A nadie le gustan las sorpresas en la factura. Detecta picos de costo a tiempo con Anomaly Detection y reduce su impacto y la variabilidad de tu gasto.

Imagina que recibes tu factura mensual de la nube y te encuentras con un aumento del 30% respecto al mes anterior. ¿Cómo pudo pasar? No hubo lanzamientos importantes ni cambios relevantes en la infraestructura durante el último mes. ¿Qué fue lo que ocurrió?
Con tantas piezas en movimiento en la nube, monitorear y detectar picos de costo imprevistos se vuelve todo un desafío. Muchas empresas no cuentan con suficientes recursos de ingeniería para vigilar manualmente los picos de costo y, después, identificar el origen y el alcance del problema cuando aparece.
En este artículo vamos a ver:
- Cómo puedes implementar tu propio sistema de detección de anomalías
- Cómo soluciones listas para usar como Anomaly Detection en Cloud Intelligence™ te permiten monitorear los picos de costo de forma autónoma para que puedas concentrarte en lo que realmente importa.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Por qué conviene configurar el monitoreo de anomalías
Los picos de costo no deseados aparecen de muchas formas: un error en un repositorio de Terraform, un incidente de minería de criptomonedas, servidores que se levantaron y nadie volvió a tocar… la lista no termina.
Las anomalías de costo destruyen la confianza en tus presupuestos y pronósticos, golpean tu burn rate y dificultan entender tus patrones de gasto cloud en general.
A pesar del impacto que esto puede tener en los resultados, muchas empresas esperan a que llegue la factura mensual para reaccionar. Si detectas y atiendes las anomalías a tiempo, cortas el problema de raíz antes de que afecte tu factura cloud y, de paso, vuelves más predecible tu gasto.
El reto está en automatizar la detección y las alertas de picos de costo, porque, como mencionamos antes, muchas empresas no pueden destinar recursos a detectar anomalías de forma manual. Según la encuesta "State of FinOps 2023" de la FinOps Foundation, muchas compañías todavía buscan automatizar las alertas de anomalías.
Cómo construir tu propio sistema de detección de anomalías
Antes de pensar en una herramienta de terceros, quizá te preguntes: "Mmm, ¿cuánto trabajo nos puede dar construir y mantener nuestro propio sistema de monitoreo de anomalías?".
El trabajo que se requiere para implementar y mantener tu propio sistema de detección de anomalías se puede dividir en cuatro pasos:
- Crear un grupo de definición de muestras
- Preparar la muestra de datos
- Iniciar el análisis y montar un ciclo de retroalimentación
- Definir una estrategia de reporte
Crear un grupo de definición de muestras
Antes de empezar cualquier análisis, hay que definir qué se va a monitorear. Esto incluye delimitar el alcance: si vas a observar costo o uso, y a qué nivel de granularidad, ya sea SKU, servicio o un grupo de servicios. Después se establece la frecuencia de observación (por hora, diaria, semanal o mensual).
Por último, hay que definir el período total sobre el que se realiza la evaluación. De ahí depende el tamaño del conjunto de datos. Un período corto tiende a resaltar la volatilidad sutil, con el riesgo de sobreestimar la importancia de los máximos locales; mientras que uno más largo aporta más contexto y captura mejor las fluctuaciones normales o la estacionalidad, con el riesgo de no ser lo suficientemente sensible.
Preparar la muestra de datos
Una vez definida la composición de tus puntos de datos, hay que crear un sistema que transforme los datos de uso de la nube en una estructura adecuada, agregando los datos fuente según el alcance y la frecuencia de observación que elegiste.
Iniciar el análisis y montar un ciclo de retroalimentación
Para analizar tus puntos de datos se puede usar una combinación de métodos: reglas, estadística y modelado. El objetivo final de la evaluación es cuantificar o estratificar la probabilidad de que cada muestra sea anómala. También se puede determinar el impacto y la duración de una anomalía. Determinar la precisión del sistema no es trivial, pues depende de distintas consideraciones y preferencias propias de cada organización. Por eso es esencial contar con un ciclo de retroalimentación que alimente las mejoras continuas.
