請求書での想定外は誰もが避けたいもの。Anomaly Detectionでコスト急増を早期に捉え、その影響と支出のばらつきを最小限に抑えましょう。

毎月のクラウド請求書を開いたら、前月比でいきなり30%増。そんな場面を想像してみてください。先月は大きなプロダクトリリースもインフラの大幅な変更もなかったはずなのに、なぜこんなことが起きたのか――心当たりはありませんか?
クラウドは動く要素が多く、想定外のコスト急増を漏れなく監視・検知するのは簡単ではありません。多くの企業ではエンジニアリングリソースが限られており、コスト急増を手作業で監視し、発生時に原因と影響範囲を特定するところまで対応しきれないのが実情です。
本記事では、次の2点について解説します。
- 独自の異常検知システムを構築する方法
- Cloud Intelligence™のAnomaly Detectionのような既成のソリューションを活用し、コスト急増を自動で監視しながら、より重要な業務に集中する方法
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
異常監視を導入すべき理由
意図しないコスト急増の原因はさまざまです。Terraformリポジトリのエラー、暗号資産マイニングのインシデント、起動したまま放置されたサーバーなど、挙げ始めればきりがありません。
コスト異常は、予算や予測への信頼を揺るがし、バーンレートに影響を与え、クラウド支出全体の傾向を把握しづらくします。
収益に直結する問題であるにもかかわらず、多くの企業は月次請求書が届いてから対応に動き出します。異常を早期に検知して対処できれば、クラウド請求への影響が深刻化する前に芽を摘むことができ、結果としてクラウド支出の予測精度も高まります。
課題は、コスト急増の検知とアラートをいかに自動化するかです。前述の通り、異常検知に人手を割き続ける余裕のある企業は多くありません。FinOps Foundationの「State of FinOps 2023」調査でも、依然として多くの企業が異常アラートの自動化を目指していると報告されています。
独自の異常検知システムを構築する方法
サードパーティ製ツールの導入を検討する前に、「自前で異常監視システムを構築・運用するのに、どれくらいの工数がかかるのか?」と考える方もいるでしょう。
独自の異常検知システムを構築・維持するために必要な作業は、大きく次の4ステップに分けられます。
- サンプル定義グループの作成
- データサンプルの準備
- 分析の開始とフィードバックループの構築
- レポーティング戦略の策定
サンプル定義グループの作成
分析を始める前に、まず「何を監視するか」を定義します。監視対象がコストか使用量か、粒度はSKU単位かサービス単位か、あるいは複数サービスのグループ単位かといったスコープを決め、さらに観測頻度(時間単位、日次、週次、月次)を設定します。
最後に、評価対象とする期間全体を定義します。これがデータセットのサイズを決める要素です。期間が短いほど細かな変動を捉えやすくなる反面、局所的な極大値の重要性を過大に評価してしまうリスクがあります。逆に期間が長いほど多くのコンテキストを得られ、通常の変動や季節性をより的確に捉えられますが、感度が不足するおそれもあります。
データサンプルの準備
データポイントの構成を定義したら、選択したスコープと観測頻度に沿ってソースデータを集計し、クラウド使用量データを適切な構造へ変換する仕組みを構築する必要があります。
分析の開始とフィードバックループの構築
