Personne n'aime les mauvaises surprises sur sa facture cloud. Repérez les pics de coûts au plus tôt grâce à Anomaly Detection pour limiter leur impact et la variabilité de vos dépenses.

Imaginez : vous recevez votre facture cloud mensuelle et découvrez une hausse vertigineuse de 30 % par rapport au mois précédent. Comment est-ce possible ? Aucun lancement produit majeur, aucun changement notable d'infrastructure le mois dernier. Que s'est-il passé ?
Avec autant de paramètres mouvants dans le cloud, surveiller et détecter les pics de coûts inattendus relève souvent du casse-tête. De nombreuses entreprises manquent tout simplement de ressources d'ingénierie pour traquer ces pics manuellement, puis en identifier l'origine et l'ampleur lorsqu'ils surviennent.
Au programme de cet article :
- Comment mettre en place votre propre système de détection d'anomalies
- Comment des solutions clés en main comme Anomaly Detection dans Cloud Intelligence™ surveillent les pics de coûts de façon autonome, pour que vous puissiez vous concentrer sur l'essentiel.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Pourquoi mettre en place une surveillance des anomalies
Les pics de coûts imprévus prennent de multiples formes : erreur dans un dépôt Terraform, incident de cryptominage, serveurs lancés puis oubliés — la liste est sans fin.
Les anomalies de coûts sapent la confiance dans vos budgets et prévisions, pèsent sur votre burn rate et compliquent la lecture globale de vos dépenses cloud.
Pourtant, malgré l'impact sur leurs résultats, beaucoup d'entreprises attendent l'arrivée de la facture mensuelle pour réagir. En détectant et en traitant les anomalies tôt, vous étouffez le problème dans l'œuf avant qu'il ne pèse sur votre facture cloud, et vos dépenses deviennent ainsi plus prévisibles.
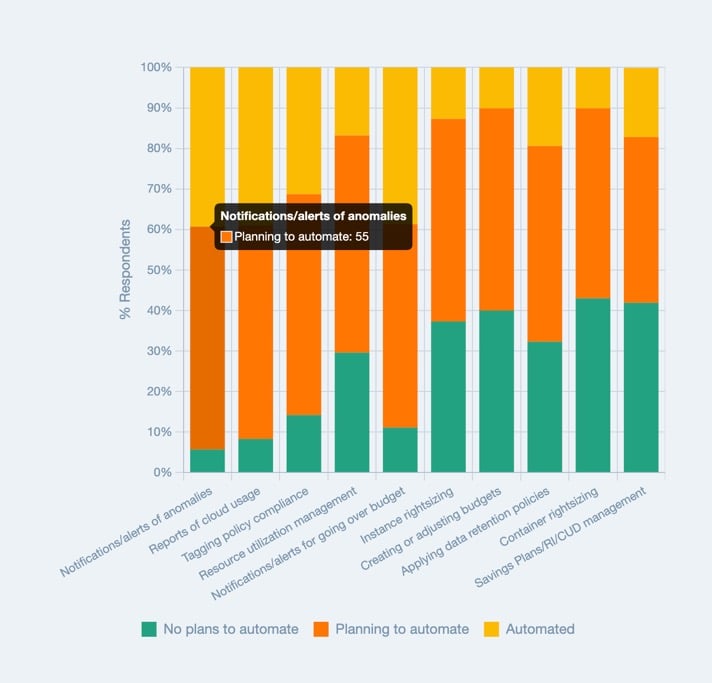
Tout l'enjeu est d'automatiser la détection et l'alerte des pics de coûts : comme évoqué plus haut, peu d'entreprises peuvent se permettre d'y consacrer des ressources manuelles. Selon l'enquête State of FinOps 2023 de la FinOps Foundation, beaucoup d'entreprises cherchent encore à automatiser les alertes d'anomalies.
Comment construire votre propre système de détection d'anomalies
Avant d'envisager un outil tiers, vous vous demandez peut-être : quelle charge de travail représente la conception et la maintenance d'un système de surveillance des anomalies maison ?
La mise en place et la maintenance de votre propre système de détection d'anomalies se décomposent en quatre étapes :
- Créer un groupe de définition d'échantillons
- Préparer les échantillons de données
- Lancer l'analyse et mettre en place une boucle de retour
- Définir une stratégie de reporting
Créer un groupe de définition d'échantillons
Avant toute analyse, définissez ce que vous surveillez. Cela inclut le périmètre — coût ou utilisation, et à quelle granularité : SKU, service ou regroupement de services. Vous devrez ensuite fixer la fréquence d'observation (horaire, quotidienne, hebdomadaire, mensuelle).
