Ninguém gosta de surpresa na fatura. Identifique picos de custo cedo com Anomaly Detection para reduzir o impacto e a variabilidade do seu gasto.

Imagine que você recebe a fatura mensal da sua nuvem e se depara com um aumento absurdo de 30% em relação ao mês anterior. Como isso aconteceu? Não houve grandes lançamentos de produto nem mudanças significativas na infraestrutura no último mês. O que será que rolou?
Com tanta coisa em movimento na nuvem, fica difícil monitorar e detectar picos de custo inesperados. Muitas empresas têm um time de engenharia enxuto demais para acompanhar esses picos manualmente — e depois identificar a origem e o tamanho do problema, quando ele aparece.
Neste post, vamos falar sobre:
- Como montar seu próprio sistema de detecção de anomalias
- Como soluções prontas como o Anomaly Detection no Cloud Intelligence™ monitoram picos de custo de forma autônoma, para que você foque no que realmente importa.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Por que vale a pena configurar o monitoramento de anomalias
Picos de custo inesperados aparecem das formas mais variadas: um erro num repositório do Terraform, um incidente de mineração de criptomoedas, servidores que subiram e foram esquecidos — a lista não acaba.
As anomalias de custo abalam a confiança nos seus orçamentos e previsões, comprometem o burn rate e dificultam o entendimento dos seus padrões de gasto na nuvem como um todo.
Mesmo com todo esse impacto no resultado, muitas empresas só reagem quando a fatura mensal chega. Detectar e tratar anomalias logo de cara corta o problema pela raiz antes que ele bata pesado na fatura — e, de quebra, deixa o seu gasto na nuvem mais previsível.
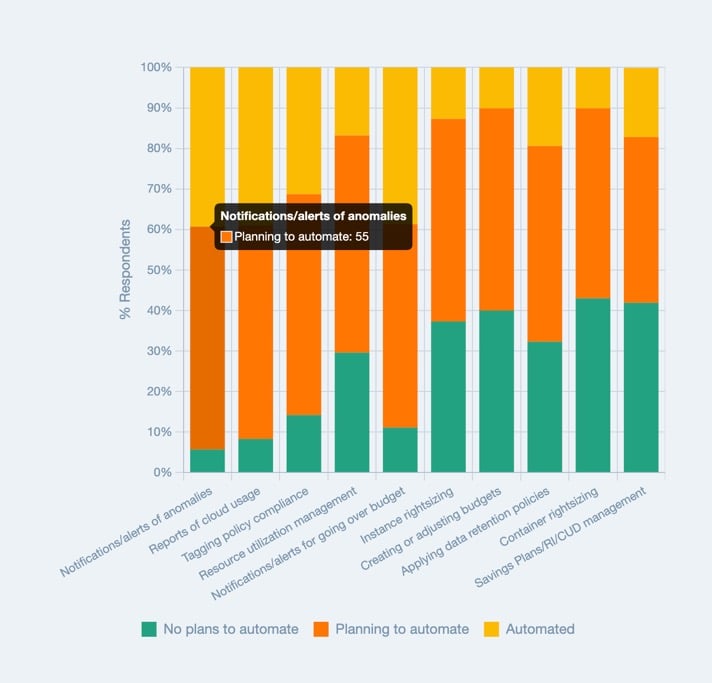
O desafio é automatizar a detecção e o alerta desses picos, porque, como já comentamos, poucas empresas conseguem dedicar gente para caçar anomalias manualmente. Segundo a pesquisa "State of FinOps 2023" da FinOps Foundation, muitas empresas ainda querem automatizar os alertas de anomalias.
Como montar seu próprio sistema de detecção de anomalias
Antes de partir para uma ferramenta de terceiros, talvez você se pergunte: "Hmmm, dá muito trabalho construir e manter o nosso próprio sistema de monitoramento de anomalias?".
O esforço para colocar de pé e manter um sistema próprio de detecção de anomalias pode ser dividido em quatro etapas:
- Criar um grupo de definição da amostra
- Preparar a amostra de dados
- Iniciar a análise e configurar o ciclo de feedback
- Definir uma estratégia de alertas
Criar um grupo de definição da amostra
Antes de qualquer análise, é preciso definir o que você vai monitorar. Isso passa por delimitar o escopo — se vai acompanhar custo ou uso e em que granularidade: por SKU, por serviço ou por um agrupamento de serviços. Depois, defina a frequência de observação (por hora, por dia, por semana, por mês).