データポイントの分析には、ルール、統計、モデリングなど複数の手法を組み合わせて使えます。評価の目的は最終的に、各サンプルが異常である確率を定量化または層別化することにあります。加えて、異常の影響度や継続期間も特定可能です。システムの精度判定は容易ではなく、組織ごとに異なる検討事項や優先度に左右されます。そのため、継続的な改善につなげるためのフィードバックループが欠かせません。
レポーティング戦略の策定
必要なときに確実に気づける一方で、アラート疲れを招かないレポーティング戦略を策定します。感度を上げすぎたシステムは異常を見逃しにくくなりますが、誤検知が大量に発生すれば、結局は望む成果を得られません。
異常検知のリファレンスアーキテクチャ
Google CloudとAWSはいずれも、各プラットフォーム上で異常検知システムを構築するためのリファレンスアーキテクチャを公開しています。ただし、構築すれば終わりというわけではなく、その後も継続的なメンテナンスやチューニングが欠かせません。
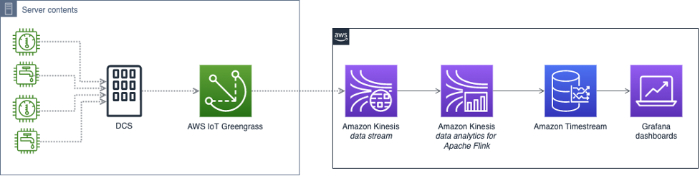
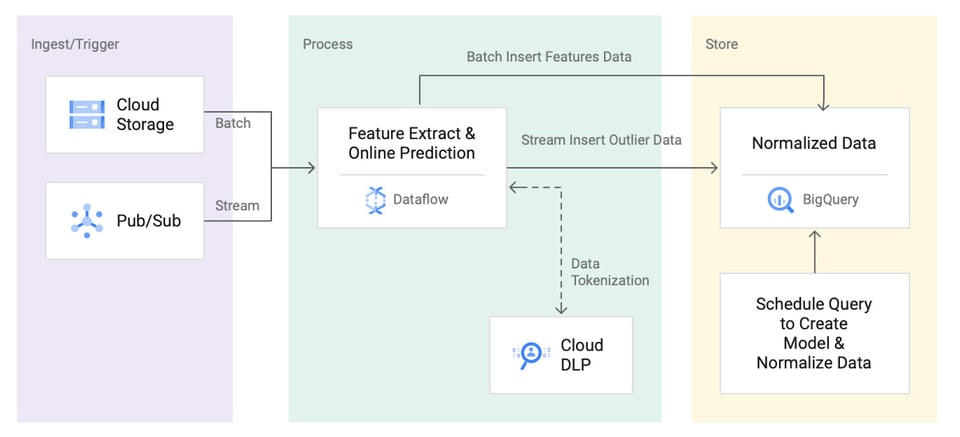
自前で異常検知システムを構築・維持するリソースが確保できない場合は、Cloud Intelligence™のAnomaly Detectionのような既成のソリューションを活用することで、限られたエンジニアリングリソースを割くことなくコスト急増を自動で捉えられます。
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
DoiT Anomaly Detectionでクラウドコスト急増を自動監視
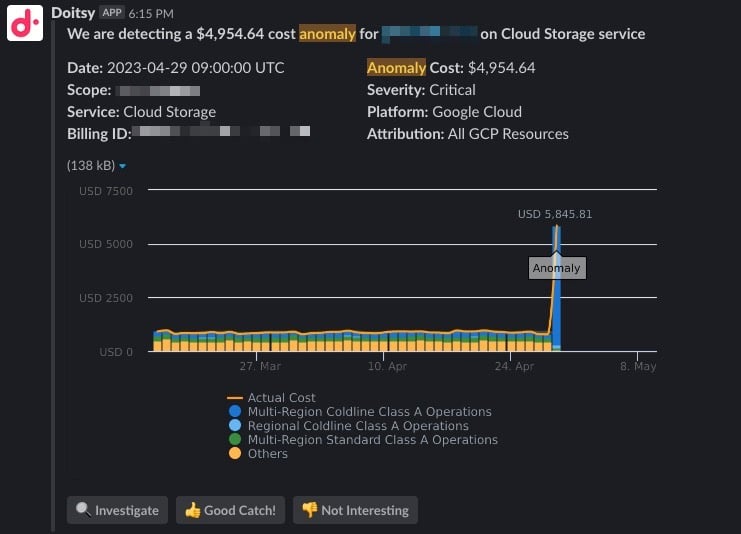
Cloud Intelligence™のAnomaly Detectionは、課金データを継続的にモニタリングし、サービス別およびGCPプロジェクト/AWSアカウント別の支出傾向を分析します。
この分析をもとに課金パターンを定義し、お客様のクラウド利用における「通常の挙動」を独自に学習します。
そして、Anomaly Detectionが予測した支出パターンから外れる支出が発生した際に、アラートを通知します。
うれしいのは、設定もメンテナンスも一切不要なこと。
Anomaly Detectionは複数のパラメータを用い、支出パターンの変化に合わせて閾値を継続的に更新していきます。
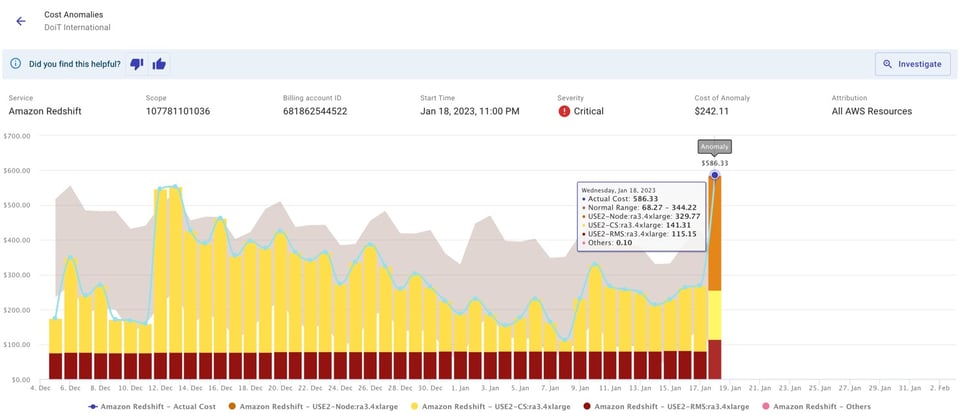
下図のように、通知はメールやチームのSlackチャンネルへ送信するよう設定できます。
これによりチーム内での会話が活性化し、自分たちが負担するクラウド請求への当事者意識と理解が高まります。たとえば、コスト急増の原因がチームで実施していたテストだったとしましょう。それまでそのテストの存在を知らなくても、このアラートをきっかけに把握できるようになります。仮に想定外の急増でなかったとしても、チームの動きについて新しい発見が得られるはずです。
異常の検知とアラート通知を自動化すれば、チームは根本原因の解消に集中できます。アラート内の「Investigate」をクリックするとCloud Intelligence™上で事前設定済みのレポートが開き、迅速な根本原因分析と対応の起点として活用できます。
DoiTをご利用のお客様であれば、Anomaly DetectionはCloud Intelligence™に標準搭載されています。ご契約いただいたその瞬間から課金データの分析が始まり、異常なコスト急増を検知次第アラートを生成します。
まだDoiTをご利用でない方は、ぜひAnomaly Detectionのインタラクティブツアーをお試しください。Anomaly Detectionをはじめとする当社製品を活用したクラウド管理の最適化について、お気軽にお問い合わせいただけます。