De l'idéation à la production — Image issue de la communauté AWS
Voici une feuille de route concise pour démarrer l'implémentation des LLM dans vos workloads. Le chemin de l'idéation à la production est passionnant, mais loin d'être linéaire. Les étapes que nous détaillons ici vous permettront de situer où vous en êtes et de comprendre comment passer de l'une à l'autre jusqu'à atteindre un environnement de production.
Nous allons définir 6 étapes, reliées entre elles par le monitoring et la sécurité.

Les étapes
Idéation
Les capacités des LLM permettent d'explorer pleinement la personnalisation et l'expérience utilisateur sur mesure. En réfléchissant aux cas d'usage où les LLM peuvent intervenir, on commence à identifier les données spécifiques qui aideront à comprendre le parcours d'expérience de chaque client.
Quelques exemples :
- Si je pouvais reconnaître les rayures sur les voitures à partir d'images de caméras de surveillance, je pourrais améliorer le check-in et le check-out de nos voitures de location.
- Si je savais quels services sont les plus susceptibles de fidéliser un client, je pourrais lui proposer des offres personnalisées pour le retenir.
- Si je pouvais identifier le persona client à partir de données historiques individuelles, je pourrais lui fournir des conseils d'expert.
On part d'un niveau général avec l'objectif de fournir des conseils uniques fondés sur des expériences individuelles. Je vous encourage à utiliser les modèles ci-dessous pour amorcer la réflexion, puis à faire évoluer vos idées vers d'autres cas d'usage.
- Si je pouvais reconnaître/interpréter/identifier ______ dans ____ je pourrais ____
- Si je savais quels ________ sont les plus susceptibles de __________ pour chaque ________, je pourrais ____
- Si je pouvais identifier ________ à partir de _______, je pourrais _________
Créez plusieurs cas d'usage à évaluer. Même si certains semblent difficiles à amorcer, conservez-les : ils pourront devenir réalisables plus tard.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Évaluation des données
Choisissez l'un des premiers cas d'usage, idéalement celui qui présente le meilleur ROI selon vous, et identifions les données nécessaires pour démarrer. Toutes les données requises ne seront pas repérées dès la première itération : vous pourrez progresser dans les étapes suivantes et constater que d'autres données sont nécessaires. L'essentiel est de documenter chaque découverte pour vos initiatives futures.
Reprenons l'un des exemples de l'étape précédente.
- Si je savais quels services sont les plus susceptibles de fidéliser un client, je pourrais lui proposer des offres de fidélisation personnalisées.
Il faut identifier les données nécessaires pour commencer à formuler une prédiction. C'est ici que la connaissance métier entre en jeu pour repérer les bonnes données.
Pour cet exemple précis, on commence par identifier les interactions clients : retours sur les services, commentaires, achats antérieurs, consultations ou clics sur des services. Toute interaction avec le support client est également utile. On peut aussi exploiter les informations du profil client.
À ce stade, mieux vaut disposer de trop de données que de chercher à les réduire à l'essentiel. Le processus de test permettra d'identifier ce qui peut être supprimé, ou si des données supplémentaires sont nécessaires pour atteindre les résultats souhaités.
Types de biais
Plusieurs types de biais peuvent s'infiltrer dans vos données. En voici quelques-uns à surveiller.
Biais de déclaration — Il survient lorsque la fréquence des enregistrements dans un jeu de données ne reflète pas fidèlement les distributions du monde réel, ce qui produit des résultats faussés ou biaisés. Cet écart apparaît lorsque certains événements ou comportements sont sur- ou sous-représentés dans les données d'entraînement.
Biais de sélection — Pour l'éviter, assurez-vous que les données soient représentatives de la population cible. Cela suppose de collecter des données diversifiées et exhaustives auprès de sources variées afin de couvrir différents profils démographiques, contextes et scénarios.
Biais d'attribution de groupe — Pour l'éviter, veillez à ce que vos données d'entraînement incluent des représentations diversifiées et équilibrées de tous les groupes. Auditez régulièrement les sorties du modèle à la recherche de schémas biaisés et utilisez des métriques d'équité pour évaluer la performance entre les différents groupes.
Monitoring et sécurité
Dès le début du processus, nous intégrons la sécurité et le monitoring à notre workload. Il est essentiel de respecter les contrôles de sécurité dans le pipeline de données. Appliquez le principe du moindre privilège et auditez les contrôles sur la source de données.
