Niemand mag Überraschungen auf der Rechnung. Mit Anomaly Detection erkennen Sie Kostenspitzen früh und dämpfen so deren Auswirkungen sowie die Schwankungsbreite Ihrer Ausgaben.

Stellen Sie sich vor, Sie öffnen Ihre monatliche Cloud-Rechnung – und sehen ein sattes Plus von 30 % gegenüber dem Vormonat. Wie konnte das passieren? Im letzten Monat gab es weder größere Produkt-Releases noch nennenswerte Änderungen an der Infrastruktur. Was steckt also dahinter?
In der Cloud sind so viele Komponenten im Spiel, dass sich unerwartete Kostenspitzen nur schwer überwachen und erkennen lassen. Vielen Unternehmen fehlen schlicht die Engineering-Ressourcen, um Kostenspitzen manuell im Blick zu behalten – und im Ernstfall Ursache und Umfang sauber einzugrenzen.
In diesem Beitrag erfahren Sie:
- wie Sie ein eigenes Anomaly-Detection-System aufsetzen
- wie Out-of-the-Box-Lösungen wie Anomaly Detection in Cloud Intelligence™ Kostenspitzen autonom für Sie überwachen, damit Sie sich auf Wichtigeres konzentrieren können.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Warum Sie ein Anomaly-Monitoring brauchen
Ungewollte Kostenspitzen haben viele Gesichter: ein Fehler im Terraform-Repository, ein Crypto-Mining-Vorfall, hochgefahrene und vergessene Server – die Liste lässt sich beliebig fortsetzen.
Kostenanomalien untergraben das Vertrauen in Budgets und Forecasts, belasten Ihre Burn Rate und erschweren den Gesamtblick auf Ihre Cloud-Ausgabenmuster.
Trotz dieser Folgen für die Bilanz warten viele Unternehmen erst die Monatsrechnung ab, bevor sie reagieren. Wer Anomalien früh erkennt und behebt, erstickt das Problem im Keim, bevor es die Cloud-Rechnung spürbar belastet – und macht die Cloud-Ausgaben so insgesamt planbarer.
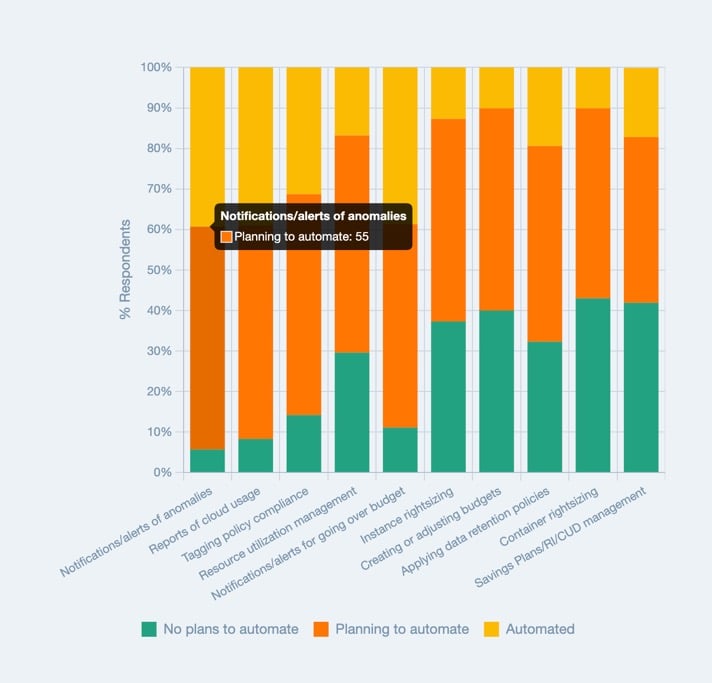
Die eigentliche Herausforderung: die Erkennung und Alarmierung von Kostenspitzen zu automatisieren. Denn wie eingangs erwähnt können es sich viele Unternehmen nicht leisten, Ressourcen für die manuelle Anomalie-Erkennung abzustellen. Laut der Umfrage "State of FinOps 2023" der FinOps Foundation arbeiten viele Unternehmen weiterhin daran, ihre Anomalie-Alerts zu automatisieren.
So bauen Sie Ihr eigenes Anomaly-Detection-System
Bevor Sie zu einem Drittanbieter-Tool greifen, fragen Sie sich vielleicht: "Hmmm, wie aufwendig kann es schon sein, ein eigenes Anomaly-Monitoring aufzubauen und zu betreiben?"
Der Aufwand für Aufbau und Betrieb eines eigenen Anomaly-Detection-Systems lässt sich grob in vier Schritte gliedern:
- Definitionsgruppe für Stichproben erstellen
- Datenstichproben aufbereiten
- Analyse starten und Feedback-Loop einrichten
- Reporting-Strategie festlegen
Definitionsgruppe für Stichproben erstellen
Bevor Sie mit der Analyse loslegen, müssen Sie festlegen, was überwacht werden soll. Dazu gehört der Scope: Geht es um Kosten oder um Nutzung – und in welcher Granularität, also pro SKU, pro Service oder pro Service-Gruppe? Anschließend definieren Sie die Beobachtungsfrequenz (stündlich, täglich, wöchentlich, monatlich).
