
データ処理やAI/MLを担うエフェメラルワークロードは、短命なワークロードが鍵を握る動的なワークフロー型アプリケーションの急速な普及に伴い、その比重を大きく高めています。こうしたプロセスでは、一時的でありながらリソースを多く消費するタスクを処理するために、高いスケーラビリティと柔軟性を備えたコンピューティングリソースが求められます。Kubernetesのpodは設計上、エフェメラルかつイミュータブルであり、この種のアプリケーションと非常に相性が良いと言えます。しかし、DeploymentやDaemonsetといった標準的なKubernetesワークロードの枠を超えると、新たな課題が顔を出し、従来のKubernetesのモデルや戦略では対応しきれないケースも少なくありません。
本記事をご覧の方であれば、動的なK8s環境の運用で苦労した経験や、次のような疑問を抱いた経験があるのではないでしょうか。
- 過剰プロビジョニングやリソース不足のリスクを抱え込まずに、エフェメラルワークロードを効率よく運用できているか?
- パフォーマンスとリソース使用状況を的確に追跡できるよう、モニタリングは適切に構成できているか?
- 1と2が「Yes」だとして、それを信頼できるデータで裏付ける手段はあるか?
本記事では、エフェメラルワークロードを掘り下げ、直面しがちな課題と、それを解決するための実践的な戦略をご紹介します。
「エフェメラルワークロード」とは
すでに触れたとおり、Kubernetesのpodは(StatefulSetに属するものを除き)すべて本質的にエフェメラルです。ただし、ここで言うエフェメラルワークロードとは、(比較的)短命でステートレスなタスクのうち、リソースを動的に使用し、JobやCronJobといった標準APIリソースに紐付かないものを指します。具体的には、Knative、Airflow Kubernetes Executor、Spark Operatorなどのカスタムコントローラーが生成するスタンドアロンのpodや、GitlabやJenkinsからトリガーされるCI/CD実行用のpodなどです。これらのpodは必要なときだけ稼働し、処理が終われば自動的に終了するため、動的な環境にうってつけです。
このようなワークロードのオーケストレーションは、データやAIパイプラインで動的かつ短命なプロセスを扱うために欠かせません。ビッグデータ処理や、モデル学習をはじめとする機械学習タスクの管理にも有効です。つまりこれらのワークロードは、複雑で一時的、かつリソース集約的な処理をより効率的に扱うための柔軟性とスケーラビリティをもたらしてくれるわけです。
とはいえ、あなたの動的なワークロードは、本当に効率よく動いているでしょうか。
なぜエフェメラルワークロードはコストを押し上げるのか
AI/MLアプリケーションを稼働させていると、思わぬコスト急増に見舞われることがあります。とりわけ、需要に合わせて常時スケーリングするエフェメラル(短命な)ワークロードでは、こうした事態が不意打ちのように襲ってきがちです。アプリのスケールアップが速すぎても遅すぎても、リソースを効果的に使うのは頭の痛い問題です。エフェメラルワークロードがコストを押し上げる理由を理解することが、クラウド支出をコントロールし、ひいては効率を高めるための第一歩となります。
私たちはこうした事例を詳しく分析し、一見効率的に見えるソリューションが、実は大きなクラウドの無駄を生む元凶へと変わってしまう主な理由をいくつか突き止めました。
まず多くのお客様が、リソース使用状況のリアルタイム把握に苦労されていることが分かりました。エフェメラルワークロードは動的な性質ゆえに、いつ稼働するのか、どれだけのリソースを消費するのかが読みにくいためです。可視性が欠ければ、需要のピーク時には過剰プロビジョニング、需要の少ない時間帯には低稼働という状態を招き、コストの無駄につながります。これらのワークロードは細かく分散し、必要に応じて起動されるため、従来のモニタリング手法はもはや通用せず、多くの場合チームに見えているのは氷山の一角にすぎません。
