Dall'ideazione alla produzione — Immagine dalla community AWS
Ecco una breve mappa per avviare l'implementazione di un LLM nei suoi workloads. Il percorso dall'ideazione alla produzione è entusiasmante e tutt'altro che lineare. Le fasi che analizzeremo le permetteranno di capire a che punto si trova e come passare da una all'altra fino a raggiungere l'ambiente di produzione.
Definiremo 6 fasi, con monitoraggio e sicurezza come fili conduttori che le collegano tutte.

Le fasi
Ideazione
Le potenzialità degli LLM ci permettono di esplorare a fondo il mondo della personalizzazione e dell'esperienza utente individuale. Quando pensiamo ai casi d'uso in cui impiegare un LLM, iniziamo a ragionare sui dati specifici che ci consentono di comprendere il percorso di ciascun cliente.
Vediamo qualche esempio:
- Se potessi riconoscere i graffi sulle auto dalle immagini delle telecamere di sorveglianza, potrei migliorare il check-in e il check-out delle nostre auto a noleggio.
- Se sapessi quali servizi hanno maggiori probabilità di fidelizzare un cliente, potrei proporre offerte personalizzate per trattenerlo.
- Se potessi profilare il cliente sulla base dei suoi dati storici individuali, potrei offrire una consulenza esperta.
Come si vede, partiamo da un livello generale con l'obiettivo di offrire consigli unici basati su esperienze individuali. Le suggerisco di iniziare con il template che segue per far emergere le idee, e di farle poi evolvere verso casi d'uso ulteriori, anche al di fuori di questi schemi.
- Se potessi riconoscere/interpretare/identificare ______ in ____, potrei ____
- Se sapessi quali ________ hanno maggiori probabilità di __________ per ogni singolo _______, potrei ____
- Se potessi identificare ________ con _______, potrei _________
Definisca una manciata di casi d'uso da approfondire. Anche se all'inizio dovessero risultare difficili, li conservi: gli stessi casi d'uso potrebbero diventare fattibili in futuro.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Valutazione dei dati
Scelga uno dei primi casi d'uso, magari quello con il ROI potenziale più alto, e individuiamo insieme quali dati servono per partire. Non tutti i dati richiesti emergeranno alla prima iterazione: potrebbe arrivare alle fasi successive solo per accorgersi che ne servono altri. L'importante è documentare ogni scoperta, così da supportare le iniziative future.
Riprendiamo uno degli esempi della fase precedente.
- Se sapessi quali servizi hanno maggiori probabilità di fidelizzare un cliente, potrei proporre offerte di retention personalizzate.
Dobbiamo capire quali dati servono per iniziare a fare previsioni. È qui che entra in gioco la conoscenza del dominio, fondamentale per individuare i data point giusti.
In questo esempio specifico, partiamo dalle interazioni del cliente: feedback o commenti sui servizi, acquisti precedenti, visualizzazioni e click sui servizi. Anche le interazioni con il supporto clienti sono utili. Possiamo inoltre attingere alle informazioni del profilo cliente.
In questa fase è meglio avere troppi dati piuttosto che mantenerli essenziali. La fase di test ci permetterà di capire quali dati possono essere rimossi e se ne servono di aggiuntivi per ottenere i risultati desiderati.
Tipi di bias
Diversi tipi di bias possono insinuarsi nei dati. Eccone alcuni a cui prestare attenzione.
Reporting Bias — Si verifica quando la frequenza dei record in un dataset non riflette accuratamente le distribuzioni del mondo reale, generando risultati distorti. Questa discrepanza nasce quando determinati eventi o comportamenti sono sovra- o sotto-rappresentati nei dati di training.
Selection Bias — Per evitarlo, si assicuri che i dati siano rappresentativi della popolazione target. Significa raccogliere dati eterogenei e completi da fonti diverse, coprendo demografie, contesti e scenari differenti.
Group Attribution Bias — Per evitarlo, verifichi che i dati di training includano rappresentazioni eterogenee ed equilibrate di tutti i gruppi. Controlli regolarmente gli output del modello alla ricerca di pattern distorti e utilizzi metriche di equità per valutare le prestazioni sui diversi gruppi.