Enfin, déterminez la période totale d'évaluation. Elle conditionne la taille du jeu de données. Une période courte tend à mettre en évidence une volatilité subtile, au risque de surévaluer l'importance des maxima locaux, tandis qu'une période plus longue offre davantage de contexte et capture mieux les fluctuations normales ou la saisonnalité, au risque d'une sensibilité insuffisante.
Préparer les échantillons de données
Une fois la composition de vos points de données définie, il faut concevoir un système qui transforme vos données d'utilisation cloud en une structure adaptée, en agrégeant les données sources selon le périmètre et la fréquence d'observation retenus.
Lancer l'analyse et mettre en place une boucle de retour
Plusieurs approches peuvent être combinées pour analyser vos points de données : règles, statistiques et modélisation. L'évaluation vise au final à quantifier ou stratifier la probabilité qu'un échantillon soit anormal. L'impact et la durée d'une anomalie peuvent aussi être déterminés. Mesurer la précision du système n'a rien d'évident, car elle dépend de considérations et de préférences propres à chaque organisation. Une boucle de retour est donc essentielle pour alimenter des ajustements continus.
Définir une stratégie de reporting
Mettez en place une stratégie de reporting qui attire votre attention au bon moment, sans provoquer de fatigue d'alerte. Un système trop sensible laissera peu d'anomalies lui échapper, mais s'il s'accompagne d'un grand nombre de faux positifs, il n'atteindra pas les résultats attendus.
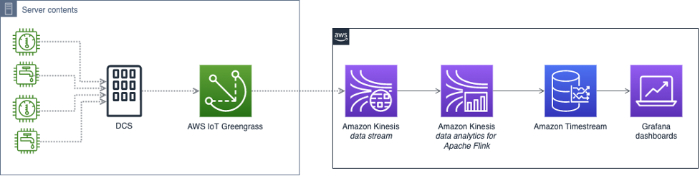
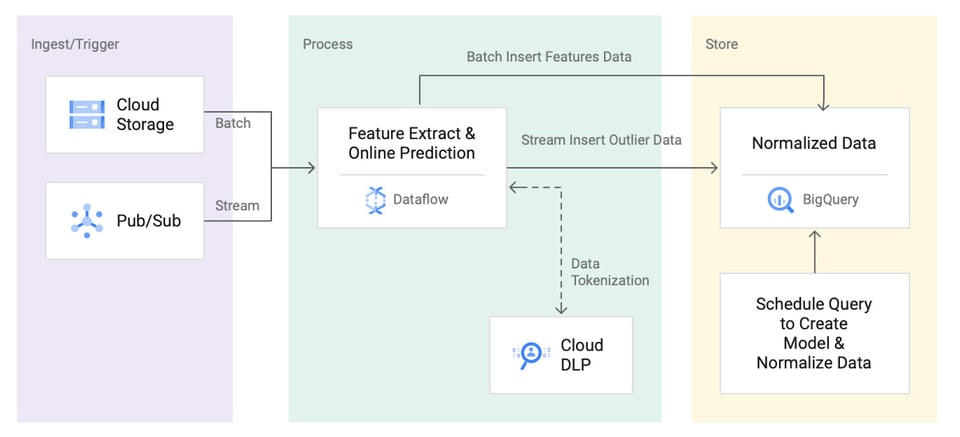
Architectures de référence pour la détection d'anomalies
Google Cloud et AWS ont tous deux publié des architectures de référence pour bâtir un système de détection d'anomalies sur leurs plateformes. Mais une fois le système en place, le travail n'est pas terminé : il faudra l'entretenir et l'ajuster en permanence.
Si vous n'avez pas les ressources pour développer et maintenir votre propre système de détection d'anomalies, des solutions clés en main comme Anomaly Detection dans Cloud Intelligence™ repèrent automatiquement les pics de coûts sans mobiliser vos ressources d'ingénierie déjà limitées.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Surveillez les pics de coûts cloud en toute autonomie avec DoiT Anomaly Detection
Anomaly Detection dans Cloud Intelligence™ surveille en continu vos données de facturation et analyse les tendances de dépenses par service et par projet GCP / compte AWS.
À partir de cette analyse, l'outil dégage des schémas de facturation — sa propre définition d'un comportement normal pour votre utilisation du cloud.
