Da ideação à produção — Imagem da comunidade AWS
Este é um mapa rápido para começar sua jornada de implementação de LLM no seu workload. O caminho da ideação à produção é empolgante e tudo, menos linear. As etapas que vamos detalhar aqui ajudam você a identificar em que ponto da jornada está e como avançar de uma fase para outra até chegar ao ambiente de produção.
Vamos definir 6 etapas, e o que conecta todas elas é o monitoramento e a segurança.

Etapas
Ideação
Os recursos dos LLMs nos permitem explorar a fundo o universo da customização e da experiência personalizada do usuário. Ao pensar nos casos de uso em que dá para aplicar LLMs, começamos a refletir sobre quais dados específicos vão nos ajudar a entender as jornadas individuais de cada cliente.
Veja alguns exemplos:
- Se eu conseguisse reconhecer arranhões em carros a partir de imagens das câmeras de segurança, conseguiria melhorar o check-in e o check-out dos nossos carros de aluguel.
- Se eu soubesse quais serviços têm maior probabilidade de reter um cliente, poderia oferecer ofertas personalizadas para retê-lo.
- Se eu pudesse identificar a persona do cliente com base no histórico individual, conseguiria oferecer uma consultoria especializada.
Repare que partimos de algo geral com o objetivo de entregar recomendações únicas, baseadas em experiências individuais. Recomendo começar com o template a seguir para destravar as ideias e, depois, evoluir para outros casos de uso além desses modelos.
- Se eu pudesse reconhecer/interpretar/identificar ______ em ____, eu poderia ____
- Se eu soubesse quais ________ têm maior probabilidade de __________ por cada _______ individual, eu poderia ____
- Se eu pudesse identificar ________ com _______, eu poderia _________
Liste alguns casos de uso para avaliar depois. Mesmo que pareçam difíceis de tirar do papel agora, guarde-os. Eles podem se tornar viáveis no futuro.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Avaliação de dados
Escolha um dos primeiros casos de uso, talvez aquele que você acredita ter o melhor ROI, e vamos identificar quais dados são necessários para começar. Nem todos os dados necessários vão aparecer já na primeira iteração — você pode avançar para etapas seguintes e só então perceber que precisa de dados adicionais. O importante é manter a documentação de tudo que for descoberto, para ajudar em iniciativas futuras.
Vamos retomar um dos exemplos da etapa anterior.
- Se eu soubesse quais serviços têm maior probabilidade de reter um cliente, poderia oferecer ofertas personalizadas de retenção.
Precisamos identificar quais dados são necessários para começar a fazer uma previsão. É aqui que o conhecimento de domínio entra em cena para ajudar a mapear esses pontos de dados.
Para esse exemplo específico, começamos identificando interações do cliente, como feedbacks ou comentários sobre serviços, compras anteriores, visualizações de serviços ou cliques em serviços. Qualquer interação com o suporte ao cliente também ajuda. Também dá para aproveitar as informações do perfil do cliente.
Nesta etapa, é melhor pecar pelo excesso de dados do que tentar deixá-los enxutos demais. O processo de testes vai mostrar quais dados podem ser removidos ou se será preciso buscar dados adicionais para alcançar os resultados desejados.
Tipos de viés
Vários tipos de viés podem se infiltrar nos seus dados. Veja alguns dos quais ficar atento.
Viés de relato (Reporting Bias) — Acontece quando a frequência dos registros em um conjunto de dados não reflete com precisão as distribuições do mundo real, gerando resultados enviesados. Essa discrepância surge quando determinados eventos ou comportamentos estão super ou sub-representados nos dados de treinamento.
Viés de seleção (Selection Bias) — Para evitar esse viés, garanta que os dados sejam representativos da população-alvo. Isso envolve coletar dados diversos e abrangentes de várias fontes, cobrindo diferentes demografias, contextos e cenários.
Viés de atribuição de grupo (Group Attribution Bias) — Para evitar esse tipo de viés, garanta que seus dados de treinamento incluam representações diversas e equilibradas de todos os grupos. Audite regularmente as saídas do modelo em busca de padrões enviesados e use métricas de equidade para avaliar o desempenho entre os diferentes grupos.
