Der Weg von der Idee zur Produktion – Bild aus der AWS Community
Hier ist ein kompakter Fahrplan für den Einstieg in die LLM-Implementierung in Ihren Workloads. Der Weg von der Idee bis in die Produktion ist spannend – und alles andere als linear. Anhand der Phasen, die wir hier beleuchten, erkennen Sie, wo Sie gerade stehen und wie Sie zur nächsten Stufe gelangen, bis Sie eine Produktivumgebung erreichen.
Wir definieren 6 Phasen, die alle durch Monitoring und Sicherheit miteinander verbunden sind.

Phasen
Ideenfindung
Die Fähigkeiten von LLMs eröffnen uns die Welt der Individualisierung und personalisierten Nutzererlebnisse in vollem Umfang. Wenn wir über Anwendungsfälle für LLMs nachdenken, beginnen wir bei den konkreten Datenpunkten, die uns helfen, die individuelle Customer Journey zu verstehen.
Einige Beispiele:
- Wenn ich Kratzer an Fahrzeugen auf Bildern von Überwachungskameras erkennen könnte, ließen sich Check-in und Check-out unserer Mietwagen verbessern.
- Wenn ich wüsste, welche Services am ehesten zur Kundenbindung beitragen, könnte ich personalisierte Bindungsangebote erstellen.
- Wenn ich die Kundenpersona anhand individueller historischer Daten identifizieren könnte, ließe sich Expertenberatung gezielt anbieten.
Wir starten also auf einer allgemeinen Ebene und arbeiten auf das Ziel hin, basierend auf individuellen Erfahrungen einzigartige Empfehlungen auszusprechen. Beginnen Sie am besten mit der folgenden Vorlage, um Ideen zu sammeln, und entwickeln Sie diese zu weiteren Anwendungsfällen jenseits der Vorlage weiter.
- Wenn ich ______ in ____ erkennen/interpretieren/identifizieren könnte, könnte ich ____
- Wenn ich wüsste, welche ________ am ehesten von jeder einzelnen _______ __________ würden, könnte ich ____
- Wenn ich ________ mit _______ identifizieren könnte, könnte ich _________
Erstellen Sie eine Handvoll Anwendungsfälle für die weitere Bewertung. Auch wenn manche zunächst schwer umsetzbar erscheinen, behalten Sie sie im Blick. Genau diese Use Cases können in Zukunft realisierbar werden.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Datenbewertung
Wählen Sie einen der ersten Anwendungsfälle aus – idealerweise denjenigen mit dem besten ROI – und bestimmen Sie, welche Daten für den Einstieg erforderlich sind. Nicht jeder benötigte Datenpunkt zeigt sich in der ersten Iteration; möglicherweise stellen Sie erst in späteren Phasen fest, dass weitere Daten nötig sind. Wichtig ist, alle Erkenntnisse zu dokumentieren, um sie bei künftigen Initiativen nutzen zu können.
Greifen wir eines der Beispiele aus der vorherigen Phase auf:
- Wenn ich wüsste, welche Services am ehesten zur Kundenbindung beitragen, könnte ich personalisierte Bindungsangebote erstellen.
Wir müssen bestimmen, welche Daten erforderlich sind, um eine Vorhersage zu treffen. Hier kommt Domain-Wissen ins Spiel, um die relevanten Datenpunkte zu identifizieren.
In diesem Beispiel beginnen wir mit Kundeninteraktionen wie Service-Feedback oder Kommentaren, vorherigen Käufen, Service-Aufrufen oder Klicks. Auch Interaktionen mit dem Kundensupport sind hilfreich. Zusätzlich können wir Informationen aus dem Kundenprofil heranziehen.
In dieser Phase ist es besser, zu viele Daten zu haben, als den Datenbestand zu schmal zu halten. Im Testprozess zeigt sich, welche Daten entfernt werden können oder ob zusätzliche Daten nötig sind, um die gewünschten Ergebnisse zu erzielen.
Arten von Bias
In Ihren Daten können sich verschiedene Arten von Bias einschleichen. Auf folgende sollten Sie achten:
Reporting Bias – Tritt auf, wenn die Häufigkeit der Datensätze die reale Verteilung nicht akkurat widerspiegelt und so zu verzerrten Ergebnissen führt. Diese Diskrepanz entsteht, wenn bestimmte Ereignisse oder Verhaltensweisen in den Trainingsdaten über- oder unterrepräsentiert sind.