Schließlich legen Sie den Gesamtzeitraum fest, über den eine Auswertung läuft. Er bestimmt die Größe des Datensatzes. Ein kürzerer Zeitraum hebt subtile Schwankungen stärker hervor, kann aber lokale Maxima überbewerten. Ein längerer Zeitraum liefert mehr Kontext und erfasst normale Schwankungen oder Saisonalitäten besser, ist dafür unter Umständen weniger sensibel.
Datenstichproben aufbereiten
Sind die Datenpunkte definiert, braucht es ein System, das Ihre Cloud-Nutzungsdaten in eine geeignete Struktur überführt – durch Aggregation der Quelldaten gemäß dem gewählten Scope und der Beobachtungsfrequenz.
Analyse starten und Feedback-Loop einrichten
Zur Analyse Ihrer Datenpunkte lassen sich verschiedene Methoden kombinieren: Regeln, Statistik und Modellierung. Ziel der Auswertung ist letztlich, die Wahrscheinlichkeit, dass eine Stichprobe anomal ist, zu quantifizieren oder zu klassifizieren. Zusätzlich können Auswirkung und Dauer einer Anomalie bestimmt werden. Die Genauigkeit des Systems zu beurteilen ist alles andere als trivial, denn sie hängt von Überlegungen und Vorlieben ab, die in jeder Organisation anders ausfallen. Ein Feedback-Loop für kontinuierliche Verbesserungen ist daher unverzichtbar.
Reporting-Strategie festlegen
Definieren Sie eine Reporting-Strategie, die Sie bei Bedarf erreicht, ohne in Alert-Fatigue zu münden. Ein zu sensibles System übersieht zwar selten eine Anomalie, liefert aber bei zu vielen False Positives nicht das gewünschte Ergebnis.
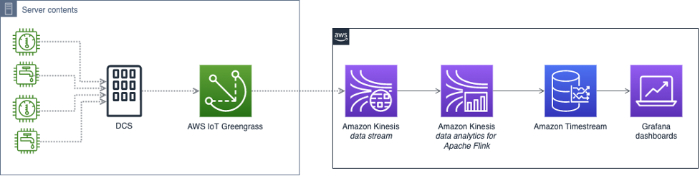
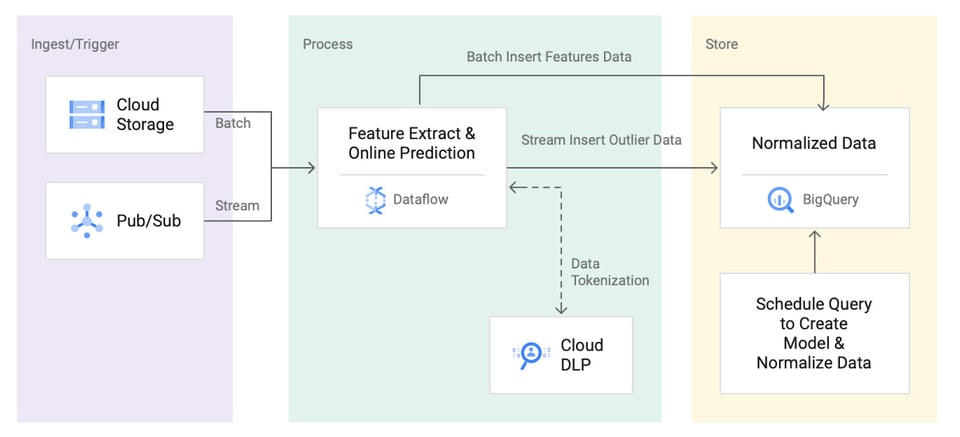
Referenzarchitekturen für Anomaly Detection
Sowohl Google Cloud als auch AWS haben Referenzarchitekturen veröffentlicht, mit denen sich ein Anomaly-Detection-System auf ihren Plattformen aufbauen lässt. Doch selbst nach dem Aufbau ist die Arbeit nicht zu Ende: Das System muss laufend gepflegt und feinjustiert werden.
Wenn Ihnen die Ressourcen fehlen, ein eigenes Anomaly-Detection-System aufzubauen und zu betreiben, gibt es fertige Lösungen wie Anomaly Detection in Cloud Intelligence™, die Kostenspitzen automatisch erkennen – ganz ohne Ihre knappen Engineering-Ressourcen zu binden.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Cloud-Kostenspitzen autonom überwachen mit DoiT Anomaly Detection
Anomaly Detection in Cloud Intelligence™ überwacht kontinuierlich Ihre Abrechnungsdaten und analysiert Ausgabentrends pro Service sowie pro GCP-Projekt bzw. AWS-Konto.