Definir una estrategia de reporte
Define una estrategia de reporte que capte tu atención cuando sea necesario, sin caer en la fatiga de alertas. A un sistema demasiado sensible quizá no se le escape ninguna anomalía, pero si va acompañado de muchos falsos positivos, no logrará el resultado esperado.
Arquitecturas de referencia para la detección de anomalías
Tanto Google Cloud como AWS han compartido arquitecturas de referencia para construir un sistema de detección de anomalías en sus plataformas. Pero incluso después de construirlo, el trabajo no termina: tendrás que mantenerlo y ajustarlo de forma constante.
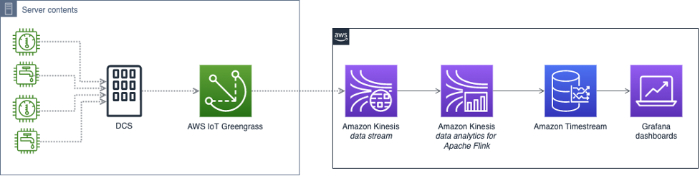
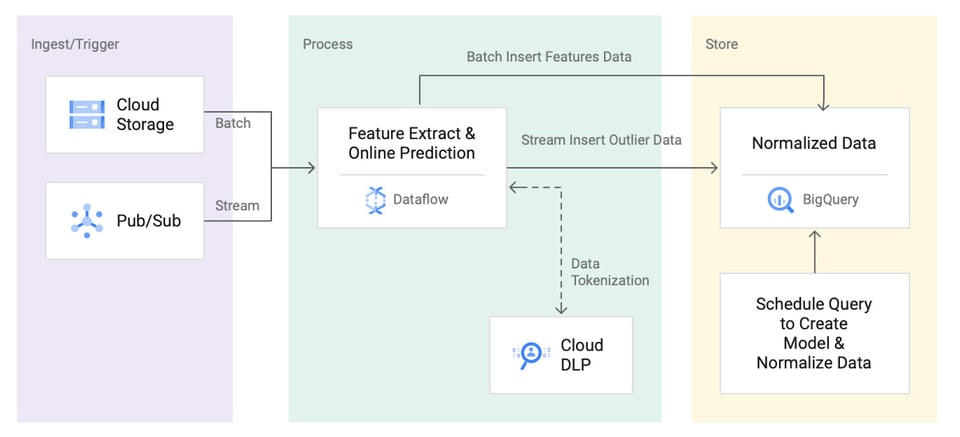
Si no tienes los recursos para construir y mantener tu propio sistema de detección de anomalías, hay soluciones listas para usar como Anomaly Detection en Cloud Intelligence™ que detectan picos de costo de forma automática sin que tengas que destinar tus limitados recursos de ingeniería.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Monitorea picos de costo cloud de forma autónoma con DoiT Anomaly Detection
Anomaly Detection en Cloud Intelligence™ monitorea de forma continua tus datos de facturación y analiza las tendencias de gasto por servicio y por GCP Project/AWS Account.
A partir de ese análisis, define patrones de facturación: su propia interpretación de lo que es un "comportamiento normal" en tu uso de la nube.
A partir de ahí recibes una alerta ante cualquier gasto que no coincida con el comportamiento que Anomaly Detection había pronosticado.
¿Lo mejor? No tienes que configurar ni mantener nada.
A partir de varios parámetros, Anomaly Detection actualiza sus umbrales de forma iterativa conforme cambia tu comportamiento de gasto.