Por fim, defina o período total considerado em cada avaliação. Isso determina o tamanho do conjunto de dados. Um período mais curto tende a destacar variações sutis, mas pode superestimar a relevância de máximos locais; já um período mais longo dá mais contexto e captura melhor flutuações normais e sazonalidade, com o risco de ficar pouco sensível.
Preparar a amostra de dados
Definida a composição dos seus pontos de dados, é preciso criar um sistema que transforme os dados de uso da nuvem em uma estrutura adequada, agregando os dados de origem conforme o escopo e a frequência de observação que você escolheu.
Iniciar a análise e configurar o ciclo de feedback
Você pode usar uma combinação de métodos para analisar os pontos de dados, como regras, estatística e modelagem. O objetivo da avaliação é, no fim das contas, quantificar ou estratificar a probabilidade de cada amostra ser anômala. Também dá para determinar o impacto e a duração de uma anomalia. Aferir a precisão do sistema não é trivial, já que depende de critérios e preferências específicos de cada organização. Por isso, um ciclo de feedback que oriente refinamentos contínuos é essencial.
Definir uma estratégia de alertas
Crie uma estratégia de alertas que chame sua atenção quando preciso, sem cair na fadiga de notificações. Um sistema sensível demais pode até não deixar passar nenhuma anomalia, mas, se vier acompanhado de muitos falsos positivos, não vai entregar o resultado esperado.
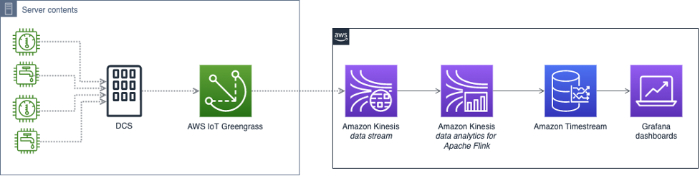
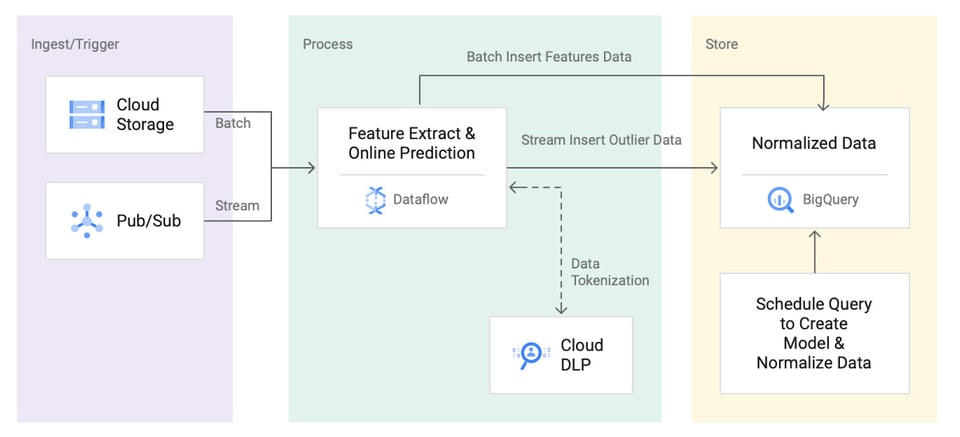
Arquiteturas de referência para detecção de anomalias
Tanto o Google Cloud quanto a AWS publicaram arquiteturas de referência mostrando como construir um sistema de detecção de anomalias em suas plataformas. Mas, mesmo depois de pronto, o trabalho não acaba: você precisa manter e ajustar o sistema o tempo todo.
Se você não tem recursos para construir e manter um sistema próprio de detecção de anomalias, soluções prontas como o Anomaly Detection no Cloud Intelligence™ capturam picos de custo automaticamente, sem consumir o tempo do seu time de engenharia.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Monitore picos de custo na nuvem de forma autônoma com o DoiT Anomaly Detection
O Anomaly Detection no Cloud Intelligence™ monitora seus dados de billing continuamente e analisa as tendências de gasto por serviço e por GCP Project/AWS Account.
A partir dessa análise, ele define padrões de billing — uma definição própria do que é "comportamento normal" para o uso da sua nuvem.