Assurez également le monitoring de vos pipelines de données afin de réduire le risque de problèmes d'intégrité et de dégradation de la qualité des sorties du modèle.
Enfin, faites un test de biais. Mettez en place une évaluation pour mesurer l'importance des métriques dans la représentation des données. Vos données sont-elles représentatives des données de production que vous recevrez ? Incluez-vous des données PII ? D'autres données susceptibles d'introduire un biais ?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Conception de l'architecture
Partons de votre cas d'usage pour sélectionner le bon modèle de fondation.
Amazon Bedrock donne accès à divers modèles de fondation issus des principaux fournisseurs d'IA, adaptés à différents cas d'usage de l'IA générative.
Voici les modèles utilisables pour des cas spécifiques tels que la génération/résumé de texte, la génération/identification d'images, la transcription/traduction audio et les embeddings :
1. Génération/résumé de texte
Pour les tâches de génération ou de résumé de texte, vous pouvez utiliser des modèles capables de comprendre et de produire du langage naturel. Par exemple :
- Anthropic Claude : reconnu pour ses capacités avancées de génération de texte, notamment le résumé, la réponse à des questions et le dialogue.
- Mistral Models : conçus pour être polyvalents, ils prennent en charge diverses tâches textuelles, dont la génération et le résumé.
2. Génération/identification d'images
Pour générer ou identifier des images, vous aurez besoin de modèles spécialisés en vision par ordinateur :
- Stability AI Stable Diffusion : idéal pour la génération d'images, capable de créer des visuels détaillés et de haute qualité à partir de prompts texte.
- Amazon Rekognition (qui ne fait pas partie de Bedrock mais reste pertinent pour l'identification d'images) : offre de solides capacités d'identification d'images, de détection d'objets et d'analyse faciale.
3. Transcription/traduction audio
Pour convertir l'audio en texte ou traduire des langues, vous utiliserez des modèles adaptés au traitement des données audio :
- Amazon Transcribe (hors Bedrock, mais pertinent pour la transcription audio) : convertit la parole en texte avec précision.
- Amazon Translate (hors Bedrock) : pour traduire un texte d'une langue à une autre, peut être combiné à Amazon Transcribe pour une traduction audio de bout en bout.
- Modèle de fondation OpenAI Whisper : disponible sur SageMaker JumpStart. Un modèle de fondation qui transcrit l'audio en texte avec une grande efficacité dans plusieurs langues.
4. Embeddings
Pour générer des embeddings :
- Amazon Titan Embeddings : spécialisé dans la création de représentations vectorielles denses (embeddings) de texte, utiles pour la recherche sémantique, le clustering et les systèmes de recommandation.
Avec Bedrock, il est possible d'exécuter votre propre modèle ou tout autre modèle sur Sagemaker, comme l'ensemble de ceux disponibles sur Huggingface. Voici la référence des modèles pris en charge par Bedrock.
Une fois le bon modèle de fondation sélectionné, l'étape suivante consiste à choisir la conception système appropriée. Vous pouvez en retenir une seule ou en combiner plusieurs pour obtenir les résultats adaptés à votre scénario.
1. Modèle GenAI direct
Le modèle d'IA générative est entraîné à produire directement la sortie souhaitée à partir de l'entrée. Cette approche est souvent retenue pour des tâches nécessitant des informations générales, comme la capitale d'un pays.
2. Architecture RAG (Retrieval-Augmented Generation)
Le RAG combine les avantages des modèles fondés sur la recherche et des modèles génératifs. Il récupère d'abord les documents pertinents dans une base de connaissances, puis utilise un modèle génératif pour produire une réponse en s'appuyant sur les informations extraites.
3. Architecture à agents
Dans cette conception, plusieurs modèles d'IA (agents) interagissent entre eux pour générer la sortie finale. Chaque agent se spécialise dans un aspect différent de la tâche et collabore avec les autres pour produire un résultat plus complexe.
4. Architecture multi-modèle
Cette approche consiste à entraîner un seul modèle capable de gérer plusieurs tâches.
Elle est particulièrement utile lorsque les tâches sont liées ou partagent des informations.
Le choix de l'architecture dépend des exigences et contraintes propres à votre projet.
