A nessuno piacciono le sorprese in bolletta. Con Anomaly Detection intercetti per tempo i picchi di costo, ne riduce l'impatto e contiene la variabilità della spesa cloud.

Immagini di ricevere la fattura cloud del mese e di trovarsi davanti a un aumento del 30% rispetto al mese precedente. Com'è potuto accadere? Nessun rilascio importante, nessuna modifica significativa all'infrastruttura. Cosa è andato storto?
Con così tante variabili in gioco nel cloud, monitorare e individuare picchi di costo imprevisti è tutt'altro che semplice. Molte aziende hanno risorse di engineering troppo limitate per presidiare manualmente la spesa, figuriamoci per risalire all'origine e all'estensione del problema quando si presenta.
In questo articolo vedremo:
- Come costruire un proprio sistema di anomaly detection
- Come soluzioni pronte all'uso come Anomaly Detection in Cloud Intelligence™ monitorano in autonomia i picchi di costo, lasciandoLe il tempo di concentrarsi su attività a maggior valore.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Perché serve un monitoraggio delle anomalie
I picchi di costo indesiderati hanno mille volti: un errore in un repository Terraform, un episodio di crypto mining, server avviati e dimenticati. La lista è praticamente infinita.
Le anomalie di costo erodono la fiducia in budget e previsioni, incidono sul burn rate e rendono molto più difficile leggere le dinamiche complessive della spesa cloud.
Eppure, nonostante l'impatto sui conti aziendali, molte realtà aspettano di vedere la fattura mensile prima di muoversi. Rilevare e gestire le anomalie per tempo significa stroncarle sul nascere prima che si traducano in costi reali in bolletta, rendendo così la spesa cloud molto più prevedibile.
La vera sfida è automatizzare rilevamento e notifica dei picchi di costo: come dicevamo, poche aziende possono permettersi di dedicare risorse a un monitoraggio manuale. Secondo l'indagine "State of FinOps 2023" della FinOps Foundation, molte organizzazioni stanno tuttora cercando di automatizzare gli alert sulle anomalie.
Come costruire un sistema di anomaly detection in autonomia
Prima di affidarsi a uno strumento di terze parti, potrebbe chiedersi: "In fondo, quanto può costare costruire e mantenere internamente un sistema di monitoraggio delle anomalie?".
In linea di massima, le attività necessarie per implementare e gestire un proprio sistema di anomaly detection si articolano in quattro fasi:
- Definizione del gruppo di campionamento
- Preparazione del campione di dati
- Avvio dell'analisi e creazione del feedback loop
- Definizione di una strategia di reporting
Definizione del gruppo di campionamento
Prima di iniziare qualsiasi analisi, deve definire l'oggetto del monitoraggio. Significa stabilire il perimetro: monitorare costi o utilizzo, e con quale livello di granularità — SKU, singolo servizio o un raggruppamento di servizi. Andrà poi impostata la frequenza di osservazione (oraria, giornaliera, settimanale, mensile).
Infine, dovrà definire l'arco temporale complessivo su cui condurre la valutazione, che ne determina la dimensione del set di dati. Un periodo più breve tende a far emergere anche le oscillazioni minime, con il rischio di sopravvalutare i massimi locali; un periodo più lungo offre più contesto e coglie meglio fluttuazioni fisiologiche e stagionalità, ma rischia di risultare poco sensibile.
Preparazione del campione di dati
Una volta definita la composizione dei data point, occorre predisporre un sistema che trasformi i dati di utilizzo cloud in una struttura adeguata, aggregando i dati di origine in base al perimetro e alla frequenza di osservazione scelti.
Avvio dell'analisi e creazione del feedback loop
Per analizzare i data point è possibile combinare più approcci: regole, statistica e modellazione. L'obiettivo finale è quantificare o stratificare la probabilità che ciascun campione sia anomalo. È inoltre possibile determinare l'impatto e la durata di un'anomalia. Stabilire l'accuratezza del sistema non è banale, perché dipende da considerazioni e preferenze proprie di ogni organizzazione. Per questo è indispensabile un feedback loop che alimenti un processo di affinamento continuo.