Selection Bias – Um diesen Bias zu vermeiden, müssen die Daten repräsentativ für die Zielpopulation sein. Sammeln Sie dazu vielfältige und umfassende Daten aus unterschiedlichen Quellen, um verschiedene Demografien, Kontexte und Szenarien abzudecken.
Group Attribution Bias – Um Group Attribution Bias zu vermeiden, sollten Ihre Trainingsdaten alle Gruppen vielfältig und ausgewogen abbilden. Prüfen Sie die Modell-Outputs regelmäßig auf verzerrte Muster und nutzen Sie Fairness-Metriken, um die Performance über verschiedene Gruppen hinweg zu bewerten.
Monitoring & Sicherheit
Bereits früh im Prozess sollten Sie Sicherheit und Monitoring in Ihren Workload integrieren. Achten Sie darauf, die Sicherheitskontrollen Ihrer Datenpipeline einzuhalten. Folgen Sie dem Least-Privilege-Prinzip und implementieren Sie Audit-Kontrollen an der Datenquelle.
Überwachen Sie zudem Ihre Datenpipelines, um Probleme bei der Datenintegrität und eine mögliche Verschlechterung der Machine-Learning-Ergebnisse zu vermeiden.
Führen Sie schließlich einen Bias-Test durch. Bewerten Sie darin die Bedeutung der Metriken für die Datenrepräsentation. Sind Ihre Daten repräsentativ für die Produktionsdaten, die Sie später erhalten werden? Enthalten sie PII-Daten? Enthalten sie weitere Daten, die einen Bias einbringen könnten?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Architekturdesign
Beginnen wir mit Ihrem Anwendungsfall, um das passende Foundation Model auszuwählen.
Amazon Bedrock bietet Zugang zu verschiedenen Foundation Models führender KI-Anbieter, die für unterschiedliche Generative-AI-Anwendungsfälle geeignet sind.
Folgende Modelle eignen sich für spezifische Aufgaben wie Textgenerierung/-zusammenfassung, Bildgenerierung/-erkennung, Audiotranskription/-übersetzung sowie Embeddings:
1. Textgenerierung/-zusammenfassung
Für Aufgaben wie das Generieren oder Zusammenfassen von Texten eignen sich Modelle, die natürliche Sprache verstehen und erzeugen können. Beispiele:
- Anthropic Claude: Bekannt für fortschrittliche Textgenerierung, einschließlich Zusammenfassung, Frage-Antwort und Dialog.
- Mistral Models: Vielseitig einsetzbar und in der Lage, verschiedene textbasierte Aufgaben wie Generierung, Zusammenfassung und mehr zu bewältigen.
2. Bildgenerierung/-erkennung
Zum Generieren oder Erkennen von Bildern benötigen Sie Modelle, die auf Computer Vision spezialisiert sind:
- Stability AI Stable Diffusion: Ideal für Bildgenerierung – erstellt detailreiche, hochwertige Bilder aus Text-Prompts.
- Amazon Rekognition (nicht Teil von Bedrock, aber relevant für Bilderkennung): Bietet robuste Bilderkennung, Objekterkennung und Gesichtsanalyse.
3. Audiotranskription/-übersetzung
Zum Konvertieren von Audio in Text oder Übersetzen von Sprachen nutzen Sie Modelle, die mit Audiodaten umgehen können:
- Amazon Transcribe (nicht Teil von Bedrock, aber relevant für Audiotranskription): Wandelt Sprache präzise in Text um.
- Amazon Translate: (nicht Teil von Bedrock) Übersetzt Texte zwischen Sprachen und lässt sich mit Amazon Transcribe für eine End-to-End-Audioübersetzung kombinieren.
- OpenAI Whisper Foundation Model: Verfügbar in SageMaker JumpStart. Ein Foundation Model, das Audio sehr effizient in mehreren Sprachen in Text transkribiert.
4. Embeddings
Zum Erzeugen von Embeddings:
- Amazon Titan Embeddings: Spezialisiert auf dichte Vektordarstellungen (Embeddings) von Text – nützlich für semantische Suche, Clustering und Empfehlungssysteme.
Mit Bedrock können Sie auch eigene Modelle oder andere Modelle auf SageMaker betreiben, etwa alle bei Hugging Face verfügbaren Modelle. Hier finden Sie eine Übersicht der auf Bedrock unterstützten Modelle.