Plusieurs services AWS peuvent être mobilisés pour votre projet
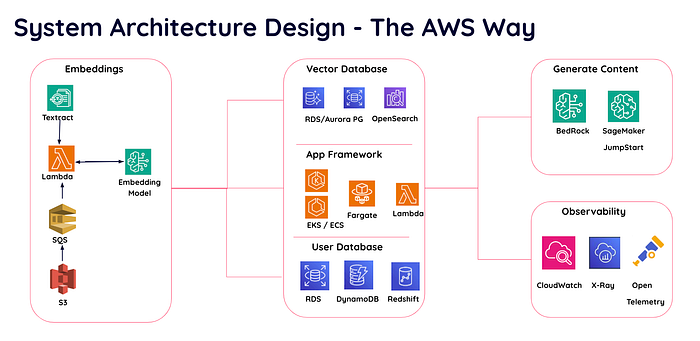
Conception d'architecture système avec les services AWS
Conception des prompts
La conception des prompts est essentielle car elle influence la qualité et la pertinence des sorties du modèle d'IA. Un prompt bien conçu guide le modèle vers des réponses plus précises, contextuellement adaptées et utiles. Cela compte pour les raisons suivantes.
1. Précision :
Si votre prompt est clair et spécifique, il aide le modèle à comprendre exactement ce qui est demandé, ce qui mène à des réponses plus précises.
2. Contexte :
Un prompt bien conçu fournit le contexte nécessaire, ce qui aide le modèle à générer des réponses plus pertinentes et significatives. Notez que la taille du contexte est limitée et qu'avec certains modèles, elle peut entraîner des coûts supplémentaires, ces derniers étant calculés sur la taille des tokens en entrée. Lors du choix d'un modèle, vérifiez qu'il prend en charge le contexte, car ce n'est pas le cas de tous.
3. Contrôle :
Lorsque vous avez besoin que le modèle respecte certaines règles, une conception soignée du prompt aide à orienter son comportement et sa sortie.
4. Efficacité :
Un bon prompt réduit le besoin de clarifications répétées et rend les interactions avec le modèle plus efficaces.
5. Expérience utilisateur :
Enfin, des prompts bien rédigés contribuent à une meilleure expérience utilisateur, puisqu'ils permettent au modèle de fournir des réponses satisfaisantes.
Maintenant que l'importance d'un prompt bien rédigé est posée, place aux étapes suivantes.
Commencez par définir la sortie souhaitée. Par exemple, pour un prompt comme : Pouvez-vous me recommander un bon restaurant italien à San Francisco ?, une sortie appropriée pourrait être : Bien sûr, le Trattoria Contadina à San Francisco est très recommandé pour la cuisine italienne. Il est connu pour ses plats authentiques et son atmosphère chaleureuse.
N'oubliez pas de goûter leurs pâtes signatures !
Identifier le contexte requis pour une sortie souhaitée : il s'agit de comprendre les informations nécessaires au modèle d'IA pour générer une réponse précise et pertinente. Voici quelques étapes pour vous aider à identifier ce contexte :
1. Comprendre la tâche : que doit faire le modèle ? Répondre à une question, générer un texte ou accomplir une autre tâche ? La nature de la tâche détermine le contexte nécessaire.
2. Identifier les informations clés : de quelles informations le modèle a-t-il besoin pour exécuter correctement la tâche ? Cela peut inclure des détails fournis dans le prompt, des connaissances de fond sur le sujet, ou des informations sur les préférences ou la situation de l'utilisateur.
3. Tenir compte des dépendances : existe-t-il des dépendances entre différentes parties de la tâche ? Par exemple, si la tâche consiste à répondre à une série de questions, le modèle pourrait avoir besoin de mémoriser les questions et réponses précédentes.
4. Tester et itérer : enfin, testez le modèle avec différents prompts et observez le type de sortie qu'il produit. Si la sortie ne correspond pas à vos attentes, vous devrez peut-être fournir plus de contexte ou clarifier le prompt.
5. Tester avec différents modèles : si le résultat final n'est pas satisfaisant, essayez quelques modèles supplémentaires pour retenir le meilleur.
L'objectif final est de fournir suffisamment de contexte au modèle pour qu'il génère la sortie attendue, sans pour autant le submerger ni le perdre. C'est un équilibre subtil qui exige souvent expérimentation et itération.
Pour obtenir la sortie souhaitée, créez 2 à 3 prompts optimaux à l'aide des techniques few-shot, chain of thought ou multi-prompt, puis retenez celui qui correspond le mieux à votre besoin.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Sécurité
Une fois la phase de conception des prompts terminée, concentrez-vous sur les mesures de sécurité destinées à atténuer le prompt injection. Pour rappel, le prompt injection est un risque de sécurité dans lequel un attaquant manipule l'entrée du modèle pour produire une sortie nuisible, par exemple obtenir l'accès à des informations restreintes. Voici quelques mesures pour atténuer le prompt injection.