Monitoraggio e sicurezza
Già nelle prime fasi del processo iniziamo a integrare sicurezza e monitoraggio nei workloads. È fondamentale rispettare i controlli di sicurezza nella data pipeline. Segua i principi del minimo privilegio e applichi controlli di audit alla fonte dati.
Monitori inoltre le data pipeline per ridurre il rischio di problemi di integrità dei dati e di un eventuale degrado della qualità dell'output di machine learning.
Infine, esegua un test sul bias. Predisponga una verifica per valutare l'importanza delle metriche nella rappresentazione dei dati. I suoi dati sono rappresentativi di quelli di produzione che riceverà? Sta includendo dati PII? Sta includendo altri dati che potrebbero introdurre un bias?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Progettazione dell'architettura
Partiamo dal suo caso d'uso per individuare il foundation model più adatto.
Amazon Bedrock dà accesso a diversi foundation model dei principali fornitori di AI, utili per molteplici casi d'uso di AI generativa.
Ecco i modelli utilizzabili in casi specifici come generazione/sintesi di testo, generazione/identificazione di immagini, trascrizione/traduzione audio ed embeddings:
1. Generazione/sintesi di testo
Per generare o sintetizzare testo può utilizzare modelli capaci di comprendere e produrre linguaggio naturale. Per esempio:
- Anthropic Claude: noto per le capacità avanzate di generazione di testo, tra cui sintesi, question answering e dialogo.
- Mistral Models: progettati per essere versatili e in grado di gestire diverse attività testuali, tra cui generazione, sintesi e altro.
2. Generazione/identificazione di immagini
Per generare o identificare immagini servono modelli specializzati in computer vision:
- Stability AI Stable Diffusion: ideale per la generazione di immagini, in grado di creare contenuti dettagliati e di alta qualità a partire da prompt testuali.
- Amazon Rekognition (non parte di Bedrock, ma rilevante per l'identificazione delle immagini): offre solide capacità di identificazione, rilevamento di oggetti e analisi facciale.
3. Trascrizione/traduzione audio
Per convertire l'audio in testo o tradurre da una lingua all'altra si usano modelli adatti a gestire dati audio:
- Amazon Transcribe (non parte di Bedrock, ma rilevante per la trascrizione audio): converte il parlato in testo con accuratezza.
- Amazon Translate: (non parte di Bedrock) per tradurre testo da una lingua all'altra; può essere abbinato ad Amazon Transcribe per una traduzione audio end-to-end.
- Foundation model OpenAI Whisper: disponibile su SageMaker JumpStart. Un modello fondazionale che trascrive l'audio in testo in modo molto efficiente in più lingue.
4. Embeddings
Per generare embeddings:
- Amazon Titan Embeddings: specializzato nella creazione di rappresentazioni vettoriali dense (embeddings) del testo, utili per ricerca semantica, clustering e sistemi di raccomandazione.
Con Bedrock è possibile eseguire un proprio modello o altri modelli su Sagemaker, come tutti quelli disponibili su Huggingface. Qui il riferimento ai modelli supportati su Bedrock.
Una volta scelto il foundation model giusto, il passo successivo è selezionare il system design adeguato. Può sceglierne uno oppure combinarne più d'uno per ottenere il risultato migliore per il suo scenario.
1. Modello GenAI diretto
Il modello di AI generativa viene addestrato per produrre direttamente l'output desiderato a partire dall'input. Si usa spesso per attività che richiedono informazioni di carattere generale, come la capitale di un Paese.
2. Architettura RAG (Retrieval-Augmented Generation)
RAG combina i vantaggi dei modelli basati su retrieval e di quelli generativi. Recupera prima i documenti rilevanti da una knowledge base e utilizza poi un modello generativo per costruire una risposta, integrando le informazioni dei documenti recuperati.
3. Architettura ad agenti
In questo design più modelli AI (agenti) interagiscono tra loro per generare l'output finale. Ogni agente è specializzato in un aspetto diverso del compito e collabora con gli altri per produrre un output più articolato.
4. Architettura multi-modello
Prevede l'addestramento di un singolo modello in grado di gestire più attività.
È particolarmente utile negli scenari in cui le attività sono correlate o presentano informazioni sovrapposte.
La scelta dell'architettura dipende dai requisiti e dai vincoli specifici del progetto.