Monitoramento e segurança
Logo no início do processo, já vamos incorporando segurança e monitoramento ao nosso workload. É importante garantir que os controles de segurança no pipeline de dados estejam em dia. Siga os princípios de menor privilégio e mantenha controles de auditoria na fonte dos dados.
Além disso, monitore seus pipelines de dados para reduzir o risco de problemas de integridade e de queda na qualidade da saída do machine learning.
Por fim, faça um teste de viés. Crie um teste para avaliar a importância das métricas na representação dos dados. Os seus dados são representativos dos dados de produção que você vai receber? Você está incluindo dados pessoais identificáveis (PII)? Está incluindo algum outro dado capaz de introduzir viés?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Desenho da arquitetura
Vamos partir do seu caso de uso para selecionar o foundation model certo.
O Amazon Bedrock dá acesso a diversos foundation models dos principais provedores de IA, úteis para diferentes casos de uso de IA generativa.
Veja a seguir os modelos que podem ser usados em casos específicos como geração/sumarização de texto, geração/identificação de imagens, transcrição/tradução de áudio e embeddings:
1. Geração/sumarização de texto
Para tarefas como gerar ou resumir textos, dá para usar modelos capazes de entender e gerar linguagem natural. Alguns exemplos:
- Anthropic Claude: Conhecido por recursos avançados de geração de texto, incluindo sumarização, perguntas e respostas e diálogo.
- Mistral Models: Foram projetados para serem versáteis e dar conta de várias tarefas baseadas em texto, incluindo geração, sumarização e muito mais.
2. Geração/identificação de imagens
Para gerar ou identificar imagens, você precisa de modelos especializados em visão computacional:
- Stability AI Stable Diffusion: Ideal para geração de imagens, capaz de criar imagens detalhadas e de alta qualidade a partir de prompts em texto.
- Amazon Rekognition (não faz parte do Bedrock, mas é relevante para identificação de imagens): Oferece recursos robustos de identificação de imagens, detecção de objetos e análise facial.
3. Transcrição/tradução de áudio
Para converter áudio em texto ou traduzir idiomas, você usaria modelos especializados em lidar com dados de áudio:
- Amazon Transcribe (não faz parte do Bedrock, mas é relevante para transcrição de áudio): Converte fala em texto com precisão.
- Amazon Translate: (não faz parte do Bedrock) Para traduzir texto de um idioma para outro, podendo ser combinado com o Amazon Transcribe para tradução de áudio fim a fim.
- OpenAI Whisper foundation model: Disponível no SageMaker JumpStart. Um foundation model que transcreve áudio em texto com muita eficiência em vários idiomas.
4. Embeddings
Para gerar embeddings:
- Amazon Titan Embeddings: Especializado em criar representações vetoriais densas (embeddings) de texto, úteis para busca semântica, clusterização e sistemas de recomendação.
Com o Bedrock, dá para rodar seu próprio modelo ou outros modelos no SageMaker, incluindo todos os disponíveis no Hugging Face. Confira a referência aos modelos suportados no Bedrock.
Depois de escolher o foundation model certo, o próximo passo é escolher o desenho de sistema apropriado. Você pode optar por um deles ou combinar alguns para chegar aos resultados ideais para o seu cenário.
1. Modelo GenAI direto
Aqui, o modelo de IA generativa é treinado para gerar diretamente a saída desejada a partir da entrada. Costuma ser usado em tarefas que exigem informações gerais, como a capital de um país.
2. Arquitetura RAG (Retrieval-Augmented Generation)
O RAG combina os benefícios dos modelos baseados em recuperação com os modelos generativos. Primeiro, recupera documentos relevantes de uma base de conhecimento e, em seguida, usa um modelo generativo para criar uma resposta, incorporando informações desses documentos.
3. Arquitetura de agentes
Nesse desenho, vários modelos de IA (agentes) interagem entre si para gerar a saída final. Cada agente se especializa em um aspecto diferente da tarefa, e juntos colaboram para entregar uma saída mais complexa.
4. Arquitetura multimodelo
Envolve treinar um único modelo capaz de lidar com múltiplas tarefas.
É particularmente útil em cenários nos quais as tarefas estão relacionadas ou possuem informações sobrepostas.
A escolha da arquitetura depende dos requisitos e restrições específicos do seu projeto.
Existem vários serviços da AWS que podem ser usados no seu projeto.