Sobald Sie das passende Foundation Model gewählt haben, geht es im nächsten Schritt um das passende Systemdesign. Sie können einen Ansatz wählen oder mehrere kombinieren, um die richtigen Ergebnisse für Ihr Szenario zu erzielen.
1. Direktes GenAI-Modell
Hier wird ein generatives KI-Modell darauf trainiert, den gewünschten Output direkt aus dem Input zu erzeugen. Häufig genutzt für Aufgaben mit Allgemeinwissen, etwa die Hauptstadt eines Landes.
2. RAG-Architektur (Retrieval-Augmented Generation)
RAG kombiniert die Vorteile retrieval-basierter und generativer Modelle. Zunächst werden relevante Dokumente aus einer Wissensbasis abgerufen, anschließend erzeugt ein generatives Modell eine Antwort und integriert dabei Informationen aus den abgerufenen Dokumenten.
3. Agent-Architektur
In diesem Design interagieren mehrere KI-Modelle (Agents) miteinander, um den finalen Output zu erzeugen. Jeder Agent ist auf einen Teilaspekt spezialisiert; gemeinsam liefern sie ein komplexeres Ergebnis.
4. Multi-Model-Architektur
Hier wird ein einzelnes Modell trainiert, das mehrere Aufgaben bewältigen kann.
Besonders nützlich, wenn die Aufgaben verwandt sind oder sich überschneidende Informationen teilen.
Die Wahl der Architektur hängt von den spezifischen Anforderungen und Rahmenbedingungen Ihres Projekts ab.
Für Ihr Projekt kommen mehrere AWS-Services infrage.
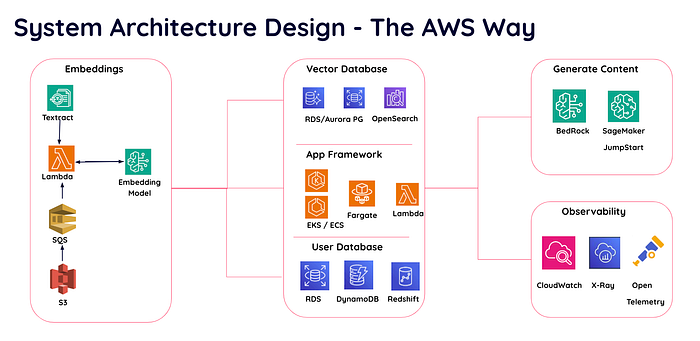
Systemarchitekturdesign mit AWS-Services
Prompt Design
Prompt Design ist wichtig, weil es die Qualität und Relevanz des KI-Outputs beeinflusst. Ein gut gestalteter Prompt kann das Modell dazu bringen, präzisere, kontextuell passende und nützlichere Antworten zu liefern. Aus folgenden Gründen ist es essenziell:
1. Präzision:
Ein klarer, spezifischer Prompt hilft dem Modell, genau zu verstehen, was gefragt ist – und liefert so präzisere Antworten.
2. Kontext:
Ein gut gestalteter Prompt liefert den nötigen Kontext, damit das Modell relevantere und sinnvollere Antworten generieren kann. Beachten Sie: Die Kontextgröße ist begrenzt und führt bei manchen Modellen zu zusätzlichen Kosten, da diese pro Tokengröße der Eingabeparameter abrechnen. Stellen Sie bei der Modellauswahl sicher, dass das Modell den benötigten Kontext unterstützt – nicht alle Modelle unterstützen Kontext-Tokens.
3. Steuerung:
Wenn das Modell bestimmte Vorgaben einhalten soll, hilft ein sorgfältig gestalteter Prompt, Verhalten und Output gezielt zu lenken.
4. Effizienz:
Ein guter Prompt reduziert Rückfragen und macht die Interaktion mit dem Modell effizienter.
5. User Experience:
Schließlich tragen gut formulierte Prompts zu einer besseren User Experience bei, da das Modell zufriedenstellende Antworten liefern kann.
Nun, da wir die Bedeutung eines gut gestalteten Prompts kennen, geht es an die nächsten Schritte.