Sono diversi i servizi AWS utilizzabili per il suo progetto.
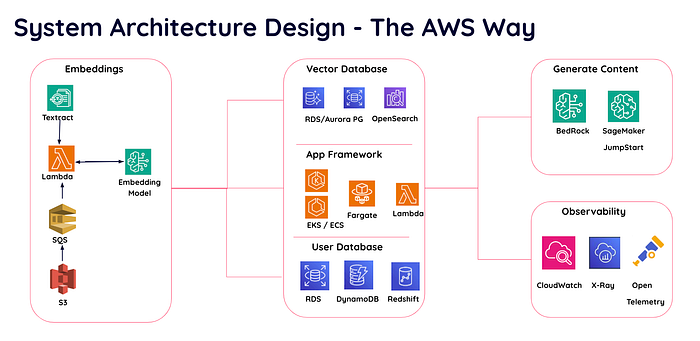
Progettazione dell'architettura di sistema con i servizi AWS
Prompt Design
Il prompt design è importante perché incide sulla qualità e sulla pertinenza dell'output del modello AI. Un prompt ben costruito guida il modello verso risposte più accurate, contestualmente appropriate e utili. È essenziale per i seguenti motivi.
1. Precisione
Un prompt chiaro e specifico aiuta il modello a comprendere esattamente ciò che gli viene chiesto, portando a risposte più precise.
2. Contesto
Un prompt ben progettato fornisce il contesto necessario, aiutando il modello a generare risposte più rilevanti e significative. Tenga presente che la dimensione del contesto è limitata e con alcuni modelli comporta costi aggiuntivi, perché incide sul numero di token dei parametri di input. Quando sceglie un modello verifichi che supporti il contesto, perché non tutti accettano context token.
3. Controllo
Quando il modello deve rispettare determinate linee guida, un prompt design accurato aiuta a indirizzarne comportamento e output.
4. Efficienza
Un buon prompt riduce la necessità di scambi di chiarimenti e rende le interazioni con il modello più efficienti.
5. Esperienza utente
Infine, prompt ben costruiti contribuiscono a una migliore esperienza utente, perché permettono al modello di fornire risposte soddisfacenti.
Ora che abbiamo chiara l'importanza di un prompt ben costruito, è il momento di concentrarci sui passi successivi.
Inizi definendo l'output desiderato. Per esempio, a un prompt come "Puoi consigliarmi un buon ristorante italiano a San Francisco?" un output adeguato potrebbe essere: "Certo, la 'Trattoria Contadina' a San Francisco è molto consigliata per la cucina italiana. È nota per i piatti autentici e per l'atmosfera accogliente.
Non si dimentichi di provare la pasta della casa!"
Identificare il contesto necessario per l'output desiderato: significa capire quali informazioni servono al modello AI per generare una risposta accurata e pertinente. Ecco alcuni passaggi utili:
1. Comprendere il compito: cosa deve fare il modello? Sta rispondendo a una domanda, generando un testo o svolgendo un'altra attività? La natura del compito determina il contesto necessario.
2. Identificare le informazioni chiave: quali informazioni servono al modello per svolgere correttamente il compito? Possono includere i dettagli forniti nel prompt, conoscenze di background sull'argomento o informazioni sulle preferenze o sulla situazione dell'utente.
3. Considerare le dipendenze: ci sono dipendenze tra le diverse parti del compito? Per esempio, se l'attività consiste nel rispondere a una serie di domande, il modello potrebbe dover ricordare domande e risposte precedenti.
4. Testare e iterare: testi il modello con prompt diversi e osservi che tipo di output genera. Se l'output non è quello desiderato, potrebbe servire più contesto oppure un prompt più chiaro.
5. Testare con modelli diversi: se il risultato finale non è soddisfacente, può essere utile provare alcuni altri modelli per scegliere il migliore.
L'obiettivo finale è fornire al modello contesto sufficiente per generare l'output desiderato, ma non così tanto da sovraccaricarlo o confonderlo. È un equilibrio delicato che richiede sperimentazione e iterazione.