もう一つ、ピーク時の動的なワークロードや需要を十分に把握できていないことに起因する、ある種の「保険的な選択」も非効率の温床になっていることが分かりました。繁忙期のパフォーマンスを担保するために過剰プロビジョニングを行い、結果としてワークロードがリソースを使い切らない――というのは典型例です。
そして最後に、エフェメラルワークロードがタスクを終えてもメモリやCPUといったリソースを占有し続け、十分に活用されないまま無駄なコストへと変わってしまうケースもあります。未使用リソースを素早くスケールダウンする自動化がなければ、価値を生まないままコストだけが膨らんでいきます。
K8sのコストではなく、効率を伸ばす
課題が明確になれば、解決すべきポイントも自ずと定まり、それらを網羅できる最適なソリューションの必要性が浮き彫りになります。こうした既存の課題を出発点に、PerfectScale by DoiTから、エフェメラルワークロードを自律的にライトサイジングする独自のアプローチをご紹介できることを大変嬉しく思います。
PerfectScaleの自動化は、動的で複雑な環境においても、K8sワークロードの最適化を手間なく実現します。未使用キャパシティを排除してクラウドコストを大幅に削減しながら、レイテンシーやボトルネックを生じさせずにピークパフォーマンスを維持します。
SparkJobs、Airflow、Temporalなどのエフェメラルワークロードの最適化は、わずか2ステップで始められます。
ステップ1:エフェメラルワークロードをグルーピングする
PerfectScaleは、動的なワークロードをグルーピングするための高度なインテリジェンスを備えています。一過性のエンティティに対するデータ集約が容易になり、可視性と分析力が高まり、実用的なデータポイントをもとに重要な点へ集中でき、最終的にはクラウド支出の削減につながります。やるべきことは、ワークロードに必要なラベルを付けるだけ。あとはPerfectScaleがすべて自動で処理します。
Labels:app: spark-job-over-hriautomation.perfectscale.io/generatedFrom: 53836ca7perfectscale.io/workload-grouping-honor-image: "true"perfectscale.io/workload-grouping-honor-spec: "true"perfectscale.io/workload-grouping-workload-name: spark-job-over-hriperfectscale.io/workload-grouping-workload-type: CustomSparkJobたとえばCustom_SparkJobタイプとしてワークロードがグルーピングされれば、混沌としたデータのノイズに振り回されず、その予測しづらさを抑えながら、エフェメラルワークロードをより効果的に管理できます。さらに次のステップへ進めば、プロセス全体を完全に自動化し、すぐに成果を得ることも可能です。
ステップ2:柔軟な自動化を構成する
これで、最適化フローの完全自動化まであと一歩です。残るは、Custom_SparkJobワークロードに対する自動化の構成だけ。この段階で、PerfectScaleはCustom Resource(CR)を介して適用できる、高度にカスタマイズ可能な自動化構成オプションを多数用意しています。
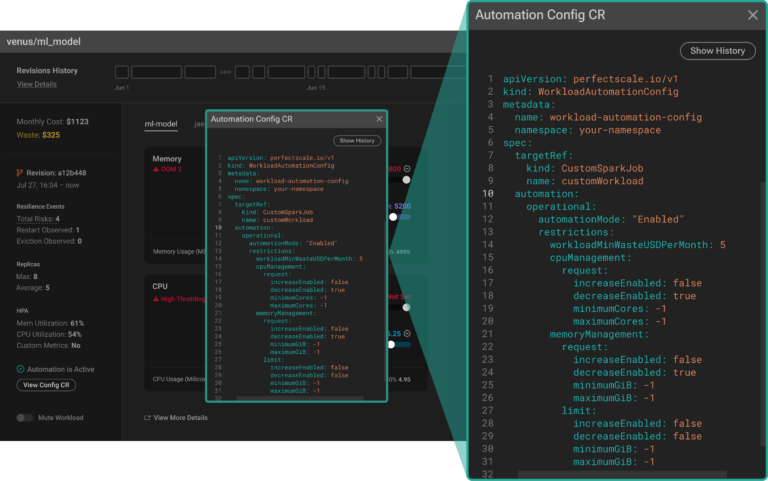