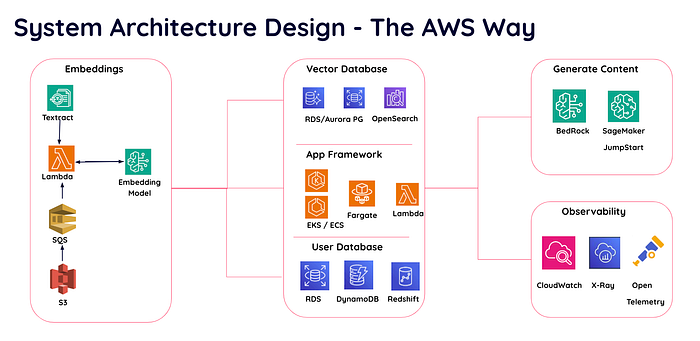
Desenho da arquitetura do sistema com serviços AWS
Design de prompts
O design de prompts é importante porque influencia a qualidade e a relevância da saída do modelo de IA. Um prompt bem elaborado pode guiar o modelo a gerar respostas mais precisas, contextualmente apropriadas e úteis. Ele é essencial pelos seguintes motivos:
1. Precisão:
Se o seu prompt for claro e específico, ajuda o modelo a entender exatamente o que está sendo pedido, levando a respostas mais precisas.
2. Contexto:
Um prompt bem desenhado fornece o contexto necessário, o que ajuda o modelo a gerar respostas mais relevantes e significativas. Vale lembrar que o tamanho do contexto é limitado e, em alguns modelos, pode gerar custos adicionais, já que se aplica ao tamanho do token nos parâmetros de entrada. Ao escolher um modelo, certifique-se de que ele suporta contexto, pois nem todos os modelos suportam tokens de contexto.
3. Controle:
Quando você precisa que o modelo siga determinadas diretrizes, um design cuidadoso de prompt ajuda a guiar o comportamento e a saída do modelo.
4. Eficiência:
Um bom prompt reduz a necessidade de idas e vindas para esclarecer pontos, tornando as interações com o modelo mais eficientes.
5. Experiência do usuário:
Por fim, prompts bem elaborados contribuem para uma melhor experiência do usuário, já que permitem que o modelo entregue respostas satisfatórias.
Agora que sabemos a importância de um prompt bem elaborado, é hora de focar nos próximos passos.
Comece definindo a saída desejada. Por exemplo, para um prompt como "Você pode recomendar um bom restaurante italiano em São Francisco?", uma saída adequada poderia ser: "Claro, a 'Trattoria Contadina' em São Francisco é altamente recomendada para a culinária italiana. É conhecida pelos pratos autênticos e pelo ambiente acolhedor.
Não deixe de provar a massa especial da casa!"
Identificando o contexto necessário para a saída desejada: Isso envolve entender quais informações o modelo de IA precisa para gerar uma resposta precisa e relevante. Veja alguns passos para ajudar a identificar o contexto necessário:
1. Entenda a tarefa: O que o modelo deve fazer? Está respondendo a uma pergunta, gerando um trecho de texto ou executando alguma outra tarefa? A natureza da tarefa determina qual contexto é necessário.
2. Identifique as informações-chave: Quais informações o modelo precisa saber para realizar a tarefa corretamente? Isso pode incluir detalhes fornecidos no prompt, conhecimento de fundo sobre o tema ou informações sobre as preferências ou a situação do usuário.
3. Considere as dependências: Existem dependências entre diferentes partes da tarefa? Por exemplo, se a tarefa for gerar uma resposta para uma série de perguntas, o modelo pode precisar lembrar das perguntas e respostas anteriores.
4. Teste e itere: Por fim, teste o modelo com diferentes prompts e veja que tipo de saída ele gera. Se a saída não for a desejada, talvez seja necessário fornecer mais contexto ou refinar o prompt.
5. Teste com diferentes modelos: Se o resultado final não for satisfatório, vale tentar mais alguns modelos para escolher o melhor.
O objetivo final é fornecer contexto suficiente para que o modelo gere a saída desejada, mas não a ponto de sobrecarregá-lo ou confundi-lo. É um equilíbrio delicado, que normalmente exige experimentação e iteração.