Beginnen Sie damit, den gewünschten Output zu definieren. Beispiel: Bei einem Prompt wie "Können Sie ein gutes italienisches Restaurant in San Francisco empfehlen?" könnte ein passender Output lauten: "Klar, die \"Trattoria Contadina\" in San Francisco ist sehr empfehlenswert für italienische Küche. Sie ist bekannt für ihre authentischen Gerichte und die gemütliche Atmosphäre.
Probieren Sie unbedingt ihre Signature-Pasta!"
Den erforderlichen Kontext für den gewünschten Output bestimmen: Dazu gehört, die Informationen zu kennen, die das KI-Modell benötigt, um eine präzise und relevante Antwort zu generieren. Diese Schritte helfen Ihnen dabei:
1. Aufgabe verstehen: Was soll das Modell tun? Eine Frage beantworten, Text generieren oder eine andere Aufgabe übernehmen? Die Art der Aufgabe bestimmt den nötigen Kontext.
2. Schlüsselinformationen identifizieren: Welche Informationen muss das Modell kennen, um die Aufgabe korrekt zu erfüllen? Das können Details aus dem Prompt sein, Hintergrundwissen zum Thema oder Informationen über Präferenzen oder Situation des Nutzers.
3. Abhängigkeiten berücksichtigen: Gibt es Abhängigkeiten zwischen verschiedenen Teilen der Aufgabe? Wenn beispielsweise eine Reihe von Fragen beantwortet werden soll, muss sich das Modell vorherige Fragen und Antworten merken können.
4. Testen und iterieren: Testen Sie das Modell mit verschiedenen Prompts und beobachten Sie den Output. Ist das Ergebnis nicht wie gewünscht, müssen Sie ggf. mehr Kontext liefern oder den Prompt präzisieren.
5. Verschiedene Modelle testen: Wenn das Endergebnis nicht zufriedenstellend ist, lohnt es sich, einige weitere Modelle auszuprobieren und das beste auszuwählen.
Ziel ist es, dem Modell genug Kontext zu liefern, um den gewünschten Output zu erzeugen – aber nicht so viel, dass es überfordert oder verwirrt wird. Eine Balance, die häufig Experimentieren und Iteration erfordert.
Erstellen Sie 2–3 Top-Prompts mit Few-Shot-, Chain-of-Thought- oder Multi-Prompt-Techniken und wählen Sie den Prompt, der am besten zu Ihren Anforderungen passt.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Sicherheit
Sobald die Phase des Prompt Designs abgeschlossen ist, sollten Sicherheitsmaßnahmen gegen Prompt Injection im Fokus stehen. Wie Sie sicher wissen, ist Prompt Injection ein Sicherheitsrisiko, bei dem ein Angreifer den Modell-Input manipuliert, um schädlichen Output zu erzeugen – etwa Zugriff auf eingeschränkte Informationen. Einige Maßnahmen zur Eindämmung:
1. Input-Validierung: Implementieren Sie strikte Validierungsregeln für Nutzereingaben. Dazu zählen Längenbegrenzungen, Formatprüfungen und das Filtern von Sonderzeichen oder potenziell schädlichen Schlüsselwörtern.
2. Sanitisierung: Bereinigen Sie Nutzereingaben, indem Sie Zeichen entfernen oder escapen, die für Injection-Angriffe genutzt werden könnten. So wird verhindert, dass das Modell Teile der Eingabe als Befehl oder Anweisung interpretiert.
3. Rate Limiting: Setzen Sie Rate Limiting ein, um schnelle, wiederholte Anfragen einzelner Nutzer oder IP-Adressen zu unterbinden. Das hilft gegen Brute-Force-Versuche bei Prompt Injection.
4. Monitoring und Logging: Überwachen Sie die Systemaktivität und protokollieren Sie Nutzereingaben sowie Modellausgaben. So erkennen Sie auffällige Muster oder Anzeichen eines Angriffs.
5. Nutzeraufklärung: Klären Sie Nutzer über die Risiken von Prompt Injection auf und ermutigen Sie sie, verdächtige Aktivitäten zu melden. Das fördert eine Kultur der Sicherheitsachtsamkeit.
6. Modelltraining: Trainieren Sie Ihr Modell so, dass es potenziell schädliche Eingaben erkennt und zurückweist. Das ist aufgrund der Sprachkomplexität und des Risikos von False Positives anspruchsvoll, kann aber als zusätzliche Schutzschicht sehr effektiv sein.