Per ottenere l'output desiderato, prepari 2-3 prompt candidati utilizzando tecniche come few-shot, chain of thought o multi-prompt, e scelga quello più adatto alle sue esigenze.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Sicurezza
Una volta completata la fase di prompt design, si concentri sulle misure di sicurezza per mitigare la prompt injection. Come saprà, la prompt injection è un rischio di sicurezza in cui un attaccante manipola l'input del modello per ottenere output dannosi, come l'accesso a informazioni riservate. Ecco alcune misure per mitigarla.
1. Validazione dell'input: implementi regole di validazione rigorose per gli input degli utenti. Possono includere limiti di lunghezza, controlli di formato e filtraggio di caratteri speciali o parole chiave potenzialmente pericolose.
2. Sanitizzazione: sanitizzi gli input degli utenti per rimuovere o effettuare l'escape dei caratteri sfruttabili in attacchi di injection. In questo modo si evita che il modello interpreti parte dell'input come comando o istruzione.
3. Rate limiting: applichi il rate limiting per impedire richieste rapide e ripetute da uno stesso utente o indirizzo IP. Aiuta a mitigare i tentativi di prompt injection a forza bruta.
4. Monitoraggio e logging: monitori l'attività del sistema e registri input degli utenti e output del modello. Aiuta a rilevare pattern insoliti o segnali di attacco.
5. Formazione degli utenti: sensibilizzi gli utenti sui rischi della prompt injection e li incoraggi a segnalare attività sospette. Contribuisce a creare una cultura della sicurezza.
6. Training del modello: addestri il modello a riconoscere e rifiutare input potenzialmente dannosi. È un'attività complessa per la natura del linguaggio e per il rischio di falsi positivi, ma può rappresentare un ulteriore livello di difesa efficace.
POC (Proof of Concept)
Ora che conosciamo i servizi gestiti disponibili e abbiamo una buona padronanza delle architetture, è il momento di costruire qualcosa di entusiasmante.
Possiamo sfruttare AWS Amazon Bedrock, il modo più semplice per costruire e scalare applicazioni di AI generativa con foundation model. Offre diversi modelli ad alte prestazioni di AI21 Labs, Anthropic, Cohere, Meta, Mistral AI e Stability AI. Mette inoltre a disposizione strumenti come Knowledge Bases, Agents e Guardrails.
Knowledge Bases for Amazon Bedrock: una funzionalità completamente gestita che aiuta a implementare l'intero workflow RAG, dall'ingestion al retrieval fino all'arricchimento del prompt, senza dover costruire integrazioni personalizzate con le fonti dati né gestire i flussi di dati.
Agents for Amazon Bedrock: gli agenti orchestrano e analizzano il compito, scomponendolo nella corretta sequenza logica grazie alle capacità di ragionamento dell'FM. Richiamano automaticamente le API necessarie per interagire con sistemi e processi aziendali e soddisfare la richiesta, decidendo lungo il percorso se proseguire o se raccogliere ulteriori informazioni.
Guardrails for Amazon Bedrock: servono a implementare protezioni specifiche per l'applicazione, in linea con i casi d'uso e con le policy di AI.
Con questi strumenti è facile partire e costruire un prototipo del sistema che intende realizzare. È un buon punto di partenza per testare l'architettura. Predisponga alcuni scenari di test per verificare i risultati. Lo provi con dataset diversi e chieda a utenti differenti di metterlo alla prova. Questa è la parte più stimolante: riceverà complimenti, suggerimenti e feedback costruttivi. Se necessario, torni al tavolo da disegno, modifichi il modello, sperimenti architetture e servizi diversi e selezioni i più adatti. In fondo non è un processo lineare.
A questo punto può assicurarsi che tutte le misure di osservabilità e sicurezza siano in atto. La sicurezza è un processo a più livelli che coinvolge sia misure tecniche sia fattori umani. È importante rivedere e aggiornare regolarmente le pratiche di sicurezza per stare al passo con minacce in continua evoluzione.
E così arriviamo a osservabilità e sicurezza.
Osservabilità
Se utilizza un LLM per la generazione di testo, valuti i seguenti aspetti.
Perplexity
Misura quanto bene un modello probabilistico predica un campione. Nel contesto dei modelli linguistici, una perplexity più bassa indica che il modello è più bravo a prevedere la parola successiva in una sequenza. Si usa spesso durante il training per misurare i progressi del modello.