Em seguida, você é avisado sempre que aparecer um gasto fora do comportamento previsto pelo Anomaly Detection.
E o melhor: você não precisa configurar nem manter nada.
Com base em diversos parâmetros, o Anomaly Detection atualiza os limiares de forma iterativa, conforme o seu padrão de gasto muda.
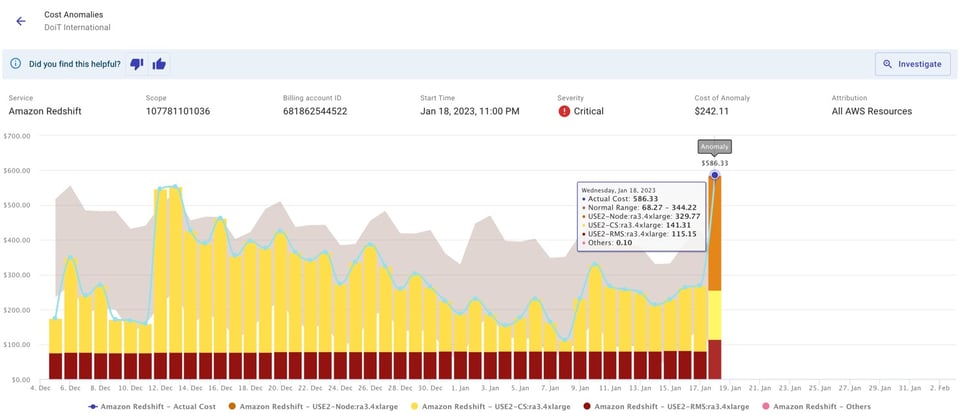
Dá para receber as notificações por e-mail ou em um canal do Slack do time, como no exemplo abaixo.
Isso estimula conversas internas entre você e o time, aumentando o senso de responsabilidade e a consciência sobre a parte de cada um na fatura da nuvem. Por exemplo: talvez um pico de custo tenha vindo de testes que o seu time estava rodando. Você pode não estar a par desses testes antes, mas, graças ao alerta, agora está. Mesmo quando o alerta não aponta um pico inesperado de fato, ainda dá para aprender algo novo sobre o que o seu time anda fazendo.
Ao automatizar a detecção e o alerta de anomalias, seu time consegue focar em resolver a(s) causa(s) raiz que provocaram o problema. Basta clicar em "Investigate" no alerta para abrir um relatório pré-configurado no Cloud Intelligence™ — um ótimo ponto de partida para uma análise rápida da causa raiz e a resolução.
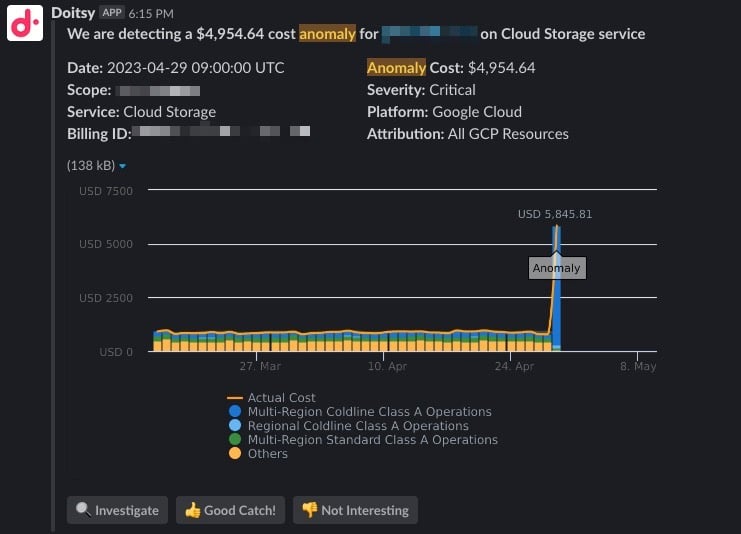
Se você é cliente DoiT, o Anomaly Detection já vem pronto para uso no Cloud Intelligence™. A partir do momento em que você se torna cliente, ele começa a analisar seus dados de billing e gera alertas assim que detecta um pico de custo fora do padrão.
Ainda não é cliente DoiT? Faça um tour interativo pelo Anomaly Detection ou fale com a gente para entender como o Anomaly Detection e o restante dos nossos produtos podem ajudar a gerenciar melhor a sua nuvem.