このアプローチには柔軟性があり、自動化を細かく構成できるため、特定のユースケースやアプリケーションの運用要件に合わせて容易に調整できます。
さらに、AIを活用したアルゴリズムと高度な分析が、過去のデータをもとにワークロードのパターン予測を高精度化し、リソース割り当てを最適化します。
この機能はどう活かせるのか
ユースケース1:Airflow Kubernetes Executor
Apache Airflow®は、データパイプラインとMLワークフローのオーケストレーションにおける主要なオープンソースプラットフォームです。Airflowは、個々のタスクで構成される有向非巡回グラフ(DAG)としてワークフローを管理します。AirflowのKubernetes executorを使えば、各タスクインスタンスをKubernetesクラスター上の専用podで実行できます。
DAGがタスクを送出すると、Kubernetes executorはKubernetes APIにワーカーpodをリクエストします。ワーカーpodはタスクを実行し、結果を報告したうえで終了します。
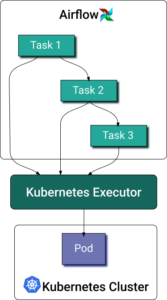
他のpodと同様、PythonベースのAirflowタスクのリソース割り当ては一筋縄ではいきません。大量のデータを読み込むためにより多くのメモリが必要なものもあれば、複雑な計算でCPU負荷が高いものもあります。データ処理タスクは動的な性質を持つため、コンテナのリソースリクエストとリミットを事前に定義するのは困難です。実際、ほとんどのデータエンジニアは定義しないことを選ぶでしょう。Airflow Kubernetes Executor公式ドキュメントの例を見ても、リソース仕様を含むものは一つもありません。一方で、Airflowワーカーpodはエフェメラルなため、計測そのものも難しいのが実情です。
Airflowワーカーのリソース割り当てを管理する唯一の方法は、共通のプロパティ(たとえばpodラベル)でグルーピングし、クラスター内に生成されるタイミングでリソースリクエストとリミットを自動設定することです。
こうすれば、過去のpodのメトリクスをもとにした推奨値を取得し、Airflowが新たに作成するpodへ適用できます。幸い、PerfectScaleの新機能であるグルーピングされたワークロードの自動化は、まさにこれを手間なく実現するためのものです。
ユースケース2:Spark OperatorのSpark DriverとExecutor Pod
Kubernetes Operator for Apache Sparkは、Sparkアプリケーションの定義と実行を、Kubernetes上で他のワークロードを動かすのと同じくらい簡単で自然な体験にすることを目指しています。Kubernetesのカスタムリソースを使って、Sparkアプリケーションの定義・実行・ステータスの可視化を行います。
SparkApplicationカスタムリソースが作成または更新されるたびに、Sparkコントローラーがウォッチイベントに反応し、Spark driverおよびexecutor podを生成します。
各コンポーネントがどう連携して動作するかを、次の図で確認してみましょう。
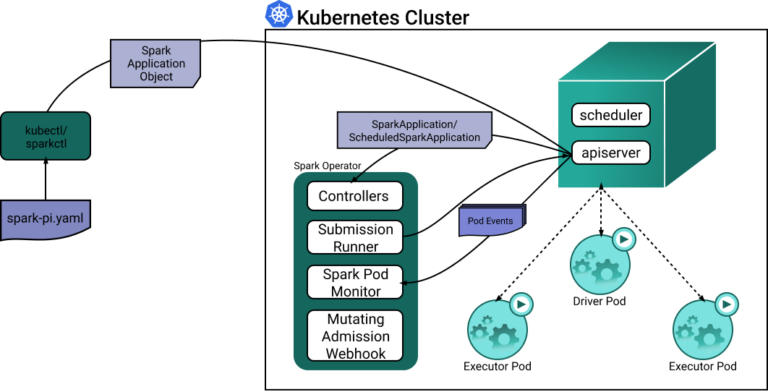
Spark driver podのリソース消費は比較的均一ですが、executor podは動的なペイロードを処理するため、静的な構成のままでは大きく非効率になりかねません。Spark operatorによるexecutor podのリソース割り当て構成例を以下に示します。
```spec:
executor:
cores: 1
instances: 3