BLEU (Bilingual Evaluation Understudy)
Una metrica utilizzata per valutare la qualità delle traduzioni generate automaticamente.
Misura quante parole o frasi della traduzione automatica corrispondono a una traduzione di riferimento, considerando sia la precision (quante parole della traduzione automatica sono presenti nel riferimento) sia il recall (quante parole del riferimento sono presenti nella traduzione automatica).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Un insieme di metriche utilizzate per valutare la sintesi automatica di testi e la traduzione automatica.
ROUGE include misure per confrontare la sovrapposizione di n-grammi, sequenze di parole e coppie di parole tra il riassunto generato dal sistema e un insieme di riassunti di riferimento.
Word Error Rate (WER)
Una metrica diffusa per le attività di riconoscimento vocale e di traduzione automatica. Misura il numero minimo di modifiche (inserimenti, cancellazioni o sostituzioni) necessarie per trasformare l'output del sistema nell'output di riferimento. Un WER più basso indica un sistema più accurato.
Ognuna di queste metriche offre una prospettiva diversa sulle prestazioni del modello e di solito vengono utilizzate insieme per ottenere una visione più completa.
Osservabilità — Azioni dell'utente
Soddisfazione sull'output
Raccolga il feedback degli utenti 👍 o 👎
L'utente copia l'output del modello
Osservi se gli utenti copiano spesso l'output del modello: è un segnale che lo trovano utile.
L'utente rigenera l'output
Se nota che gli utenti rigenerano ripetutamente l'output modificando il prompt, il comportamento può dipendere da output di scarsa qualità. Verifichi i prompt per assicurarsi che producano risposte utili.
Per quanto tempo l'utente interagisce con il modello
Se diversi utenti tendono a passare poco tempo a interagire con il modello e ad abbandonarlo bruscamente, è probabile che non siano soddisfatti delle prestazioni. In tal caso dovrà verificare le performance del modello.
Ulteriori misure di sicurezza
Valutazione della tossicità
Può utilizzare Comprehend per analizzare il testo e comprenderne il sentiment, sia esso positivo, negativo, neutro o misto. Lo si può sfruttare nella valutazione della tossicità per capire se il testo contiene contenuti dannosi o negativi. Se le esigenze sono più specifiche, può addestrare un modello personalizzato con la funzionalità di custom classification di Amazon Comprehend. Può addestrare il modello con un dataset che includa esempi di testo tossico e non tossico, e poi usarlo per classificare nuovi testi in base alla loro tossicità. Anche Amazon Transcribe, un altro servizio AWS, ha introdotto una funzionalità chiamata Toxicity Detection.
GuardRail
Guardrail è uno strumento incluso in Amazon Bedrock che permette di costruire e personalizzare protezioni di sicurezza e privacy per un'applicazione di AI generativa. Funziona con tutti i large language model (LLM) di Amazon Bedrock, oltre che con i modelli fine-tuned. Può configurare regole in Guardrail e impostare più guardrail. Si colloca tra l'applicazione e il modello e valuta automaticamente tutto ciò che entra nel modello dall'applicazione e che esce dal modello verso l'applicazione, per rilevare e contribuire a prevenire contenuti che ricadono in categorie vietate.
Custom Entity Recognition
È una funzionalità di Amazon Comprehend. Permette di identificare nel testo termini specifici del proprio dominio.
Per esempio, può usare la Custom Entity Recognition per estrarre da documenti testuali non strutturati specifici tipi di informazioni, come nomi di prodotti, entità finanziarie o qualsiasi termine rilevante per il suo business.
Può sfruttare questo servizio per filtrare determinate entità e mettere in sicurezza i dati.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Scalare la soluzione
Quantizzare i modelli
La quantizzazione è un processo utilizzato per ridurre i requisiti di memoria e di calcolo dei modelli di machine learning. Può ridurre in modo significativo l'occupazione di memoria del modello e velocizzare i calcoli, spesso senza una perdita rilevante di accuratezza. Va però sottolineato che una perdita di accuratezza c'è, ed è accettabile finché le metriche di valutazione restano soddisfatte (per esempio ROGUE, BLEU o test propri).