Vous êtes ensuite alerté pour toute dépense qui s'écarte du comportement prévu par Anomaly Detection.
Cerise sur le gâteau : aucune configuration ni maintenance de votre côté.
S'appuyant sur plusieurs paramètres, Anomaly Detection ajuste ses seuils de façon itérative au fil de l'évolution de vos dépenses.
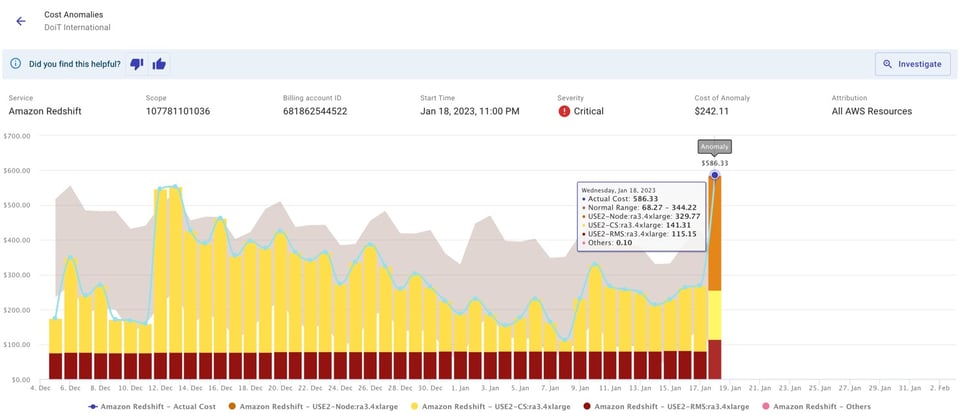
Vous pouvez recevoir les notifications par e-mail ou sur un canal Slack d'équipe, comme illustré ci-dessous.
Ces alertes nourrissent les échanges internes et renforcent le sens des responsabilités ainsi que la visibilité sur votre part de la facture cloud. Un pic de coûts peut par exemple provenir de tests menés par votre équipe : vous n'en aviez peut-être pas connaissance, et l'alerte vous met au courant. Même quand une alerte ne correspond pas à un véritable pic imprévu, elle vous apprend toujours quelque chose sur l'activité de votre équipe.
En automatisant la détection et l'alerte des anomalies, votre équipe peut se consacrer à la résolution des causes sous-jacentes. Un clic sur Investigate dans l'alerte ouvre un rapport préconfiguré dans Cloud Intelligence™ — un excellent point de départ pour identifier rapidement la cause racine et la corriger.
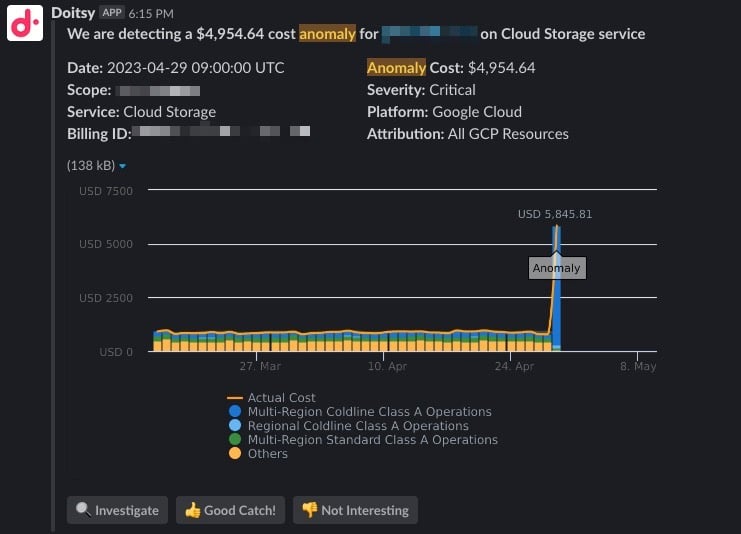
Si vous êtes client DoiT, Anomaly Detection est disponible immédiatement dans Cloud Intelligence™. Dès le premier jour, l'outil analyse vos données de facturation et déclenche des alertes dès qu'un pic de coûts anormal est repéré.
Pas encore client DoiT ? Faites une visite interactive d'Anomaly Detection ou contactez-nous pour découvrir comment Anomaly Detection et le reste de nos produits peuvent vous aider à mieux piloter votre cloud.