memory: 512m
labels:
version: 3.1.1
serviceAccount: sparkご覧のとおり、設定できるのはリクエストのみでリミットは設定できず、定義は静的です。エフェメラルなSparkワークロードに適切なリソース量を割り当てるには、まずexecutor podへのリソース割り当てをスキップし、PerfectScale上で次のようなラベルを付けてグルーピングします。perfectscale.io/workload-grouping-workload-name=SparkJobName perfectscale.io/workload-grouping-workload-type=SparkJob perfectscale.io/workload-grouping-honor-image=true perfectscale.io/workload-grouping-honor-spec=true
あとは、operatorがexecutorを生成するたびにリソースを設定する自動化を、シームレスに有効化できます。
### ユースケース3:Jenkins Jobs
[Jenkins Kubernetesプラグイン](https://plugins.jenkins.io/kubernetes/)を使うと、Kubernetes上で動作するJenkinsエージェントをスケーリングできます。プラグインは起動するエージェントごとにKubernetes Podを作成し、各ビルドの完了後に停止します。
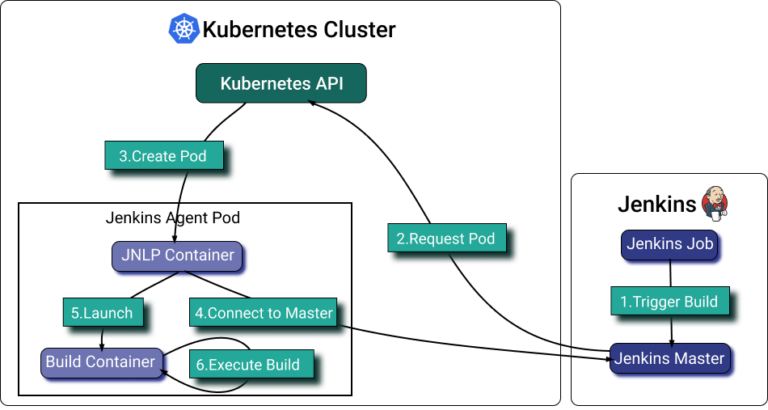
Jenkinsのpodテンプレートではコンテナ単位でリソース割り当てを設定できますが、最適値を見極めるのは至難の業です。そこでpodラベルを設定し、関連するJenkinsエージェントpodをまとめてPerfectScaleでグルーピングし、実際の利用状況に応じてリソース割り当てを自動化するのが有効です。
結論として、動的なAI/MLアプリケーションの運用・スケーリング・最適化は決して容易ではありません。チームにとって大きな負担となり、思うような成果が得られないこともあります。しかし、適切なツールと戦略があれば、これらのプロセスを次のステージへ引き上げ、目標を確実に達成できると私たちは考えています。
詳しくは[ドキュメント](https://docs.perfectscale.io/enable-automation/including-a-cluster-namespace-or-workload-to-the-automation/configuring-automation-for-a-workload#automating-ephemeral-workloads)をご覧いただくか、私たちのチームと[テクニカルセッション](https://www.google.com/url?q=https://scheduler.zoom.us/sales-team-waw79l/perfectscale-demo?utm_source%3Ddoit%26utm_medium%3Dreferral%26utm_campaign%3Dephemeral-workloads&sa=D&source=docs&ust=1739899468357789&usg=AOvVaw3gNIv-ajT49B_9OHclBxUs)をご予約のうえ、本機能の活用方法をぜひお確かめください。
まだPerfectScale by DoiTをお使いでない方は、[今すぐ無料で始める](https://www.perfectscale.io/?utm_source=doit&utm_medium=referral&utm_campaign=ephemeral-workloads)!