Definizione di una strategia di reporting
Definisca una strategia di reporting capace di catturare la Sua attenzione quando serve davvero, evitando però l'alert fatigue. Un sistema troppo sensibile può anche non lasciarsi sfuggire alcuna anomalia, ma se sommerge il team di falsi positivi non porterà ai risultati attesi.
Architetture di riferimento per l'Anomaly Detection
Sia Google Cloud sia AWS hanno pubblicato architetture di riferimento per costruire un sistema di anomaly detection sulle rispettive piattaforme. Ma la realizzazione è solo l'inizio: il sistema va poi mantenuto e ottimizzato in modo continuativo.
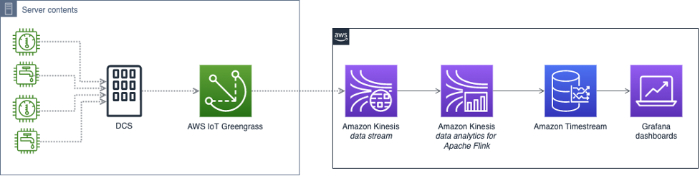
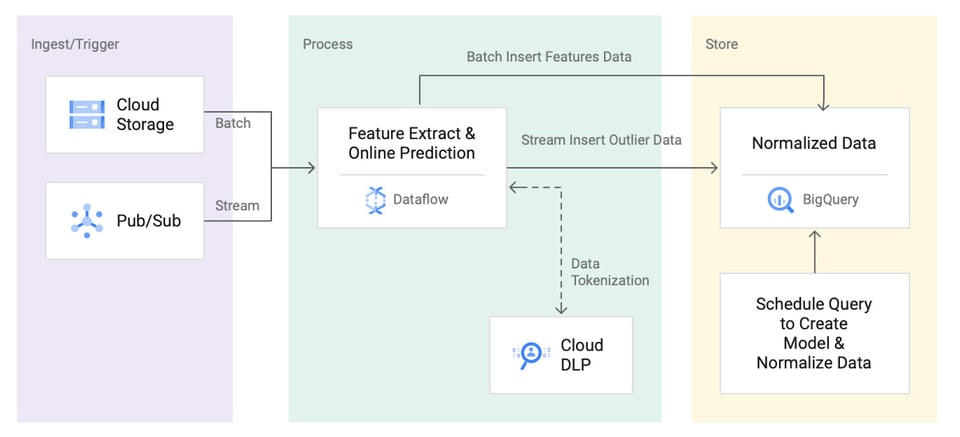
Se non dispone delle risorse per costruire e gestire internamente un sistema di anomaly detection, soluzioni pronte all'uso come Anomaly Detection in Cloud Intelligence™ Le permettono di intercettare in automatico i picchi di costo, senza intaccare le Sue limitate risorse di engineering.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Monitori in autonomia i picchi di spesa cloud con DoiT Anomaly Detection
Anomaly Detection in Cloud Intelligence™ tiene sotto controllo in modo continuativo i Suoi dati di fatturazione e analizza l'andamento della spesa per servizio e per Progetto GCP/Account AWS.
Da questa analisi ricava i pattern di fatturazione, ovvero la propria definizione di "comportamento normale" per il Suo utilizzo cloud.
Riceverà quindi un alert su qualsiasi voce di spesa che si discosti dall'andamento previsto da Anomaly Detection.
La parte migliore? Non c'è nulla da configurare né da mantenere.
Sulla base di una serie di parametri, Anomaly Detection aggiorna iterativamente le proprie soglie man mano che le Sue dinamiche di spesa evolvono.