1. Validation des entrées : mettez en place des règles strictes de validation des entrées utilisateur. Cela peut inclure des restrictions de longueur, des contrôles de format et le filtrage des caractères spéciaux ou des mots-clés potentiellement dangereux.
2. Assainissement : assainissez les entrées utilisateur pour supprimer ou échapper les caractères susceptibles d'être utilisés dans des attaques par injection. Cela évite que le modèle interprète une partie de l'entrée comme une commande ou une instruction.
3. Limitation du débit : mettez en place une limitation du débit pour empêcher les requêtes rapides et répétées provenant d'un même utilisateur ou d'une même adresse IP. Cela aide à contrer les tentatives de prompt injection par force brute.
4. Monitoring et journalisation : surveillez l'activité du système et journalisez les entrées utilisateur ainsi que les sorties du modèle. Cela vous aide à détecter des schémas inhabituels ou des signes d'attaque.
5. Sensibilisation des utilisateurs : informez les utilisateurs des risques liés au prompt injection et encouragez-les à signaler toute activité suspecte. Cela contribue à instaurer une culture de la sécurité.
6. Entraînement du modèle : entraînez votre modèle à reconnaître et rejeter les entrées potentiellement nuisibles. C'est un défi compte tenu de la complexité du langage et du risque de faux positifs, mais cela peut constituer une couche de défense supplémentaire efficace.
POC (Proof of Concept)
Maintenant que nous disposons d'informations sur les services managés disponibles pour le projet et que les architectures sont bien comprises, il est temps de passer à la pratique.
Nous pouvons tirer parti d'AWS Amazon Bedrock, le moyen le plus simple de créer et de mettre à l'échelle des applications d'IA générative à partir de modèles de fondation. Il propose plusieurs modèles très performants comme AI21 Labs, Anthropic, Cohere, Meta, Mistral AI et Stability AI, ainsi que divers outils tels que Knowledge Bases, Agents et Guardrails.
Knowledge Bases for Amazon Bedrock : capacité entièrement managée qui vous aide à mettre en œuvre l'intégralité du workflow RAG, de l'ingestion à la récupération et à l'enrichissement des prompts, sans avoir à construire d'intégrations personnalisées vers les sources de données ni à gérer les flux de données.
Agents for Amazon Bedrock : les Agents orchestrent et analysent la tâche, puis la décomposent dans la séquence logique adéquate en s'appuyant sur les capacités de raisonnement du FM. Ils appellent automatiquement les API nécessaires pour interagir avec les systèmes et processus de l'entreprise afin de répondre à la demande, en déterminant en cours de route s'ils peuvent poursuivre ou s'ils doivent collecter davantage d'informations.
Guardrails for Amazon Bedrock : ils servent à mettre en place des protections spécifiques à l'application en fonction de vos cas d'usage et de vos politiques d'IA.
Avec ces outils, il est facile de démarrer et de bâtir un prototype du système que vous prévoyez de construire. C'est un bon point de départ pour tester votre architecture. Préparez quelques scénarios de test pour vérifier les résultats. Essayez avec différents jeux de données et invitez plusieurs utilisateurs à le manipuler. Cette phase est passionnante : vous recueillerez des compliments, des suggestions et des retours constructifs. Si nécessaire, retournez à la planche à dessin, modifiez le modèle, testez d'autres architectures et services, et retenez les plus appropriés. Ce n'est pas un processus linéaire, après tout.
À ce stade, vous pouvez vous assurer que toutes les mesures d'observabilité et de sécurité sont en place. La sécurité est un processus à plusieurs couches qui implique à la fois des mesures techniques et des facteurs humains. Il est important de revoir et de mettre à jour régulièrement vos pratiques pour suivre l'évolution des menaces.
Cela nous amène à l'observabilité et à la sécurité.
Observabilité
Si vous utilisez un LLM pour la génération de texte, évaluez-le selon les critères suivants
Perplexité :
Mesure de la qualité avec laquelle un modèle probabiliste prédit un échantillon. Dans le contexte des modèles de langage, une perplexité plus faible indique que le modèle est meilleur pour prédire le mot suivant dans une séquence. Elle est souvent utilisée pendant l'entraînement pour évaluer les progrès du modèle.