Aus dieser Analyse leitet das System Abrechnungsmuster ab – also seine eigene Definition davon, was für Ihre Cloud-Nutzung "normales Verhalten" bedeutet.
Sie werden anschließend bei jeder Ausgabe alarmiert, die nicht zum prognostizierten Ausgabeverhalten passt.
Das Beste daran: Sie müssen weder konfigurieren noch pflegen.
Anhand verschiedener Parameter passt Anomaly Detection seine Schwellenwerte iterativ an, sobald sich Ihr Ausgabeverhalten verändert.
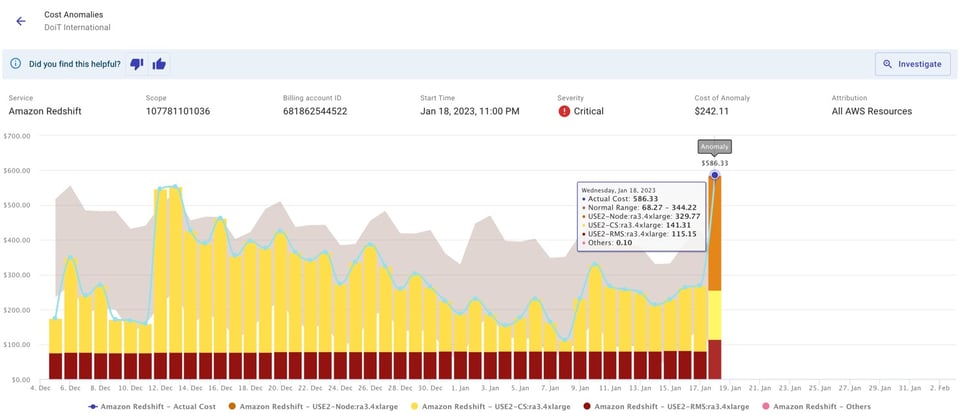
Benachrichtigungen lassen sich per E-Mail oder in einen Team-Slack-Channel einrichten, wie unten zu sehen.
Das fördert den Austausch im Team und stärkt das Verantwortungsgefühl sowie das Bewusstsein für den eigenen Anteil an der Cloud-Rechnung. Vielleicht stellt sich heraus, dass eine Kostenspitze auf Tests Ihres Teams zurückgeht. Möglich, dass Sie von diesen Tests vorher gar nichts wussten – durch den Alert wissen Sie es jetzt. Und selbst wenn hinter einem Alert keine echte unerwartete Spitze steckt, erfahren Sie zumindest etwas Neues darüber, woran Ihr Team gerade arbeitet.
Da Erkennung und Alarmierung von Anomalien automatisiert sind, kann sich Ihr Team auf das Beheben der eigentlichen Ursachen konzentrieren. Ein Klick auf "Investigate" im Alert öffnet einen vorkonfigurierten Report in Cloud Intelligence™ – ein idealer Ausgangspunkt für eine schnelle Ursachenanalyse und Behebung.
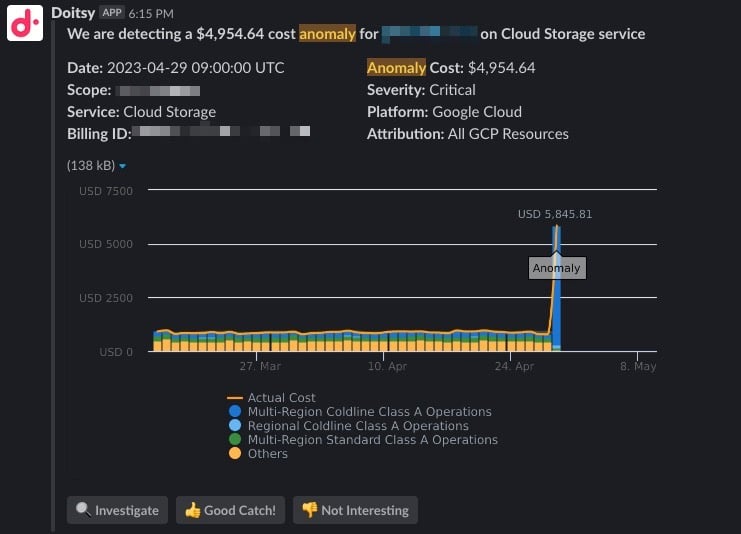
Wenn Sie DoiT-Kunde sind, ist Anomaly Detection in Cloud Intelligence™ ohne weiteres Zutun einsatzbereit. Vom ersten Tag Ihrer Kundenbeziehung an analysiert es Ihre Abrechnungsdaten und löst Alerts aus, sobald eine ungewöhnliche Kostenspitze auftritt.
Noch kein DoiT-Kunde? Starten Sie eine interaktive Tour durch Anomaly Detection oder sprechen Sie mit uns darüber, wie Sie Anomaly Detection und unsere übrigen Produkte für ein besseres Cloud-Management nutzen.