de información de documentos de texto no estructurado, como nombres de productos, entidades financieras o cualquier término relevante para tu negocio.
Puedes usar este servicio para filtrar ciertas entidades y proteger tus datos.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Escala la solución:
Cuantización de modelos:
La cuantización es un proceso utilizado para reducir los requisitos de memoria y cómputo de los modelos de machine learning. Puede reducir significativamente la huella de memoria del modelo y acelerar los cálculos, a menudo sin una pérdida significativa de precisión. Sin embargo, hay que considerar que existe una pérdida de precisión, aceptada siempre que tus métricas de evaluación se sigan cumpliendo (por ejemplo, ROUGE, BLEU o pruebas propias).
Fine-tuning de modelos:
El fine-tuning es un proceso en el que un modelo preentrenado (un modelo que ya fue entrenado con un dataset grande) se entrena para realizar una tarea específica. Así podemos aprovechar las características aprendidas por el modelo preentrenado y ajustarlas a la nueva tarea, usando menos datos y recursos de cómputo. El fine-tuning ayuda a mejorar la eficiencia, reducir el costo de transferencia de datos y aprovechar mejor los recursos.
Múltiples despliegues:
Mantén el framework de orquestación (por ejemplo, LangChain) simple y crea múltiples despliegues para manejar pipelines complejos.
Evalúa el costo del modelo hospedado vs. modelo por API a muy gran escala:
Recursos de cómputo requeridos: revisa los recursos de cómputo necesarios para ambas opciones. Para un modelo hospedado, esto incluye el costo de los servidores (CPUs/GPUs) necesarios para ejecutarlo. Para un modelo por API, incluye el costo por llamada a la API o por unidad de tiempo de cómputo. Suele medirse en tokens, y la cantidad de tokens depende del tamaño de entrada, del contexto y del modelo.
Transferencia de datos: para un modelo hospedado, incluye el costo de transferir datos hacia y desde el servidor. Para un modelo por API, incluye el costo de los datos enviados y recibidos a través de la API.
Almacenamiento: para un modelo hospedado, incluye el costo de almacenar el modelo y los datos. Para un modelo por API, podría incluir el costo de almacenar datos antes y después de las llamadas a la API.
Mantenimiento: un modelo hospedado puede requerir más mantenimiento, incluyendo gestión de servidores, actualizaciones del modelo y resolución de problemas. Un modelo por API puede tener costos de mantenimiento más bajos, ya que el proveedor se encarga de estas tareas.
Escalado: si tu aplicación necesita escalar para manejar más solicitudes, un modelo hospedado podría requerir más servidores, lo que aumenta los costos. Un modelo por API puede escalar con más facilidad, pero los costos crecerán con el número de llamadas.
Latencia: si tu aplicación requiere respuestas en tiempo real, un modelo hospedado puede ofrecer menor latencia. Sin embargo, si el proveedor de la API tiene servidores cerca de tus usuarios, un modelo por API podría ofrecer una latencia comparable.
Después de considerar estos factores, puedes estimar el costo total de propiedad (TCO) para ambas opciones. Esto te dará una imagen más clara de cuál opción es más rentable para tu caso de uso específico.
Sin embargo, el costo no es el único factor a considerar. Toma en cuenta también factores como el desempeño, la flexibilidad y la facilidad de integración con tus sistemas existentes.
Resumen:
Este blog describe un proceso de 6 etapas para ir de la idea a producción con large language models (LLMs):
- Ideación — Haz brainstorming de casos de uso e ideas para aprovechar las capacidades de los LLM. El documento ofrece una plantilla para ayudarte a generar ideas.
- Evaluación de datos — Identifica los datos requeridos para soportar el caso de uso seleccionado, atento a posibles sesgos en los datos.
- Diseño de la arquitectura — Elige los servicios de AWS y los foundation models adecuados de Amazon Bedrock para construir la funcionalidad requerida. Las opciones incluyen generación directa, retrieval-augmented generation, basadas en agentes y arquitecturas multi-modelo.
- Diseño de prompts — Diseña los prompts con cuidado para guiar al modelo y asegurar la calidad deseada en la salida, considerando también medidas de seguridad para mitigar el riesgo de inyección de prompts.
- Prueba de concepto (POC) — Construye un prototipo usando herramientas de Amazon Bedrock como Knowledge Bases, Agents y Guardrails, y pruébalo a fondo.
- Observabilidad y seguridad — Implementa medidas para monitorear el desempeño del modelo (p. ej., perplejidad, BLEU, ROUGE) y las interacciones de los usuarios. Incorpora también controles de seguridad como evaluación de toxicidad y reconocimiento de entidades personalizadas. Se enfatiza la importancia de incorporar consideraciones de monitoreo y seguridad a lo largo de todo el proceso. También se brinda orientación para escalar la solución, con técnicas como la cuantización y el fine-tuning de modelos, así como la evaluación de los trade-offs entre un modelo hospedado y un enfoque basado en API.
Este blog es un breve resumen de un webinar que Eduardo Mota y yo hicimos para los clientes de DoiT International. Él es coautor de esta publicación.
Si quieres comenzar tu camino con LLM, ¡conversemos!