Fine-tuning dei modelli
Il fine-tuning è il processo con cui un modello pre-addestrato (un modello già addestrato su un grande dataset) viene specializzato per svolgere un compito specifico. In questo modo possiamo sfruttare le feature apprese dal modello pre-addestrato e adattarle al nuovo compito, utilizzando meno dati e meno risorse di calcolo. Il fine-tuning aiuta a migliorare l'efficienza, ridurre i costi di trasferimento dati e favorire un migliore utilizzo delle risorse.
Deployment multipli
Mantenga semplice il framework di orchestrazione (per esempio LangChain) e crei più deployment per gestire pipeline complesse.
Valutare il costo del modello self-hosted vs API a scala molto grande
Risorse di calcolo necessarie: verifichi le risorse computazionali richieste da entrambe le opzioni. Per un modello self-hosted comprende il costo dei server (CPU/GPU) per eseguire il modello. Per un modello API include il costo per chiamata API o per unità di tempo di calcolo. Spesso vengono misurati in token, e il numero di token dipende dalla dimensione di input e contesto e dal modello.
Trasferimento dati: per un modello self-hosted include il costo del trasferimento dati da e verso il server. Per un modello API include il costo dei dati inviati e ricevuti dall'API.
Storage: per un modello self-hosted comprende il costo di archiviazione del modello e dei dati. Per un modello API può includere il costo di archiviazione dei dati prima e dopo le chiamate API.
Manutenzione: un modello self-hosted può richiedere più manutenzione, inclusi gestione dei server, aggiornamento dei modelli e troubleshooting. Un modello API può avere costi di manutenzione inferiori, perché è il fornitore a occuparsi di queste attività.
Scaling: se l'applicazione deve scalare per gestire più richieste, un modello self-hosted può richiedere più server, con un aumento dei costi. Un modello API scala più facilmente, ma i costi crescono con il numero di chiamate API.
Latenza: se l'applicazione richiede risposte in tempo reale, un modello self-hosted può offrire una latenza inferiore. Tuttavia, se il fornitore API ha server vicini ai suoi utenti, anche un modello API può offrire una latenza paragonabile.
Considerati questi fattori, può stimare il total cost of ownership (TCO) per entrambe le opzioni. Avrà così un quadro più chiaro di quale soluzione sia più conveniente per il suo caso d'uso specifico.
Il costo, però, non è l'unico fattore da considerare. Tenga conto anche di prestazioni, flessibilità e facilità di integrazione con i sistemi esistenti.
Riepilogo
Questo articolo descrive un processo in 6 fasi per passare dall'ideazione alla produzione con i large language model (LLM):
- Ideazione — Brainstorming di casi d'uso e idee per sfruttare le capacità degli LLM. Il documento fornisce un template che aiuta a generare idee.
- Valutazione dei dati — Identificare i dati necessari a supportare il caso d'uso scelto, prestando attenzione ai potenziali bias.
- Progettazione dell'architettura — Scegliere i servizi AWS e i foundation model di Amazon Bedrock più adatti per realizzare le funzionalità richieste. Le opzioni includono generazione diretta, retrieval-augmented generation, architetture ad agenti e multi-modello.
- Prompt Design — Costruire prompt curati per guidare il modello e garantire la qualità dell'output desiderata, considerando anche le misure di sicurezza per mitigare i rischi di prompt injection.
- Proof of Concept (POC) — Costruire un prototipo utilizzando strumenti di Amazon Bedrock come Knowledge Bases, Agents e Guardrails, e testarlo a fondo.
- Osservabilità e sicurezza — Implementare misure per monitorare le prestazioni del modello (per esempio perplexity, BLEU, ROUGE) e le interazioni degli utenti. Integrare inoltre controlli di sicurezza come la valutazione della tossicità e la custom entity recognition. Si sottolinea l'importanza di integrare considerazioni di monitoraggio e sicurezza lungo l'intero processo. Vengono fornite anche indicazioni per scalare la soluzione, incluse tecniche come quantizzazione e fine-tuning del modello, oltre alla valutazione dei trade-off tra un modello self-hosted e un approccio basato su API.
Questo articolo è una breve sintesi di un webinar che Eduardo Mota e io abbiamo tenuto per i clienti di DoiT International. Eduardo è co-autore di questo post.
Se desidera iniziare il suo percorso con gli LLM, parliamone!