Para chegar à saída desejada, crie de 2 a 3 dos melhores prompts usando técnicas como few shots, chain of thought ou multi-prompt, e escolha o que melhor atende ao seu requisito.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Segurança
Concluída a fase de design de prompts, é hora de focar nas medidas de segurança para mitigar a injeção de prompts. Como você já sabe, a injeção de prompts é um risco de segurança em que um invasor manipula a entrada do modelo para gerar saídas prejudiciais, como obter acesso a informações restritas. Veja algumas medidas para mitigar esse risco.
1. Validação de entrada: Implemente regras rígidas de validação para entradas dos usuários. Isso pode incluir restrições de comprimento, verificações de formato e filtragem de caracteres especiais ou palavras-chave potencialmente prejudiciais.
2. Sanitização: Sanitize as entradas dos usuários para remover ou escapar caracteres que poderiam ser usados em ataques de injeção. Isso ajuda a evitar que o modelo interprete parte da entrada como um comando ou instrução.
3. Rate limiting: Implemente rate limiting para evitar requisições rápidas e repetidas vindas de um único usuário ou endereço IP. Isso ajuda a mitigar tentativas de força bruta de injeção de prompts.
4. Monitoramento e logging: Monitore a atividade do sistema e registre as entradas dos usuários e as saídas do modelo. Isso ajuda a detectar padrões incomuns ou sinais de ataque.
5. Educação do usuário: Eduque os usuários sobre os riscos da injeção de prompts e incentive-os a relatar qualquer atividade suspeita. Isso ajuda a construir uma cultura de conscientização em segurança.
6. Treinamento do modelo: Treine seu modelo para reconhecer e rejeitar entradas potencialmente prejudiciais. Isso pode ser desafiador, devido à complexidade da linguagem e ao risco de falsos positivos, mas representa uma camada adicional de defesa eficaz.
POC (Prova de Conceito)
Agora que temos informações sobre os serviços gerenciados disponíveis para o projeto e uma boa compreensão das arquiteturas, é hora de construir algo empolgante.
Podemos aproveitar o Amazon Bedrock da AWS, a forma mais fácil de construir e escalar aplicações de IA generativa com foundation models. Ele oferece vários modelos de alto desempenho, como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI e Stability AI. Também disponibiliza diversas ferramentas, como Knowledge Bases, Agents e Guardrails.
Knowledge Bases for Amazon Bedrock: Um recurso totalmente gerenciado que ajuda a implementar todo o fluxo de RAG, da ingestão até a recuperação e o aumento de prompts, sem precisar criar integrações customizadas com fontes de dados nem gerenciar fluxos de dados.
Agents for Amazon Bedrock: Os Agents orquestram e analisam a tarefa, decompondo-a na sequência lógica correta com base nas habilidades de raciocínio do FM. Eles chamam automaticamente as APIs necessárias para interagir com os sistemas e processos da empresa e atender à solicitação, decidindo ao longo do caminho se podem prosseguir ou se precisam coletar mais informações.
Guardrails for Amazon Bedrock: São usados para implementar salvaguardas específicas da aplicação, com base nos seus casos de uso e políticas de IA.
Com essas ferramentas, fica fácil começar e construir um protótipo do sistema que você está planejando. Esse é um bom ponto de partida para testar a sua arquitetura. Tenha alguns cenários de teste para validar os resultados. Experimente com diferentes datasets e peça para diferentes usuários colocarem o sistema à prova. Essa parte é empolgante. Você vai receber elogios, sugestões e feedback construtivo. Se necessário, volte para a prancheta, modifique o modelo, experimente arquiteturas e serviços diferentes e selecione os mais adequados. Afinal, não é um processo linear.
Neste momento, você pode garantir que todas as medidas de observabilidade e segurança estão em vigor. Segurança é um processo de múltiplas camadas, que envolve tanto medidas técnicas quanto fatores humanos. É importante revisar e atualizar regularmente suas práticas de segurança para acompanhar as ameaças, que estão sempre evoluindo.
E isso nos leva à observabilidade e segurança.
Observabilidade
Se você está usando LLM para geração de texto, faça a avaliação considerando as seguintes métricas:
Perplexidade:
É uma medida de quão bem um modelo probabilístico prevê uma amostra. No contexto de modelos de linguagem, uma perplexidade menor significa que o modelo é melhor em prever a próxima palavra em uma sequência. Costuma ser usada durante o processo de treinamento para medir o progresso do modelo.