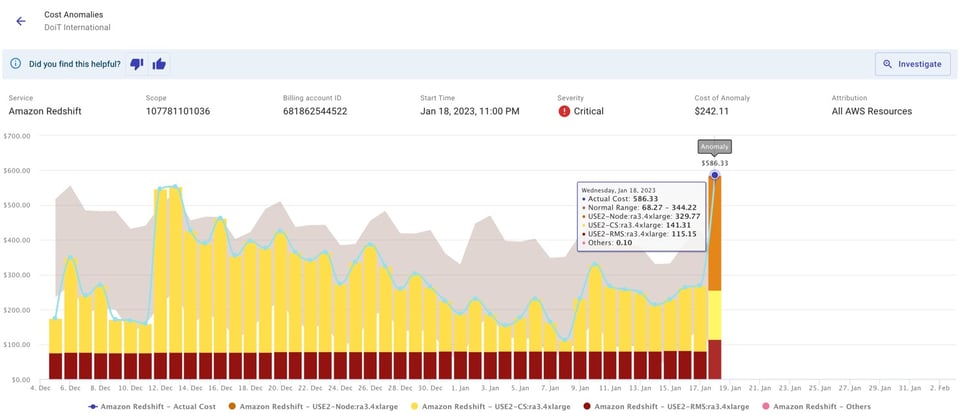
Puedes configurar notificaciones por correo o en un canal de Slack del equipo, como se muestra a continuación.
Esto impulsa conversaciones internas entre tú y tu equipo que aumentan el sentido de responsabilidad y la conciencia sobre tu parte de la factura cloud. Por ejemplo, quizá un pico de costo se debió a unas pruebas que estaba corriendo tu equipo. Puede que antes no lo supieras, pero gracias a esta alerta ahora sí. Aun cuando la alerta no corresponda a un pico realmente imprevisto, igual aprendes algo nuevo sobre lo que está haciendo tu equipo.
Al automatizar la detección y las alertas de anomalías, tu equipo se puede concentrar en resolver los problemas de fondo que las causaron. Basta con hacer clic en "Investigate" dentro de la alerta para abrir un reporte preconfigurado en Cloud Intelligence™, un excelente punto de partida para un análisis rápido de causa raíz y su resolución.
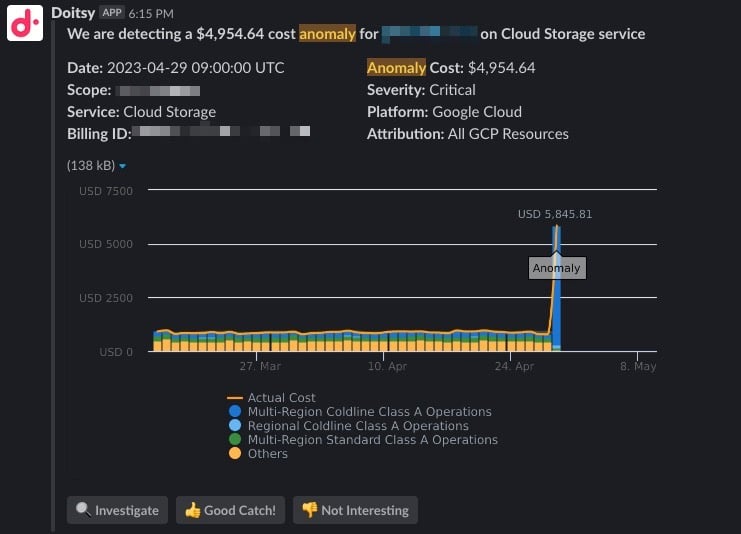
Si ya eres cliente de DoiT, Anomaly Detection viene incluido de fábrica en Cloud Intelligence™. Desde el momento en que te conviertes en cliente, empieza a analizar tus datos de facturación y a generar alertas en cuanto detecta un pico de costo fuera de lo normal.
¿Aún no eres cliente de DoiT? Haz un recorrido interactivo por Anomaly Detection o ponte en contacto con nosotros para conocer cómo aprovechar Anomaly Detection y el resto de nuestros productos para gestionar mejor tu nube.