POC (Proof of Concept)
Da wir nun die verfügbaren Managed Services kennen und die Architekturen verstehen, ist es Zeit, etwas Spannendes zu bauen.
Wir können Amazon Bedrock nutzen – die einfachste Möglichkeit, generative KI-Anwendungen mit Foundation Models zu erstellen und zu skalieren. Bedrock bietet mehrere leistungsstarke Modelle wie AI21 Labs, Anthropic, Cohere, Meta, Mistral AI und Stability AI sowie diverse Tools wie Knowledge Bases, Agents und Guardrails.
Knowledge Bases for Amazon Bedrock: Eine vollständig verwaltete Funktion, mit der sich der gesamte RAG-Workflow von der Ingestion über das Retrieval bis zur Prompt-Augmentierung umsetzen lässt – ohne eigene Integrationen zu Datenquellen entwickeln und Datenflüsse selbst verwalten zu müssen.
Agents for Amazon Bedrock: Agents orchestrieren und analysieren die Aufgabe und zerlegen sie mithilfe der Reasoning-Fähigkeiten des Foundation Models in die richtige logische Sequenz. Sie rufen automatisch die nötigen APIs auf, um mit Unternehmenssystemen und -prozessen zu interagieren, und entscheiden dabei, ob sie fortfahren oder weitere Informationen benötigen.
Guardrails for Amazon Bedrock: Werden eingesetzt, um anwendungsspezifische Schutzmaßnahmen basierend auf Ihren Use Cases und KI-Richtlinien zu implementieren.
Mit diesen Tools fällt der Einstieg leicht, und Sie können einen Prototyp Ihres geplanten Systems bauen. Ein guter Ausgangspunkt, um die Architektur zu testen. Definieren Sie einige Testszenarien, prüfen Sie die Ergebnisse mit verschiedenen Datensätzen und lassen Sie unterschiedliche Nutzer das System ausprobieren. Dieser Teil macht Spaß: Sie erhalten Lob, Vorschläge und konstruktives Feedback. Falls nötig, gehen Sie zurück ans Reißbrett, passen das Modell an, probieren andere Architekturen und Services aus und wählen die passendsten. Es ist nun einmal kein linearer Prozess.
Stellen Sie an dieser Stelle sicher, dass alle Observability- und Sicherheitsmaßnahmen greifen. Sicherheit ist ein vielschichtiger Prozess, der sowohl technische Maßnahmen als auch den Faktor Mensch umfasst. Überprüfen und aktualisieren Sie Ihre Sicherheitspraktiken regelmäßig, um mit der Bedrohungslage Schritt zu halten.
Damit kommen wir zu Observability und Sicherheit.
Observability
Wenn Sie ein LLM zur Textgenerierung einsetzen, sollten Sie es anhand folgender Metriken bewerten:
Perplexity:
Misst, wie gut ein Wahrscheinlichkeitsmodell eine Stichprobe vorhersagt. Bei Sprachmodellen bedeutet eine geringere Perplexity, dass das Modell das nächste Wort in einer Sequenz besser vorhersagt. Sie wird häufig im Trainingsprozess genutzt, um den Fortschritt zu beurteilen.
BLEU (Bilingual Evaluation Understudy):
Eine Metrik zur Bewertung der Qualität maschinell erzeugter Übersetzungen.
Sie misst, wie viele Wörter oder Phrasen in der maschinellen Übersetzung mit einer Referenzübersetzung übereinstimmen, und berücksichtigt dabei sowohl Precision (wie viele Wörter der maschinellen Übersetzung in der Referenz vorkommen) als auch Recall (wie viele Wörter der Referenz in der maschinellen Übersetzung enthalten sind).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
Eine Sammlung von Metriken zur Bewertung automatischer Textzusammenfassungen sowie maschineller Übersetzungen.
ROUGE umfasst Maße, die die Überlappung von n-Grammen, Wortsequenzen und Wortpaaren zwischen der vom System generierten Zusammenfassung und einer Reihe von Referenzzusammenfassungen vergleichen.
Word Error Rate (WER):
Eine gängige Metrik für Spracherkennung und maschinelle Übersetzung. Sie misst die minimale Anzahl an Bearbeitungen (Einfügungen, Löschungen, Ersetzungen), die nötig sind, um den System-Output in den Referenz-Output zu überführen. Eine niedrigere WER bedeutet ein präziseres System.