BLEU (Bilingual Evaluation Understudy):
Métrica usada para avaliar a qualidade de traduções geradas por máquina.
Mede quantas palavras ou frases na tradução automática correspondem a uma tradução de referência, levando em conta tanto a precisão (quantas palavras na tradução automática estão na referência) quanto o recall (quantas palavras na referência estão na tradução automática).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
Conjunto de métricas usado para avaliar a sumarização automática de textos, bem como a tradução automática.
O ROUGE inclui medidas para comparar a sobreposição de n-gramas, sequências de palavras e pares de palavras entre o resumo gerado pelo sistema e um conjunto de resumos de referência.
Word Error Rate (WER):
Métrica comum em tarefas de reconhecimento de fala e tradução automática. Mede o número mínimo de edições (inserções, exclusões ou substituições) necessárias para transformar a saída do sistema na saída de referência. Um WER menor indica um sistema mais preciso.
Cada uma dessas métricas oferece uma perspectiva diferente sobre o desempenho do modelo, e elas costumam ser usadas em conjunto para uma compreensão mais completa de como o modelo está se saindo.
Observabilidade — Ações do usuário
Satisfação com a saída:
Colete feedback dos usuários 👍 ou 👎
O usuário copia a saída do modelo:
Observe se os usuários costumam copiar a saída do modelo. Isso mostra que eles consideram a saída útil.
O usuário regenera a saída:
Se você notar que os usuários regeneram a saída repetidamente alterando o prompt, esse comportamento pode indicar saídas inadequadas. Revise os prompts para garantir que estão entregando resultados úteis.
Quanto tempo o usuário interage com o modelo:
Se vários usuários tendem a passar pouco tempo interagindo com o modelo e saem abruptamente, talvez não estejam satisfeitos com o desempenho dele. Nesse caso, será preciso revisar o desempenho do modelo.
Mais medidas de segurança
Avaliação de toxicidade:
Você pode usar o Amazon Comprehend para analisar texto e entender seu sentimento, seja positivo, negativo, neutro ou misto. Isso pode fazer parte da avaliação de toxicidade para identificar se o texto contém conteúdo prejudicial ou negativo. Se seus requisitos forem mais específicos, talvez seja necessário treinar um modelo customizado usando o recurso de classificação customizada do Amazon Comprehend. Você pode treinar o modelo com um dataset que inclua exemplos de textos tóxicos e não tóxicos e, em seguida, usar esse modelo para classificar novos textos com base na toxicidade. O Amazon Transcribe, outro serviço da AWS, lançou um recurso chamado Toxicity Detection.
GuardRail:
O Guardrail é uma ferramenta incluída no Amazon Bedrock para criar e personalizar proteções de segurança e privacidade em uma aplicação de IA generativa. Funciona com todos os large language models (LLMs) no Amazon Bedrock, bem como com modelos ajustados (fine-tuned). Você pode configurar regras no Guardrail e definir múltiplos guardrails. Ele fica entre a aplicação e o modelo e avalia automaticamente tudo o que vai da aplicação para o modelo e do modelo para a aplicação, ajudando a detectar e prevenir conteúdos que se enquadrem em categorias restritas.
Custom Entity Recognition:
É um recurso do Amazon Comprehend. Ele permite identificar termos específicos do seu domínio dentro do texto.
Por exemplo, dá para usar o Custom Entity Recognition para extrair tipos específicos de informações de documentos de texto não estruturados, como nomes de produtos, entidades financeiras ou qualquer termo relevante para o seu negócio.
Você pode usar esse serviço para filtrar determinadas entidades e proteger seus dados.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
Escalando a solução:
Quantização de modelos:
A quantização é um processo usado para reduzir os requisitos de memória e computação dos modelos de machine learning. Ela pode reduzir significativamente o footprint de memória do modelo e acelerar os cálculos, muitas vezes sem uma perda significativa de acurácia. No entanto, é importante observar que existe, sim, alguma perda de acurácia, mas que costuma ser aceitável desde que suas métricas de avaliação continuem sendo atendidas (por exemplo, ROUGE, BLEU ou seus próprios testes).