BLEU (Bilingual Evaluation Understudy) :
Métrique utilisée pour évaluer la qualité des traductions générées automatiquement.
Elle mesure le nombre de mots ou d'expressions de la traduction automatique correspondant à une traduction de référence, en tenant compte à la fois de la précision (combien de mots de la traduction automatique se trouvent dans la référence) et du rappel (combien de mots de la référence se trouvent dans la traduction automatique).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) :
Ensemble de métriques utilisées pour évaluer le résumé automatique de textes ainsi que la traduction automatique.
ROUGE inclut des mesures permettant de comparer le recouvrement des n-grammes, des séquences de mots et des paires de mots entre le résumé généré par le système et un ensemble de résumés de référence.
Word Error Rate (WER) :
Métrique courante pour la reconnaissance vocale et les tâches de traduction automatique. Elle mesure le nombre minimal de modifications (insertions, suppressions ou substitutions) requises pour transformer la sortie du système en sortie de référence. Un WER plus faible indique un système plus précis.
Chacune de ces métriques offre un point de vue différent sur la performance du modèle, et elles sont souvent utilisées conjointement pour obtenir une vision plus complète de son comportement.
Observabilité — Actions utilisateur
Satisfaction quant à la sortie :
Recueillez les retours utilisateurs 👍 ou 👎
L'utilisateur copie la sortie du modèle :
Observez si les utilisateurs copient souvent la sortie du modèle. Cela montre qu'ils la trouvent utile.
L'utilisateur régénère la sortie :
Si vous remarquez que les utilisateurs régénèrent fréquemment la sortie en modifiant le prompt, ce comportement peut traduire une sortie défectueuse. Vérifiez les prompts pour vous assurer qu'ils produisent une sortie utile.
Durée d'interaction de l'utilisateur avec le modèle :
Si plusieurs utilisateurs ont tendance à passer peu de temps à dialoguer avec le modèle et à partir brusquement, ils ne sont peut-être pas satisfaits de ses performances. Dans ce cas, il faudra vérifier la performance du modèle.
Mesures de sécurité supplémentaires
Évaluation de la toxicité :
Vous pouvez utiliser Comprehend pour analyser un texte et en cerner le sentiment, qu'il soit positif, négatif, neutre ou mixte. Cela peut s'inscrire dans une évaluation de la toxicité afin de déterminer si le texte contient un contenu nuisible ou négatif. Si vos exigences sont plus spécifiques, il vous faudra peut-être entraîner un modèle personnalisé via la fonctionnalité de classification personnalisée d'Amazon Comprehend. Vous pouvez l'entraîner avec un jeu de données comprenant des exemples de textes toxiques et non toxiques, puis l'utiliser pour classer de nouveaux textes selon leur toxicité. Amazon Transcribe, un autre service AWS, propose une fonctionnalité appelée Toxicity Detection.
GuardRail :
Guardrail est un outil intégré à Amazon Bedrock pour créer et personnaliser des protections de sécurité et de confidentialité pour une application d'IA générative. Il fonctionne avec tous les large language models (LLM) d'Amazon Bedrock, ainsi qu'avec les modèles fine-tunés. Vous pouvez définir des règles dans Guardrail et configurer plusieurs guardrails. Il s'intercale entre l'application et le modèle, et évalue automatiquement tout ce qui transite de l'application vers le modèle et inversement, afin de détecter et d'aider à empêcher les contenus relevant de catégories restreintes.
Custom Entity Recognition :
Fonctionnalité d'Amazon Comprehend qui permet d'identifier dans un texte des termes propres à votre domaine.
Par exemple, vous pouvez utiliser Custom Entity Recognition pour extraire de documents textuels non structurés des types d'informations spécifiques, tels que des noms de produits, des entités financières ou tout terme pertinent pour votre activité.
Vous pouvez utiliser ce service pour filtrer certaines entités et sécuriser vos données.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Mettre la solution à l'échelle :
Quantifier les modèles :
La quantification est un procédé qui réduit les besoins en mémoire et en calcul des modèles de machine learning. Elle peut diminuer significativement l'empreinte mémoire du modèle et accélérer les calculs, souvent sans perte importante de précision. Il existe néanmoins une perte de précision, mais celle-ci reste acceptable tant que vos métriques d'évaluation demeurent satisfaisantes (par exemple ROGUE, BLEU ou vos propres tests).