Jede dieser Metriken liefert eine andere Perspektive auf die Modell-Performance. Häufig werden sie kombiniert, um ein umfassenderes Bild der Modellgüte zu erhalten.
Observability – Nutzeraktionen
Output-Zufriedenheit:
Holen Sie Nutzerfeedback ein 👍 oder 👎
Nutzer kopiert den Modell-Output:
Beobachten Sie, ob Nutzer den Output häufig kopieren. Das zeigt, dass sie ihn nützlich finden.
Nutzer regeneriert den Output:
Wenn Nutzer den Output wiederholt durch Anpassung des Prompts neu generieren, kann das auf fehlerhafte Ausgaben hindeuten. Prüfen Sie die Prompts, um nützliche Outputs sicherzustellen.
Wie lange ein Nutzer mit dem Modell interagiert:
Wenn mehrere Nutzer wenig Zeit mit dem Modell verbringen und abrupt abbrechen, sind sie mit der Performance möglicherweise unzufrieden. In diesem Fall sollten Sie die Modellleistung überprüfen.
Weitere Sicherheitsmaßnahmen
Toxicity Evaluation:
Mit Amazon Comprehend können Sie Texte analysieren und ihre Stimmung bestimmen – positiv, negativ, neutral oder gemischt. Das lässt sich als Teil einer Toxicity Evaluation nutzen, um zu erkennen, ob ein Text schädliche oder negative Inhalte enthält. Bei spezifischeren Anforderungen kann es nötig sein, mit der Custom-Classification-Funktion von Amazon Comprehend ein eigenes Modell zu trainieren. Sie können das Modell mit einem Datensatz trainieren, der Beispiele für toxischen und nicht toxischen Text enthält, und neue Texte anschließend nach ihrer Toxizität klassifizieren. Auch Amazon Transcribe – ein weiterer AWS-Service – bietet inzwischen ein Feature namens Toxicity Detection.
GuardRail:
Guardrail ist ein in Amazon Bedrock integriertes Tool zum Aufbau und zur Anpassung von Sicherheits- und Datenschutzmaßnahmen für generative KI-Anwendungen. Es funktioniert mit allen Large Language Models (LLMs) in Amazon Bedrock sowie mit fine-getunten Modellen. In Guardrail können Sie Regeln definieren und mehrere Guardrails einrichten. Es sitzt zwischen Anwendung und Modell und bewertet automatisch alles, was von der Anwendung an das Modell und vom Modell zurück an die Anwendung geht, um Inhalte aus eingeschränkten Kategorien zu erkennen und zu unterbinden.
Custom Entity Recognition:
Eine Funktion von Amazon Comprehend. Sie ermöglicht es, domänenspezifische Begriffe in Texten zu identifizieren.
Beispielsweise können Sie mit Custom Entity Recognition bestimmte Informationsarten aus unstrukturierten Textdokumenten extrahieren – etwa Produktnamen, Finanzentitäten oder andere geschäftsrelevante Begriffe.
So können Sie bestimmte Entitäten herausfiltern und Ihre Daten absichern.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Lösung skalieren:
Modelle quantisieren:
Quantisierung ist ein Verfahren, um Speicher- und Rechenanforderungen von Machine-Learning-Modellen zu reduzieren. Sie kann den Speicherbedarf des Modells deutlich verringern und die Berechnung beschleunigen, oft ohne nennenswerten Genauigkeitsverlust. Wichtig zu wissen: Es entsteht ein Genauigkeitsverlust, der jedoch akzeptabel ist, solange Ihre Bewertungsmetriken weiterhin erfüllt werden (z. B. ROUGE, BLEU oder eigene Tests).
Modelle fine-tunen:
Fine-Tuning ist ein Verfahren, bei dem ein vortrainiertes Modell (eines, das bereits auf einem großen Datensatz trainiert wurde) für eine spezifische Aufgabe weitertrainiert wird. So können wir die gelernten Features des vortrainierten Modells nutzen und an die neue Aufgabe anpassen – mit weniger Daten und weniger Rechenressourcen. Fine-Tuning steigert die Effizienz, senkt Datenübertragungskosten und sorgt für eine bessere Ressourcennutzung.
Multiple Deployments:
Halten Sie das Orchestrierungs-Framework (z. B. LangChain) schlank und nutzen Sie mehrere Deployments, um komplexe Pipelines zu bewältigen.