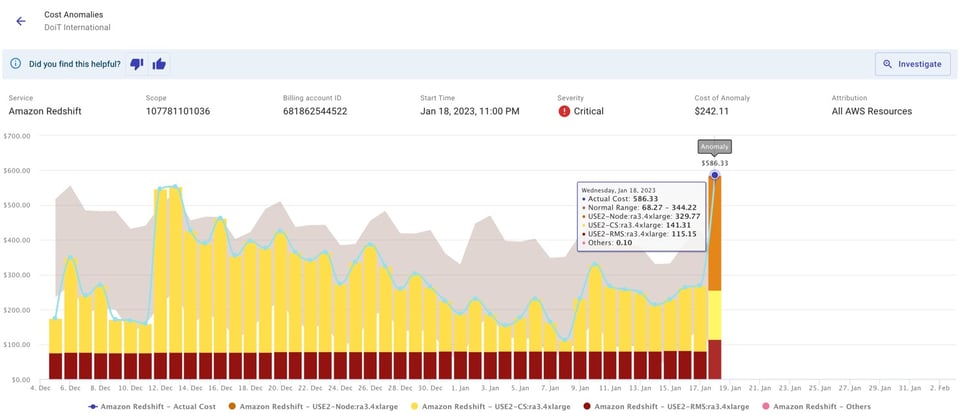
Può scegliere di ricevere le notifiche via email o su un canale Slack del team, come mostrato qui sotto.
È un meccanismo che alimenta il confronto interno con il Suo team, accrescendo il senso di responsabilità e la consapevolezza sulla quota di spesa cloud di ciascuno. Magari un picco di costo è dovuto a dei test che il team sta eseguendo: prima poteva non saperlo, ora grazie all'alert lo sa. Anche quando un alert non segnala un picco realmente imprevisto, è comunque un'occasione per scoprire qualcosa di nuovo su ciò che il team sta facendo.
Automatizzando rilevamento e notifica delle anomalie, il team può dedicarsi a risolvere le cause che le hanno generate. Cliccando su "Investigate" nell'alert si apre un report preconfigurato in Cloud Intelligence™: un ottimo punto di partenza per una rapida root-cause analysis e per chiudere il problema.
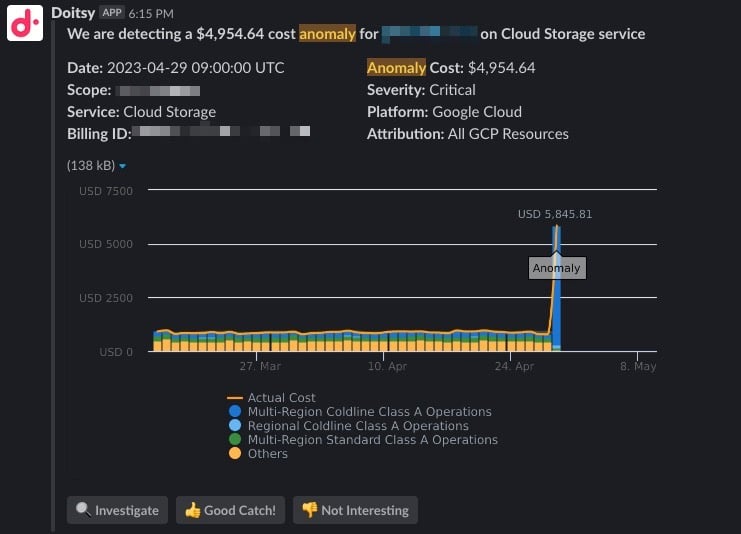
Se è già cliente DoiT, Anomaly Detection è disponibile out-of-the-box in Cloud Intelligence™. Fin dal primo giorno inizia ad analizzare i Suoi dati di fatturazione e a generare alert non appena rileva un picco di costo anomalo.
Non è ancora cliente DoiT? Provi il tour interattivo di Anomaly Detection oppure ci contatti per scoprire come Anomaly Detection e gli altri nostri prodotti possono aiutarLa a gestire al meglio il Suo cloud.