Fine-tuner les modèles :
Le fine-tuning consiste à entraîner un modèle pré-entraîné (un modèle déjà entraîné sur un grand jeu de données) à exécuter une tâche spécifique. On exploite ainsi les caractéristiques apprises par le modèle pré-entraîné et on les ajuste à la nouvelle tâche, ce qui demande moins de données et de ressources de calcul. Le fine-tuning améliore l'efficacité, réduit les coûts de transfert de données et favorise une meilleure utilisation des ressources.
Déploiements multiples :
Gardez le framework d'orchestration (par exemple LangChain) simple et créez plusieurs déploiements pour gérer des pipelines complexes.
Évaluer le coût d'un modèle hébergé vs un modèle via API à très grande échelle :
Ressources de calcul nécessaires : examinez les ressources de calcul requises pour les deux options. Pour un modèle hébergé, cela inclut le coût des serveurs (CPU/GPU) nécessaires à son exécution. Pour un modèle via API, cela inclut le coût par appel d'API ou par unité de temps de calcul. Ces coûts sont souvent mesurés en tokens, et le nombre de tokens dépend de la taille de l'entrée, du contexte et du modèle.
Transfert de données : pour un modèle hébergé, cela inclut le coût du transfert des données vers et depuis le serveur. Pour un modèle via API, cela inclut le coût des données envoyées et reçues depuis l'API.
Stockage : pour un modèle hébergé, cela inclut le coût de stockage du modèle et des données. Pour un modèle via API, cela peut inclure le coût de stockage des données avant et après les appels d'API.
Maintenance : un modèle hébergé peut exiger davantage de maintenance, notamment la gestion des serveurs, les mises à jour du modèle et le dépannage. Un modèle via API peut entraîner des coûts de maintenance plus faibles, le fournisseur prenant en charge ces tâches.
Mise à l'échelle : si votre application doit monter en charge pour traiter davantage de requêtes, un modèle hébergé peut nécessiter plus de serveurs, ce qui augmente les coûts. Un modèle via API peut être plus simple à mettre à l'échelle, mais les coûts augmenteront avec le nombre d'appels d'API.
Latence : si votre application requiert des réponses en temps réel, un modèle hébergé peut offrir une latence plus faible. Toutefois, si le fournisseur d'API dispose de serveurs proches de vos utilisateurs, un modèle via API peut offrir une latence comparable.
Après avoir pris en compte ces facteurs, vous pouvez estimer le coût total de possession (TCO) des deux options. Vous obtiendrez ainsi une vision plus claire de l'option la plus rentable pour votre cas d'usage spécifique.
Cela dit, le coût n'est pas le seul facteur à considérer. Tenez également compte de critères comme la performance, la flexibilité et la facilité d'intégration avec vos systèmes existants.
Synthèse :
Ce blog présente un processus en 6 étapes pour passer de l'idéation à la production avec des large language models (LLM) :
- Idéation — Faites émerger des cas d'usage et des idées pour exploiter les capacités des LLM. Le document propose un modèle pour stimuler la réflexion.
- Évaluation des données — Identifiez les données nécessaires au cas d'usage retenu, en restant attentif aux biais potentiels.
- Conception de l'architecture — Choisissez les services AWS et les modèles de fondation Amazon Bedrock adaptés pour bâtir les fonctionnalités attendues. Les options incluent la génération directe, le RAG, les architectures à agents et multi-modèles.
- Conception des prompts — Rédigez soigneusement les prompts pour guider le modèle et garantir la qualité des sorties, tout en intégrant des mesures de sécurité pour atténuer les risques de prompt injection.
- Proof of Concept (POC) — Construisez un prototype à l'aide des outils Amazon Bedrock comme Knowledge Bases, Agents et Guardrails, et testez-le rigoureusement.
- Observabilité et sécurité — Mettez en place des mesures pour suivre la performance du modèle (perplexité, BLEU, ROUGE, etc.) et les interactions utilisateurs. Intégrez également des contrôles de sécurité comme l'évaluation de la toxicité et la reconnaissance d'entités personnalisées. L'article souligne l'importance d'intégrer le monitoring et la sécurité tout au long du processus. Il fournit aussi des recommandations pour mettre la solution à l'échelle, notamment via des techniques comme la quantification et le fine-tuning des modèles, ainsi que pour évaluer les compromis entre un modèle hébergé et une approche basée sur API.
Ce blog est un bref résumé d'un webinar animé par Eduardo Mota et moi-même pour les clients de DoiT International. Il est co-auteur de cet article.
Si vous souhaitez démarrer votre parcours LLM, discutons-en !