Hosted-Modell vs. API-Modell bei sehr großem Maßstab bewerten:
Erforderliche Compute-Ressourcen: Prüfen Sie die nötigen Rechenressourcen für beide Optionen. Beim Hosted Model sind das die Kosten der Server (CPUs/GPUs) zum Betrieb des Modells. Beim API-Modell fallen Kosten pro API-Call oder pro Compute-Zeiteinheit an. Häufig wird in Tokens abgerechnet, deren Anzahl von Input- und Kontextgröße sowie vom Modell abhängt.
Datenübertragung: Beim Hosted Model umfasst dies die Kosten für die Datenübertragung zum und vom Server. Beim API-Modell die Kosten für an die API gesendete und von ihr empfangene Daten.
Speicher: Beim Hosted Model die Kosten für die Speicherung des Modells und der Daten. Beim API-Modell ggf. Kosten für die Datenspeicherung vor und nach API-Calls.
Wartung: Ein Hosted Model erfordert in der Regel mehr Wartung – Servermanagement, Modell-Updates und Fehlerbehebung. Ein API-Modell verursacht oft geringere Wartungskosten, da der Anbieter diese Aufgaben übernimmt.
Skalierung: Wenn Ihre Anwendung skalieren muss, um mehr Anfragen zu bewältigen, erfordert ein Hosted Model evtl. zusätzliche Server und höhere Kosten. Ein API-Modell skaliert oft einfacher, doch die Kosten steigen mit der Anzahl der API-Calls.
Latenz: Wenn Ihre Anwendung Echtzeit-Antworten benötigt, kann ein Hosted Model geringere Latenz bieten. Hat der API-Anbieter jedoch Server in Nutzernähe, kann auch ein API-Modell vergleichbare Latenz liefern.
Anhand dieser Faktoren können Sie die Total Cost of Ownership (TCO) für beide Optionen schätzen und so klar erkennen, welche Option für Ihren Use Case wirtschaftlicher ist.
Kosten sind jedoch nicht der einzige Faktor. Berücksichtigen Sie auch Performance, Flexibilität und die Integrationsfähigkeit mit Ihren bestehenden Systemen.
Zusammenfassung:
Dieser Beitrag beschreibt einen 6-stufigen Prozess, um mit Large Language Models (LLMs) von der Idee in die Produktion zu gelangen:
- Ideenfindung – Sammeln Sie Anwendungsfälle und Ideen, um die Fähigkeiten von LLMs zu nutzen. Der Beitrag liefert eine Vorlage zur Ideenfindung.
- Datenbewertung – Identifizieren Sie die nötigen Daten für den gewählten Use Case und achten Sie auf potenzielle Bias in den Daten.
- Architekturdesign – Wählen Sie die passenden AWS-Services und Foundation Models aus Amazon Bedrock, um die gewünschte Funktionalität zu realisieren. Optionen sind direkte Generierung, Retrieval-Augmented Generation, Agent-basierte und Multi-Model-Architekturen.
- Prompt Design – Formulieren Sie Prompts sorgfältig, um das Modell zu steuern und die gewünschte Output-Qualität sicherzustellen. Berücksichtigen Sie dabei Sicherheitsmaßnahmen gegen Prompt-Injection-Risiken.
- Proof of Concept (POC) – Bauen Sie einen Prototyp mit den Bedrock-Tools wie Knowledge Bases, Agents und Guardrails und testen Sie ihn gründlich.
- Observability und Sicherheit – Implementieren Sie Maßnahmen zur Überwachung der Modell-Performance (z. B. Perplexity, BLEU, ROUGE) und der Nutzerinteraktionen. Integrieren Sie Sicherheitskontrollen wie Toxicity Evaluation und Custom Entity Recognition. Wichtig ist, Monitoring- und Sicherheitsaspekte über den gesamten Prozess hinweg zu berücksichtigen. Außerdem werden Hinweise zur Skalierung der Lösung gegeben – inklusive Techniken wie Modellquantisierung und Fine-Tuning sowie der Bewertung der Trade-offs zwischen Hosted Model und API-basiertem Ansatz.
Dieser Beitrag fasst ein Webinar zusammen, das Eduardo Mota und ich für Kunden von DoiT International gehalten haben. Er ist Co-Autor dieses Beitrags.
Wenn Sie Ihre LLM-Reise starten möchten, sprechen Sie uns an!