Fine-tuning de modelos:
Fine-tuning é um processo no qual um modelo pré-treinado (um modelo que já foi treinado em um grande dataset) é treinado para realizar uma tarefa específica. Assim, podemos aproveitar os recursos já aprendidos pelo modelo pré-treinado e ajustá-los à nova tarefa, usando menos dados e menos recursos computacionais. O fine-tuning ajuda a melhorar a eficiência, reduzir custos de transferência de dados e promover melhor utilização de recursos.
Múltiplos deployments:
Mantenha o framework de orquestração (por exemplo, LangChain) simples e crie múltiplos deployments para lidar com pipelines complexos.
Avalie o custo do modelo hospedado vs. modelo via API em larga escala:
Recursos de computação necessários: Verifique os recursos computacionais necessários para as duas opções. Para um modelo hospedado, isso inclui o custo dos servidores (CPUs/GPUs) necessários para executar o modelo. Para um modelo via API, inclui o custo por chamada de API ou por unidade de tempo de computação. Em geral, esses custos são medidos em tokens, e a quantidade de tokens depende do tamanho da entrada, do contexto e do modelo.
Transferência de dados: Para um modelo hospedado, inclui o custo de transferir dados de e para o servidor. Para um modelo via API, inclui o custo dos dados enviados e recebidos da API.
Armazenamento: Para um modelo hospedado, inclui o custo de armazenar o modelo e quaisquer dados. Para um modelo via API, pode incluir o custo de armazenar dados antes e depois das chamadas de API.
Manutenção: Um modelo hospedado pode exigir mais manutenção, incluindo gerenciamento de servidores, atualizações de modelo e troubleshooting. Um modelo via API pode ter custos de manutenção menores, já que o provedor cuida dessas tarefas.
Escalabilidade: Se sua aplicação precisar escalar para lidar com mais requisições, um modelo hospedado pode exigir mais servidores, aumentando os custos. Um modelo via API costuma escalar com mais facilidade, mas os custos sobem com o número de chamadas de API.
Latência: Se sua aplicação exigir respostas em tempo real, um modelo hospedado pode oferecer latência menor. No entanto, se o provedor da API tiver servidores próximos aos seus usuários, o modelo via API pode oferecer latência comparável.
Depois de considerar esses fatores, dá para estimar o custo total de propriedade (TCO) das duas opções. Isso vai dar uma visão mais clara de qual delas é mais custo-efetiva para o seu caso de uso específico.
Mas custo não é o único fator a considerar. Avalie também desempenho, flexibilidade e facilidade de integração com seus sistemas atuais.
Resumo:
Este blog descreve um processo de 6 etapas para ir da ideação à produção com large language models (LLMs):
- Ideação — Faça brainstorming de casos de uso e ideias para aproveitar os recursos do LLM. O documento traz um template para ajudar a gerar ideias.
- Avaliação de dados — Identifique os dados necessários para sustentar o caso de uso selecionado, atento aos potenciais vieses nos dados.
- Desenho da arquitetura — Escolha os serviços AWS adequados e os foundation models do Amazon Bedrock para construir a funcionalidade desejada. As opções incluem geração direta, RAG, baseada em agentes e arquiteturas multimodelo.
- Design de prompts — Elabore prompts com cuidado para orientar o modelo e garantir a qualidade desejada da saída, considerando também medidas de segurança para mitigar os riscos de injeção de prompts.
- Prova de Conceito (POC) — Construa um protótipo usando ferramentas do Amazon Bedrock como Knowledge Bases, Agents e Guardrails, e teste exaustivamente.
- Observabilidade e segurança — Implemente medidas para monitorar o desempenho do modelo (por exemplo, perplexidade, BLEU, ROUGE) e as interações dos usuários. Incorpore também controles de segurança como avaliação de toxicidade e Custom Entity Recognition. Reforça a importância de incluir considerações de monitoramento e segurança ao longo de todo o processo. Também orienta sobre como escalar a solução, incluindo técnicas como quantização e fine-tuning de modelos, além de avaliar os trade-offs entre um modelo hospedado e uma abordagem baseada em API.
Este blog é um breve resumo de um webinar que Eduardo Mota e eu fizemos para os clientes da DoiT International. Ele é coautor deste post.
Se você quer começar sua jornada com LLM, vamos conversar!